

 新火種
2024-12-24
新火種
2024-12-24 


讓多視角圖像生成更輕松!北航和VAST推出MV-Adapter

AIxiv專欄是機器之心發(fā)布學(xué)術(shù)、技術(shù)內(nèi)容的欄目。過去數(shù)年,機器之心AIxiv專欄接收報道了2000多篇內(nèi)容,覆蓋全球各大高校與企業(yè)的頂級實驗室,有效促進了學(xué)術(shù)交流與傳播。如果您有優(yōu)秀的工作想要分享,歡迎投稿或者聯(lián)系報道。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文的主要作者來自北京航空航天大學(xué)、VAST 和上海交通大學(xué)。本文的第一作者為北京航空航天大學(xué)碩士生黃澤桓,主要研究方向為生成式人工智能和三維視覺。本文的通訊作者為 VAST 首席科學(xué)家曹炎培和北京航空航天大學(xué)副教授盛律。
最近,2D/3D 內(nèi)容創(chuàng)作、世界模型(World Models)似乎成為 AI 領(lǐng)域的熱門關(guān)鍵詞。作為計算機視覺的基礎(chǔ)任務(wù)之一,多視角圖像生成是上述熱點方向的技術(shù)基礎(chǔ),在 3D 場景生成、虛擬現(xiàn)實、具身感知與仿真、自動駕駛等領(lǐng)域展現(xiàn)了廣泛的應(yīng)用潛力。
近期多視角圖像生成工作大多在 3D 數(shù)據(jù)集上微調(diào)文生圖模型或視頻生成模型,但這些方法在兼容大規(guī)模基礎(chǔ)模型和生成高分辨率圖像方面面臨諸多挑戰(zhàn),表現(xiàn)在難以支持更大基礎(chǔ)模型(如 SDXL),難以生成超過 512 分辨率的多視角圖像,以及高質(zhì)量 3D 訓(xùn)練數(shù)據(jù)稀缺而導(dǎo)致的出圖質(zhì)量下降。總的來說,這些方法的局限性主要源自對基礎(chǔ)模型的侵入性修改和全模型微調(diào)的復(fù)雜性。
因此,北航、VAST、上海交通大學(xué)團隊推出面向通用多視圖生成任務(wù)的第一個基于 Adapter 的解決方案(MV-Adapter)。通過高效的新型注意力架構(gòu)和統(tǒng)一的條件編碼器,MV-Adapter 在避免訓(xùn)練圖像基礎(chǔ)模型的前提下,實現(xiàn)了對多視圖一致性和參考圖像主體相關(guān)性的高效建模,并同時支持對視角條件和幾何條件的編碼。
總結(jié)來說,MV-Adapter 的功能如下:
支持生成 768 分辨率的多視角圖像(目前最高)
完美適配定制的文生圖模型、潛在一致性模型(LCM)、ControlNet 插件等,實現(xiàn)多視圖可控生成
支持文生和圖生多視圖(而后重建 3D 模型),或以已知幾何引導(dǎo)來生成高質(zhì)量 3D 貼圖
實現(xiàn)任意視角生成

論文題目:MV-Adapter: Multi-view Consistent Image Generation Made Easy
論文鏈接:https://arxiv.org/abs/2412.03632
項目主頁:https://huanngzh.github.io/MV-Adapter-Page/
代碼倉庫:https://github.com/huanngzh/MV-Adapter
在線 Demo:
單圖生成多視圖:https://huggingface.co/spaces/VAST-AI/MV-Adapter-I2MV-SDXL
文字生成二次元風(fēng)格的多視圖:https://huggingface.co/spaces/huanngzh/MV-Adapter-T2MV-Anime
貼圖 Demo 敬請期待
MV-Adapter 效果演示
在了解 MV-Adapter 技術(shù)細節(jié)前,先來看看它的實際表現(xiàn)。
首先是文字生成多視角圖像的能力。MV-Adapter 不僅支持訓(xùn)練時所采用的 SDXL 基礎(chǔ)模型,還能適配經(jīng)過定制訓(xùn)練后的文生圖模型(例如二次元等風(fēng)格模型)、潛在一致性模型(LCM)、ControlNet 插件等,大大提升了多視圖生成的可控性和定制化程度,這是以往多視圖生成模型難以做到的。

MV-Adapter 還能支持單張圖像到多視角圖像的生成,其生成的結(jié)果與輸入圖像具有高度的 ID 一致性。

下面是使用 MV-Adapter 從文字生成的多視角圖像重建 3D 物體的結(jié)果,可以看到,因為 MV-Adapter 生成圖像的多視角一致性高,其重建的幾何結(jié)果也都較為出色。

下面是使用 MV-Adapter 從單張圖像生成多視角圖像后,重建 3D 物體的結(jié)果。

此外,MV-Adapter 還支持給已知 mesh 幾何生成對應(yīng)貼圖,下面是從文字條件和單張圖像條件生成的 3D 貼圖結(jié)果,可以看到,其生成的貼圖結(jié)果質(zhì)量很高,且和輸入的條件匹配程度高。

MV-Adapter 還能輕易擴展至任意視角生成,下面是生成 40 個俯仰角從低到高的結(jié)果,可以看到,盡管視角數(shù)量提升,MV-Adapter 仍能生成多視角一致的圖像。
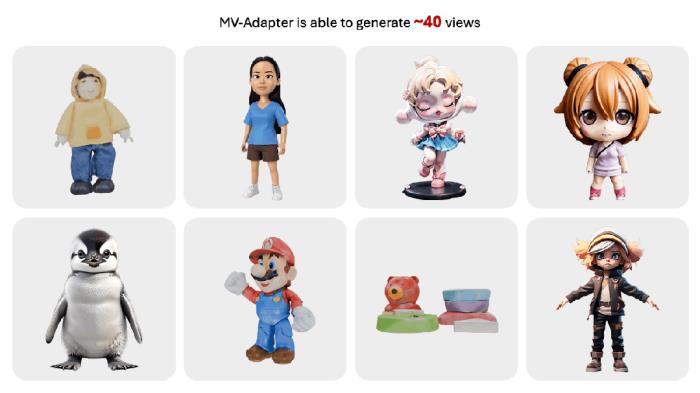
整體而言,MV-Adapter 做出了以下貢獻:
提出了面向通用多視圖生成的第一個適配器解決方案,大大提高效率,且支持更大尺度的基礎(chǔ)模型以獲得更高的性能。
引入了一個創(chuàng)新的注意力架構(gòu)和通用的條件編碼器,可以有效地對 3D 幾何知識進行建模,并支持 3D 生成和紋理生成等多種應(yīng)用。
MV-Adapter 可以擴展至從任意視點生成圖像,從而促進更廣泛的下游任務(wù)。
MV-Adapter 提供了一個解耦學(xué)習(xí)框架,為建模新類型的知識(例如物理或時序知識)提供了見解。
多視圖適配器 MV-Adapter
MV-Adapter 是一種即插即用的適配器,它可學(xué)習(xí)多視圖先驗,無需進行特定調(diào)整即可將其遷移到文生圖模型及其衍生模型中,使其在各種條件下生成多視圖一致的圖像。在推理時,我們的 MV-Adapter 包含條件引導(dǎo)器和解耦的注意層,可以直接插入定制化的基礎(chǔ)模型中,以構(gòu)成多視圖生成器。
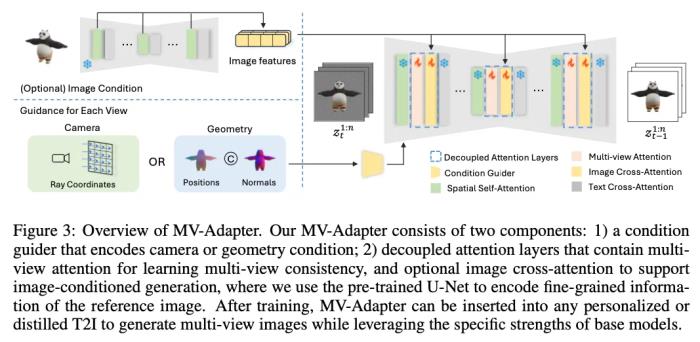
通用的條件引導(dǎo)器
為了支持多視角圖像生成任務(wù),我們設(shè)計了一個通用的條件引導(dǎo)器,能夠同時編碼相機和幾何信息,從而為文生圖模型提供不同類型的引導(dǎo)。相機條件化采用 “光線圖”(raymap)表示,相機的位置和方向信息被精確編碼,以便與預(yù)訓(xùn)練模型的潛在表示相匹配。幾何條件化則通過全局的幾何表示來引導(dǎo)生成,結(jié)合三維位置圖和法線圖的細節(jié)信息,捕捉物體的幾何特征,有助于提高圖像的紋理細節(jié)與真實感。條件引導(dǎo)器采用輕量級的卷積網(wǎng)絡(luò)設(shè)計,有效整合不同尺度的多視角信息,確保模型能夠在多個層級上無縫結(jié)合條件輸入,進一步提升生成效果和適應(yīng)性。
解耦的注意力層
我們提出了一種解耦的注意力機制,通過復(fù)制現(xiàn)有的空間自注意力層來引入新的多視角注意力層和圖像交叉注意力層。這一設(shè)計保留了原始網(wǎng)絡(luò)結(jié)構(gòu)和特征空間,避免了傳統(tǒng)方法對基礎(chǔ)模型進行侵入式修改。在過去的研究中,為了建模多視角一致性,通常會直接修改自注意力層,這會干擾到模型的學(xué)習(xí)先驗并需要進行全模型微調(diào)。而我們通過復(fù)制原有自注意力層的結(jié)構(gòu)與權(quán)重,并將新層的輸出投影初始化為零,從而確保新層可以獨立學(xué)習(xí)幾何信息,而不會影響原有模型的特征空間。這樣一來,模型能夠在不破壞原有預(yù)訓(xùn)練特征的前提下,充分利用幾何信息,提升多視角生成的效果。
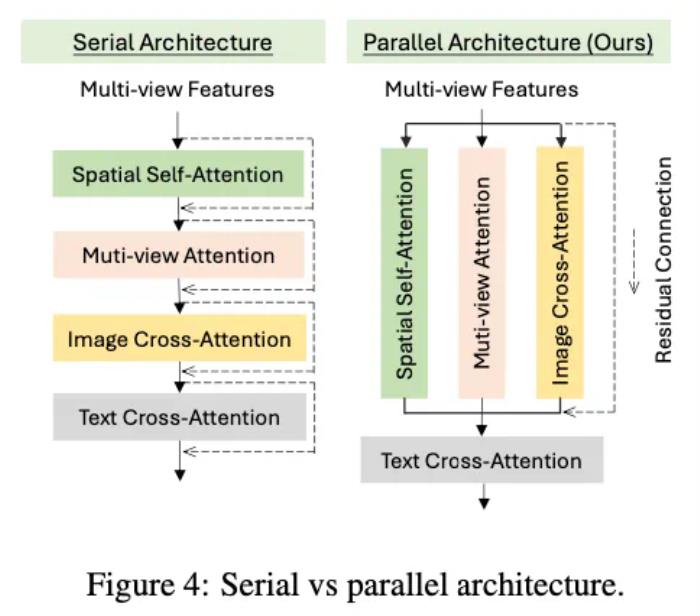
為了更高效地整合不同類型的注意力層,我們設(shè)計了一種并行的注意力架構(gòu)。在傳統(tǒng)的 T2I 模型中,空間自注意力層與文本交叉注意力層通過殘差連接串聯(lián)在一起,而我們的設(shè)計則將多視角注意力層與圖像交叉注意力層并行添加。這種并行架構(gòu)確保了新引入的注意力層能夠與預(yù)訓(xùn)練的自注意力層共享輸入特征,從而充分繼承原始模型的圖像先驗信息。具體來說,輸入特征在經(jīng)過自注意力層后,還會同時傳遞給多視角注意力和圖像交叉注意力層,允許這些新層與原始自注意力層并行工作,并在學(xué)習(xí)多視角一致性和圖像條件生成時,無需從零開始學(xué)習(xí)。通過這種方式,我們能夠在不破壞基礎(chǔ)模型特征空間的前提下,高效地擴展模型的能力,提升生成質(zhì)量和多視角一致性。
多視角注意力機制的具體實現(xiàn)。為了滿足不同應(yīng)用需求,我們設(shè)計了多種多視角注意力策略。針對 3D 物體生成,我們使模型能夠生成位于 0° 仰角的多視角圖像,并采用行級自注意力。對于 3D 紋理生成,考慮到視角覆蓋要求,除了在 0° 仰角生成四個均勻分布的視角外,我們還加入了來自上下方向的兩個視角。通過行級和列級自注意力相結(jié)合,實現(xiàn)了視角之間信息的高效交換。而在任意視角生成任務(wù)中,我們則采用全自注意力,進一步提升了多視角注意力層的靈活性和表現(xiàn)力。這樣的設(shè)計使得生成效果更加精細、豐富,適應(yīng)了各種復(fù)雜的多視角生成需求。
圖像交叉注意力機制的具體實現(xiàn)。為了在生成過程中更精確地引導(dǎo)參考圖像信息,我們提出了一種創(chuàng)新的圖像交叉注意力機制,在不改變原始 T2I 模型特征空間的情況下,充分利用參考圖像的細節(jié)信息。具體而言,我們采用預(yù)訓(xùn)練且被凍結(jié)的文生圖 U-Net 模型作為圖像編碼器,將清晰的參考圖像輸入該 U-Net,并設(shè)置時間步 t=0,提取來自空間自注意力層的多尺度特征。這些細粒度的特征包含了豐富的主題信息,通過解耦的圖像交叉注意力層注入到去噪 U-Net 中,從而利用預(yù)訓(xùn)練模型學(xué)到的深層表示,實現(xiàn)對生成內(nèi)容的精準(zhǔn)控制。這一方法有效提升了生成質(zhì)量,并使得模型在細節(jié)控制上更加靈活和精確。
實驗結(jié)果
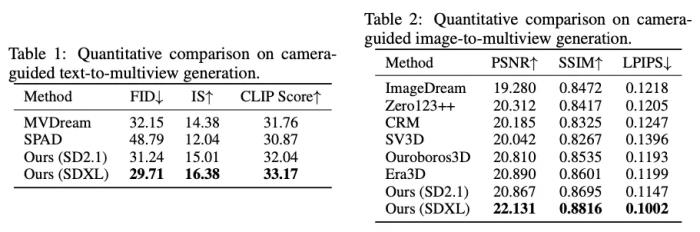
文章首先評估了多視圖生成的性能,與現(xiàn)有方法進行對比。具體來說,文章評估了由文字生成多視圖、由單張圖像生成的多視圖的質(zhì)量和一致性,可以看到,MV-Adapter 的結(jié)果都優(yōu)于現(xiàn)存方法。
文章還評估了使用 MV-Adapter 生成 3D 貼圖的表現(xiàn)。從下面的結(jié)果可以看出,MV-Adapter 不管是生成的質(zhì)量,還是推理的速度,都達到 SOTA 水平。
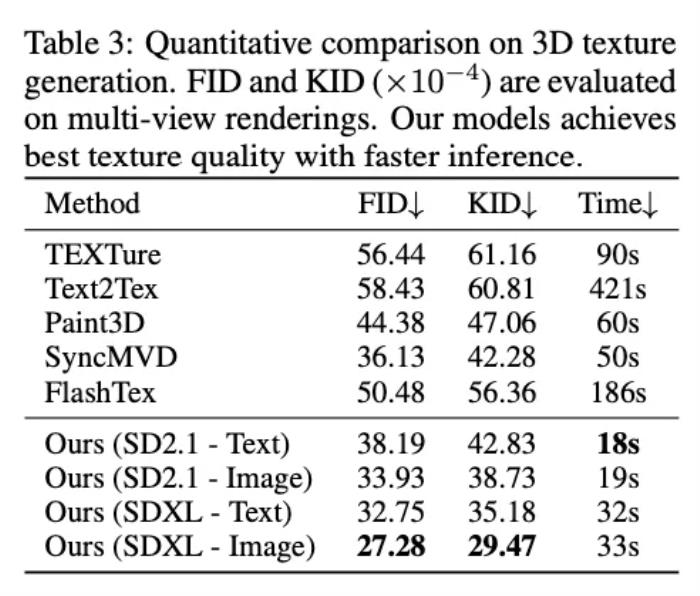
文章還對所提出的方法進行了消融實驗,如下表所示,其驗證了 MV-Adapter 訓(xùn)練的高效,以及其提出的并行注意力架構(gòu)的有效性。
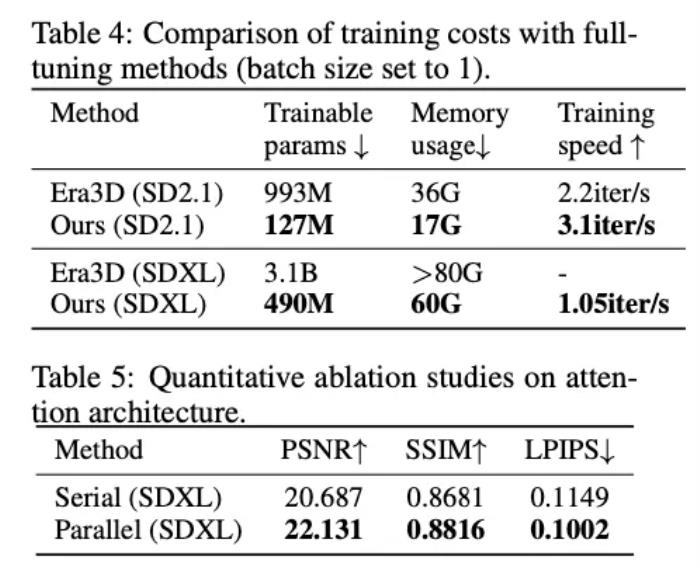
此外,文章還在附錄部分探討了以下內(nèi)容:
MV-Adapter 與 LoRA 的討論和分析
MV-Adapter 原生的圖像修復(fù)能力
MV-Adapter 的應(yīng)用價值
將 MV-Adapter 擴展至任意視角圖像生成的實現(xiàn)細節(jié)
更多實驗細節(jié)請參閱原論文。
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認(rèn)可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責(zé)任。
