

 新火種
2024-12-10
新火種
2024-12-10 


DataforAIMeetup杭州開啟:多企攜手,破局數據服務AI困境
在當今數字化時代,AI 的應用浪潮正以前所未有的速度席卷各行各業。企業紛紛投身其中,試圖借助AI技術重塑自身的產品體系與業務流程。然而,在 AI 的三大核心要素中,數據這一關鍵要素在許多企業內部卻面臨著困境。
一方面,企業內部的數據往往缺乏有效的治理,數據管理混亂無序,數據存儲分散,缺乏統一的標準和規范,導致數據的檢索、調用和共享變得困難。另一方面,數據質量參差不齊,使得數據的準確性和可靠性大打折扣。這些都導致企業無法充分挖掘數據中蘊含的價值,大量有價值的數據資產被閑置浪費。這些問題最終限制了 AI 效果的發揮。
如今越來越多的企業認識到數據對于 AI 的重要性。他們開始積極探尋能夠讓數據高效、成本可控地服務于 AI。為了滿足大家在這一領域的需求,Data for AI Meetup 活動應運而生。我們邀請到了業內領先的數據和 AI 公司,以及權威的研究機構,圍繞如何更好地實現 Data for AI 這一主題展開深入的探討與交流,旨在為大家提供切實可行的解決方案和思路,助力企業在 AI 時代充分釋放數據的巨大能量,實現數字化轉型的可持續發展。
主辦單位:螞蟻開源,Datastrato
協辦單位:LF AI & DATA,OceanBase,ProtonBase,騰訊大數據

活動時間:2024年12月14日(周六)13:30-17:30
活動地點:浙江省杭州市黃龍國際中心E座4F
活動議程13:00-13:30 簽到
13:30-13:40 Openning
13:40-14:20 《螞蟻開源向量索引庫 VSAG 介紹及其業務落地實踐》
演講者: 王翔宇(祥予), 螞蟻向量引擎專家
王翔宇,螞蟻數據部技術專家。2023 年加入螞蟻集團,主要負責螞蟻向量檢索算法研發以及千億規模向量數據庫在螞蟻業務場景落地。 對向量檢索算法與系統有豐富經驗。 同時也是開源向量數據庫 Milvus 的核心開發者,BigANN 21 Track 2 第一名團隊成員。曾在 Zilliz 負責存儲和 GPU 算法相關開發工作。

演講內容:
本次分享將重點介紹螞蟻集團自研向量索引庫涉及的關鍵技術和在業務場景中的落地實踐。
向量檢索在信息檢索、推薦系統和語義匹配等領域發揮著重要作用。隨著近兩年 LLM 的發展和 RAG 架構的普及,向量檢索技術面臨著更多新的挑戰。我們將圍繞這些背景,介紹開發 VSAG 索引庫的動機、設計目標和實現方式。內容涵蓋了算法選擇、索引結構、快速搜索技術和性能優化策略。此外,我們還將分享如何應對高維度向量、超大規模數據集和超高精度等挑戰。
通過本次分享,希望能夠提供參與者對 VSAG 的深入理解,并探討在面對實際場景中的應用時可能遇到的技術挑戰和解決方案。無論你是 RAG 開發者、向量數據庫工程師或對向量檢索技術感興趣的研究人員,這次分享都可能為你帶來有益的經驗和見解。
讓我們一起探索向量檢索的魅力和挑戰!
14:20-15:00 《Gravitino 的統一權限與非結構化數據管理之道》
演講者:李明皇,Datastrato工程師,Apache Gravitino PPMC & Committer
2020年福州大學碩士畢業后從事OLAP引擎開發,先后參與了Presto、ClickHouse、Apache Druid和StarRocks的引擎開發,2023年加入Datastrato,目前主要參與Gravitino的內核研發。

演講內容:
隨著大數據和AI的迅猛發展,企業面臨著管理分布于不同來源、類型和地域的海量數據的挑戰,如何實現高效的元數據管理和統一的權限控制,已成為數據治理中的關鍵問題。Apache Gravitino 作為一款高性能、跨地域的聯邦式元數據湖,可以直接管理多源異構的數據元信息,為用戶提供統一的元數據訪問接口,支持數據和 AI 資產的高效整合。
本次分享將詳細介紹 Gravitino 在統一權限和非結構化數據管理的原理和應用,以及項目當前的進展和發展規劃。
15:00-15:40 《加速 AI 應用落地:OceanBase 實踐分享》
演講者:蔡飛志(谷漸),OceanBase 技術部高級專家
畢業于北京大學,14 年進入 OceanBase 團隊后,先后從事 OceanBase 數據庫代理、數據庫驅動、分布式存儲的研發,目前是 OceanBase 開源生態的研發負責人。對于 LLM、AI Agent 比較感興趣,是個喜歡聊天的 i 人。

演講內容:
在本次分享中,我將深入解析當前數據行業的發展動態,并結合自身觀察,為大家呈現全面的行業圖景。數據行業作為信息化時代的重要支柱,正在快速變革,數據的種類和復雜度日益增加,如何高效地管理和應用這些數據成為業界關注的焦點。我將詳細介紹 OceanBase 數據庫在處理結構化、半結構化和非結構化數據中的方案設計。面對這三種類型的數據,OceanBase 數據庫通過獨特的架構設計和強大的技術支持,實現了高效的存儲、檢索和分析能力,滿足了不同業務場景的需求。此外,我將探討 OceanBase 數據庫在人工智能應用中的作用,探討數據庫功能在 AI 應用上提供的價值,加速 AI 應用的落地。
15:40-15:50 中場休息
15:50-16:30 《分布式Data Warebase – AI時代的數據底座》
演講者: 胡月軍ProtonBase 技術副總裁
現任ProtonBase 技術副總裁,從事存儲與計算引擎的設計與研發工作,致力于打造 AI 時代云原生一體化的數據存儲,計算和管理系統。曾任阿里巴巴計算平臺事業部資深技術專家,發起和參與了阿里巴巴交互式分析引擎 Hologres 的研發。在此之前,從事5年搜索和廣告引擎的設計與開發,負責過阿里巴巴淘寶、天貓、1688、Sourcing 和 AliExress 的搜索與廣告在線引擎系統,主導過阿里巴巴國際搜索和廣告引擎在離線的一體化升級改造。

演講內容:
隨著AI的發展,數據從信息的載體越來越成為智能的燃料,這也為數據系統提出了更高的要求。本演講將分享一種全新的Data Warebase技術理念,它吸收融合了數據庫和大數據領域的核心技術,通過一個系統來滿足簡單讀寫,實時數倉,數據湖和搜索等場景的傳統需求,同時能夠支持向量檢索和特征召回等AI場景的新需求,為AI時代的智能應用提供了完備的數據底座,助力企業的數智化業務發展。
大綱
1. 數據智能化背景
2. 當前典型數據系統架構和痛點
3. AI對數據系統的新需求
4. 分布式Data Warebase的核心技術
5. 實踐案例與展望
16:30-17:10 《Data+AI場景下的分布式引擎探索與實踐》
演講者:李志方 騰訊大數據基礎架構高級研發工程師
博士畢業于華東師范大學,從事數據庫方向研究,曾發表PPoPP/ICDE等多篇頂會論文。畢業后加入騰訊湖倉團隊,負責Ray/Iceberg內核,以及Data+AI場景的深度優化。

演講內容:
以Spark/Flink為代表的基于JVM的經典引擎在BigData領域獲得了巨大成功,隨著大模型等AI技術的崛起,經典引擎在Data+AI融合場景下的支持仍然稍顯不足,存在開發難度大和資源利用率低等諸多問題。因此一方面,騰訊大數據團隊在經典的Spark引擎基礎上升級了湖上的向量查詢能力,充分發揮其在可伸縮性上的優勢。另外一方面,也圍繞Python生態和Ray引擎,進行了新鏈路的探索。最初是基于PyIceberg與湖倉底座進行單機多卡的模型推理與訓練。隨著項目迭代,借助Ray靈活而強大的分布式異構編程能力,進而拓展實現了高性能的數據科學鏈路,包括分布式pandas-like數據分析,加速因果推斷等多個業務場景。
17:10-17:30 自由討論和交流
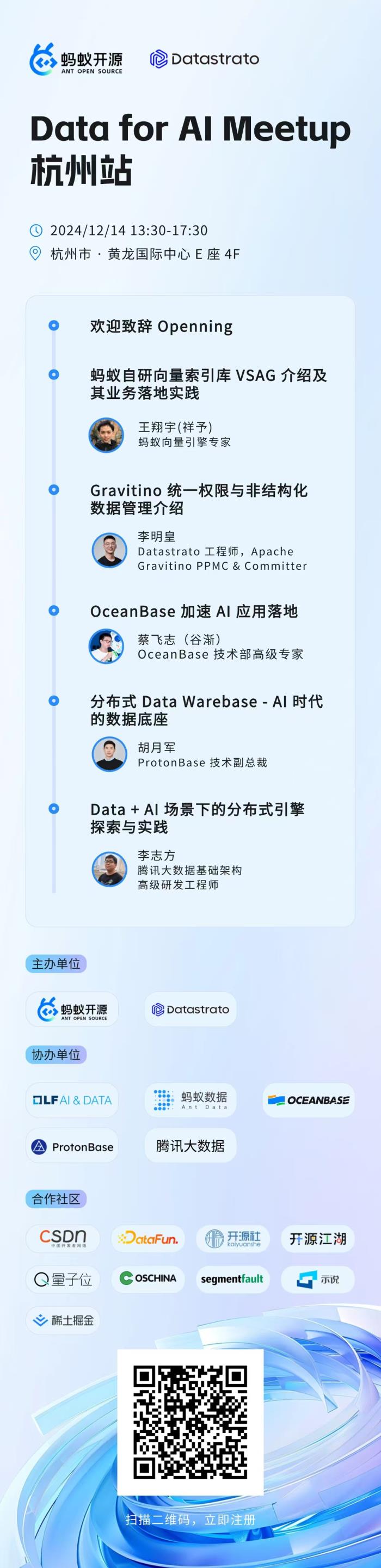
報名鏈接:
http://data4ai-hz.bagevent.com
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
