

 新火種
2024-12-04
新火種
2024-12-04 


打破GNN與語言模型間壁壘,圖輔助多模態(tài)預(yù)訓(xùn)練框架用于催化劑篩選,登Nature子刊

編輯 | KX
吸附能是一種反應(yīng)性描述符,必須準(zhǔn)確預(yù)測(cè),才能有效地將機(jī)器學(xué)習(xí)應(yīng)用于催化劑篩選。該過程涉及在催化表面上的不同吸附構(gòu)型中找到最低能量。
盡管圖神經(jīng)網(wǎng)絡(luò)在計(jì)算催化劑系統(tǒng)的能量方面表現(xiàn)出色,但它們嚴(yán)重依賴原子空間坐標(biāo)。相比之下,基于 Transformer 的語言模型可以直接使用人類可讀的文本輸入,無需詳細(xì)的原子位置或拓?fù)浣Y(jié)構(gòu);然而,這些語言模型通常難以準(zhǔn)確預(yù)測(cè)吸附構(gòu)型的能量。
近日,卡內(nèi)基梅隆大學(xué)的研究人員通過一種稱為圖輔助預(yù)訓(xùn)練的自監(jiān)督過程,將其潛在空間與成熟的圖神經(jīng)網(wǎng)絡(luò)對(duì)齊,從而改進(jìn)了預(yù)測(cè)語言模型。該方法將吸附構(gòu)型能量預(yù)測(cè)的平均絕對(duì)誤差降低了 7.4-9.8%,將模型的注意力重新引導(dǎo)到吸附構(gòu)型上。
在此基礎(chǔ)上,研究人員建議使用生成式大語言模型為預(yù)測(cè)模型創(chuàng)建文本輸入,而不依賴于精確的原子位置。這展示了語言模型在沒有詳細(xì)幾何信息的能量預(yù)測(cè)中的潛在用例。
相關(guān)研究以「Multimodal language and graph learning of adsorption configuration in catalysis」為題,于 11 月 27 日發(fā)布在《Nature Machine Intelligence》上。

機(jī)器學(xué)習(xí) (ML) 方法,尤其是圖神經(jīng)網(wǎng)絡(luò) (GNN),已成為計(jì)算成本高昂的密度泛函理論 (DFT) 模擬的有效替代品。這可以加速高通量材料篩選的能量和力預(yù)測(cè)。基于 ML 的 DFT 替代模型在催化中的成功應(yīng)用可以識(shí)別特定反應(yīng)的最佳催化劑材料。
盡管 GNN 在催化領(lǐng)域的機(jī)器學(xué)習(xí)應(yīng)用中取得了重大成功,但獲取其輸入數(shù)據(jù)可能具有挑戰(zhàn)性,因?yàn)樗鼈冃枰游恢没蛲負(fù)洹?gòu)建結(jié)構(gòu)的圖表示依賴于識(shí)別每個(gè)原子在特定接近度閾值內(nèi)的最近鄰。然而,實(shí)現(xiàn)如此精確的坐標(biāo)可能很困難,這主要限制了 GNN 在理論研究中的適用性。
語言模型可以處理原子系統(tǒng)的文本描述,而不是用原子坐標(biāo)構(gòu)建輸入。例如,MOFormer 模型將金屬有機(jī)骨架 (MOF) 編碼為文本字符串表示形式,稱為 MOFid,與圖表示不同,它包含有關(guān)構(gòu)建塊和拓?fù)浯a的化學(xué)信息。
吸附能的識(shí)別是催化劑篩選中的關(guān)鍵反應(yīng)性描述符。雖然語言模型有可能繞過對(duì)精確原子位置的需求,但其準(zhǔn)確性仍然是一個(gè)問題。提高模型的準(zhǔn)確性對(duì)于有效地將這種基于文本的方法應(yīng)用于吸附構(gòu)型能量預(yù)測(cè)任務(wù)至關(guān)重要。
多模態(tài)預(yù)訓(xùn)練框架在此,研究人員開發(fā)了一個(gè)多模態(tài)預(yù)訓(xùn)練框架,稱為圖輔助預(yù)訓(xùn)練,在共享潛在空間內(nèi)將已建立的基于圖的方法與新引入的基于文本的方法聯(lián)系起來。引入此方法是為了提高吸附構(gòu)型能量預(yù)測(cè)的準(zhǔn)確性。該框架使用 RoBERTa 編碼器進(jìn)行文本處理,并使用線性回歸頭來預(yù)測(cè)催化劑系統(tǒng)能量。
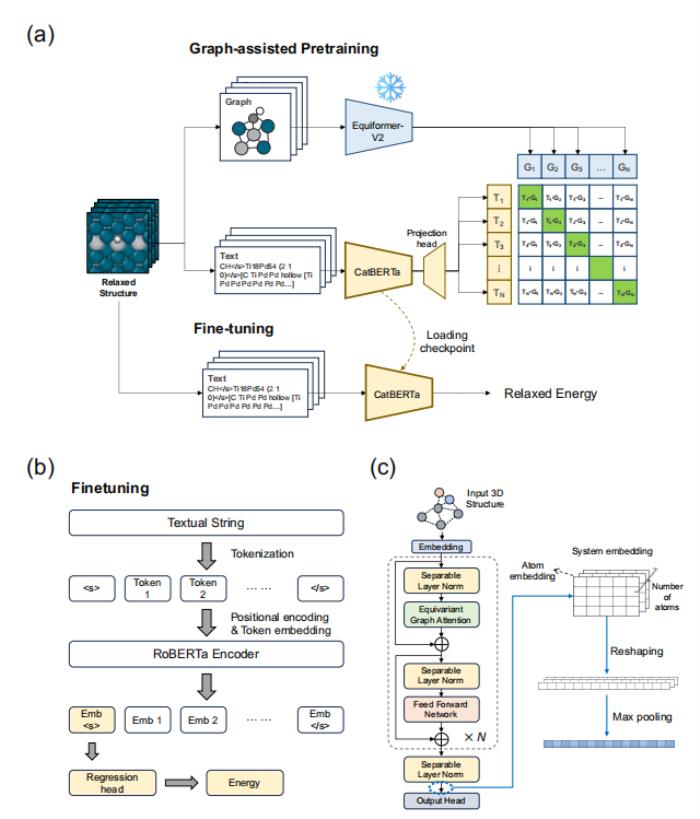
此外,EquiformerV2 模型由于能夠?qū)_的原子結(jié)構(gòu)進(jìn)行編碼而被用作圖編碼器。在此框架中,文本和圖嵌入在預(yù)訓(xùn)練期間都以自監(jiān)督的方式對(duì)齊。隨后,該模型經(jīng)歷微調(diào)階段,在該階段,使用從 DFT 計(jì)算中得出的能量標(biāo)簽以監(jiān)督方式進(jìn)行訓(xùn)練。重要的是,微調(diào)步驟完全依賴于文本輸入數(shù)據(jù),而不需要圖表示。
研究進(jìn)行兩種類型的下游推理:一種是為了評(píng)估圖輔助預(yù)訓(xùn)練的效果,另一種是為了證明該模型在沒有精確了解吸附質(zhì)-催化劑系統(tǒng)結(jié)構(gòu)的情況下預(yù)測(cè)能量的能力。
首先,為了評(píng)估圖輔助預(yù)訓(xùn)練對(duì)預(yù)測(cè)準(zhǔn)確性的影響,研究人員對(duì)從 ML 弛豫結(jié)構(gòu)派生的測(cè)試集字符串進(jìn)行了預(yù)測(cè)。CatBERTa 模型以文本字符串作為輸入,使用從 ML 弛豫結(jié)構(gòu)派生的文本數(shù)據(jù)進(jìn)行訓(xùn)練,以預(yù)測(cè)弛豫構(gòu)型的能量。其次,為了說明該模型在不依賴精確結(jié)構(gòu)的情況下預(yù)測(cè)能量的潛力,使用 LLM 生成晶體學(xué)信息文件 (CIF) 格式的指示性結(jié)構(gòu)。這是通過提供吸附質(zhì)和催化劑的化學(xué)成分和表面取向作為輸入來完成的。生成的 CIF 被轉(zhuǎn)換成與 CatBERTa 輸入兼容的文本字符串。
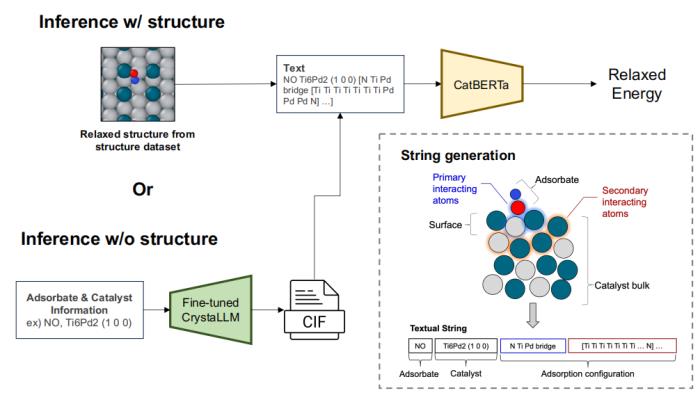
文本字符串是通過將結(jié)構(gòu)信息轉(zhuǎn)換為包含三個(gè)部分的特定格式生成的。第一部分代表吸附物的化學(xué)符號(hào),第二部分包括催化劑的化學(xué)符號(hào)和米勒指數(shù),分別表示化學(xué)組成和表面取向。最后一部分描述了吸附構(gòu)型,捕獲了吸附物和催化劑表面頂層中的主要和次要相互作用原子,這些原子是使用 Pymatgen 庫(kù)識(shí)別的。
圖輔助預(yù)訓(xùn)練是框架的核心組件,旨在將知識(shí)從圖嵌入轉(zhuǎn)移到文本嵌入。這種方法彌補(bǔ)了 GNN 與語言模型之間的差距。
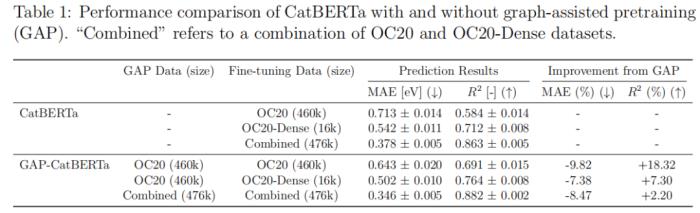
圖輔助預(yù)訓(xùn)練方法導(dǎo)致 MAE 大幅降低,如表 1 所示,降幅從 7.4% 到 9.8% 不等。為了評(píng)估圖輔助預(yù)訓(xùn)練帶來的增強(qiáng)效果。比較了使用和不使用這種預(yù)訓(xùn)練方法的 CatBERTa 的預(yù)測(cè)結(jié)果。在所有情況下,圖輔助預(yù)訓(xùn)練都提高了下游預(yù)測(cè)準(zhǔn)確性。
這表明圖輔助預(yù)訓(xùn)練可以作為一種可轉(zhuǎn)移的預(yù)訓(xùn)練策略,彌合高性能 GNN 與新興的基于 Transformer 的語言模型方法之間的差距。
展望未來該研究提出的多模態(tài)預(yù)訓(xùn)練方法,將圖和文本嵌入集成到潛在空間中。這促進(jìn)了不同模型設(shè)置之間的連接,增強(qiáng)了語言模型在預(yù)測(cè)任務(wù)中的應(yīng)用。
雖然當(dāng)前框架在預(yù)測(cè)準(zhǔn)確性和生成有效性方面存在局限性,但它是更詳細(xì)的模擬或?qū)嶒?yàn)驗(yàn)證的開始。
展望未來,研究人員表示:「我們的目標(biāo)是開發(fā)一個(gè)更全面的基于語言的催化劑設(shè)計(jì)平臺(tái),通過改進(jìn)預(yù)測(cè)和生成能力,將它們集成到單個(gè) LLM 中,整合其他功能工具,并在類似代理的框架中為平臺(tái)配備推理和規(guī)劃能力。」
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
