

 新火種
2024-12-04
新火種
2024-12-04 


開源社區參數量最大的文生視頻模型來了,騰訊版Sora免費使用

AIxiv專欄是機器之心發布學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報道了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯系報道。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
想要體驗文生視頻的小伙伴又多了一個選擇!
今日,騰訊宣布旗下的混元視頻生成大模型(HunYuan-Video )對外開源,模型參數量 130 億,可供企業與個人開發者免費使用。目前該模型已上線騰訊元寶 APP,用戶可在 AI 應用中的「AI 視頻」板塊申請試用。
騰訊混元視頻生成開源項目相關鏈接:
官網:https://aivideo.hunyuan.tencent.com
代碼:https://github.com/Tencent/HunyuanVideo模型:https://huggingface.co/tencent/HunyuanVideo技術報告:https://github.com/Tencent/HunyuanVideo/blob/main/assets/hunyuanvideo.pdf騰訊混元視頻生成模型 HunYuan-Video(HY-Video)是一款突破性的視頻生成模型,提供超寫實畫質質感,能夠在真實與虛擬之間自由切換。它打破了小幅度動態圖的限制,實現完整大幅度動作的流暢演繹。
HY-Video 具備導演級的運鏡效果,具備業界少有的多視角鏡頭切換主體保持能力,藝術鏡頭無縫銜接,一鏡直出,展現出如夢似幻的視覺敘事。同時,模型在光影反射上遵循物理定律,降低了觀眾的跳戲感,帶來更具沉浸感的觀影體驗。模型還具備強大的語意遵從能力,用戶只需簡單的指令即可實現多主體準確的描繪和流暢的創作,激發無限的創意與靈感,充分展現 AI 超寫實影像的獨特魅力。
總的來說,HunYuan-Video 生成的視頻內容具備以下特點:
卓越畫質:呈現超寫實的視覺體驗,輕松實現真實與虛擬風格的切換。
動態流暢:突破動態圖像的局限,完美展現每一個動作的流暢過程。
語義遵從:業界首個以多模態大語言模型為文本編碼器的視頻生成模型,天然具備超高語義理解能力,在處理多主體及屬性綁定等生成領域的難點挑戰時表現出色。
原生鏡頭轉換:多視角鏡頭切換主體保持能力,藝術鏡頭無縫銜接,打破傳統單一鏡頭生成形式,達到導演級的無縫鏡頭切換效果。
AI 文生圖開源生態蓬勃發展,眾多創作者與開發者為生態貢獻作品與插件。然而,視頻生成領域的開源模型與閉源模型差距較大。騰訊混元作為第一梯隊大模型,將視頻生成開源,相當于將閉源模型的最強水平帶到開源社區,有望促進視頻生成開源生態像圖像生成社區一樣繁榮。
通過騰訊元寶 APP-AI 應用-AI 視頻即可使用該功能(前期需申請)能力展示HunYuan-Video 在文生視頻的畫質、流暢度與語義一致性等方面都具有較高的質量。超寫實畫質
騰訊混元視頻生成模型提示詞:超大水管浪尖,沖浪者在浪尖起跳,完成空中轉體。攝影機從海浪內部穿越而出,捕捉陽光透過海水的瞬間。水花在空中形成完美弧線,沖浪板劃過水面留下軌跡。最后定格在沖浪者穿越水簾的完美瞬間。
騰訊混元視頻生成模型提示詞:穿著白床單的幽靈面對著鏡子。鏡子中可以看到幽靈的倒影。幽靈位于布滿灰塵的閣樓中,閣樓里有老舊的橫梁和被布料遮蓋的家具。閣樓的場景映照在鏡子中。幽靈在鏡子前跳舞。電影氛圍,電影打光。原生鏡頭切換
視頻由騰訊混元視頻生成,提示詞:一位中國美女穿著漢服,頭發飄揚,背景是倫敦,然后鏡頭切換到特寫鏡頭

騰訊混元視頻生成模型提示詞:特寫鏡頭拍攝的是一位 60 多歲、留著胡須的灰發男子,他坐在巴黎的一家咖啡館里,沉思著宇宙的歷史,他的眼睛聚焦在畫外走動的人們身上,而他自己則基本一動不動地坐著,他身穿羊毛大衣西裝外套,內襯系扣襯衫,戴著棕色貝雷帽和眼鏡,看上去很有教授風范,片尾他露出一絲微妙的閉嘴微笑,仿佛找到了生命之謎的答案,燈光非常具有電影感,金色的燈光,背景是巴黎的街道和城市,景深,35 毫米電影膠片。
騰訊混元視頻生成模型提示詞:一個男人在書房對著電腦,敲打鍵盤,認真地工作,鏡頭切換到臥室里,暖黃色的燈光下,他的妻子在床邊讀著故事書,輕柔地拍著孩子的胸口,哄孩子入睡。溫馨的氛圍。高語義一致

一位戴著復古飛行護目鏡的機械師,半跪在蒸汽朋克風格的工作室里。她棕色卷發挽成發髻,零星的銀色發絲閃著金屬光澤。深棕色皮質工裝背帶褲上沾滿機油污漬,袖口卷起露出布滿齒輪紋身的手臂。特寫她正用黃銅工具調試一只機械鳥,齒輪間冒出縷縷蒸汽,工作臺上散落著銅管、發條和老式圖紙。

固定機位的老公寓內景,自然光透過紗簾漫射,青色街燈滲入,茶煙裊裊升起,老式家具靜靜陳列,定格歲月流逝的時光。采用多種創新技術加速行業創新步伐基于騰訊混元的開源模型,開發者及企業無需從頭訓練,即可直接用于推理,并可基于騰訊混元系列打造專屬應用及服務,能夠節約大量人力及算力。同時,各大模型研發團隊均可基于騰訊混元模型進行研究與創新,加速行業創新步伐。據技術報告,在混元視頻生成模型架構設計與訓練中,采用了多個創新技術:包括通過新一代本文編碼器提升語義遵循,自研 3D 視覺編碼器支持圖像視頻混合訓練,通過全注意力機制提升畫面運鏡能力,并根據自研的圖像視頻 Scaling Law 設計和訓練了最優配比模型。模型方法介紹Hunyuan-Video 是一個綜合的視頻訓練系統,涵蓋了從數據處理到模型部署的各個方面。本技術報告介紹了我們的數據預處理技術,包括數據過濾算子和重新標注模型,并詳細說明了 Hunyuan-Video 所有組件的架構,和我們發現的視頻生成模型 scaling law,以及我們的訓練和推理策略。我們討論了加速模型訓練和推理的方法,使得開發一個擁有 130 億參數的大型模型成為可能,并評估了我們的文本到視頻基礎模型的性能,與最先進的視頻生成模型(包括開源和專有模型)進行了比較。最后,我們展示了基于預訓練基礎模型構建的各種應用,并附上相關的可視化效果。
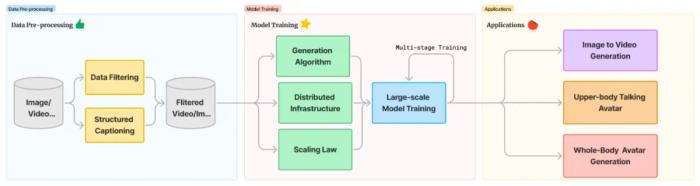
精細的數據處理架構我們采用自動化數據過濾和人工過濾相結合的方式,從粗到細構建多個階段訓練數據集。在 256p、360p、540p 和 720p 訓練階段,采用各種過濾器對圖片、視頻數據過濾,并逐步提高過濾算子的閾值。在 SFT 階段訓練階段,采用人工過濾的方式以充分保障訓練數據質量。該圖突出顯示了在每個階段使用的一些最重要的過濾器。在每個階段,將會移除大量數據,移除的比例從前一階段的數據的一半到五分之一不等。在這里,灰色條表示每個過濾器過濾掉的數據量,而彩色條則表示每個階段剩余的數據量。
模型架構設計首個適配MLLM 作為文本編碼器的視頻生成模型,具備強大的語義跟隨能力,可以輕松應對多個主體描繪。在文生圖和文生視頻等視覺生成模型中,負責處理文本、理解文字的文本編碼器起著關鍵作用。目前行業中大部分的視覺生成模型的文本編碼器,適配的主要是上一代語言模型。混元視頻生成是業界適配最新一代大語言模型 MLLM (Multimodal Large Language Model)作為文本編碼器的視頻生成模型,具備強大的語義跟隨能力,更好地應對多個主體描繪,實現更加細節的指令和畫面呈現。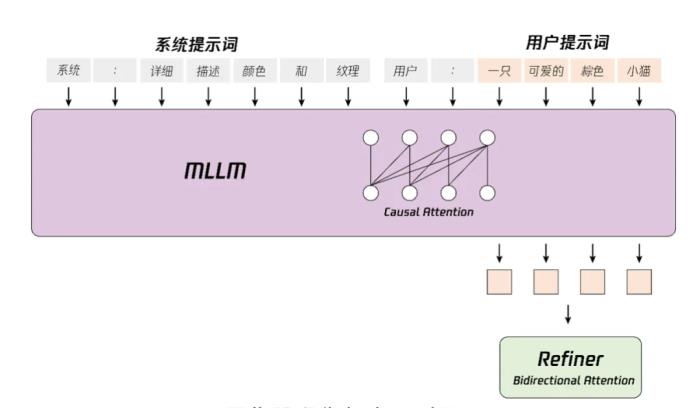
文本到視頻等生成任務中,文本編碼器在隱式表征空間中提供的指導信息起著關鍵作用。業界常見模型通常使用預訓練的 CLIP 和 T5 作為文本編碼器,其中 CLIP 使用 Transformer Encoder,而 T5 使用的是 Encoder-Decoder 結構。相比之下,我們利用最先進的多模態大語言模型(MLLM)進行編碼操作,它具有以下優勢:(1)與 T5 相比,MLLM 在視覺指令微調后的表征空間中具有更好的圖像 - 文本對齊性,這減輕了擴散模型中指令跟隨的難度;(2)與 CLIP 相比,MLLM 在圖像細節描述和復雜推理方面有著更加優越的能力;(3)MLLM 可以通過設計系統指令前置于用戶提示來充當零樣本學習器,幫助文本特征更加關注關鍵詞。此外,如圖 8 所示,MLLM 基于因果注意力,而 T5-XXL 利用雙向注意力,為擴散模型產生更好的文本指導。因此,我們遵循的方法,引入了一個額外的雙向令牌細化器,以增強文本特征。此外,CLIP 文本特征也是文本信息的摘要。如圖所示。我們采用了 CLIP-Large 文本特征的最終非填充令牌作為全局指導,將其整合到雙流和單流的 DiT 塊中。—— 騰訊混元視頻生成模型開源技術報告通過自研的 3D 視覺編碼器支持混合圖片和視頻訓練 / 先進的圖像視頻混合 VAE(3D 變分編碼器),讓模型在重建能力場景有明顯提升,具備小人臉和動作的極高上限。視覺編碼器在壓縮圖片 / 視頻數據,保留細節信息方面起著關鍵作用。混元團隊通過自研的 3D 視覺編碼器支持混合圖片 / 視頻訓練,同時優化了編碼器訓練算法,顯著提升了編碼器在快速運行、紋理細節上的壓縮重建性能,使得視頻生成模型在細節表現上,特別是小人臉、高速鏡頭等場景有明顯提升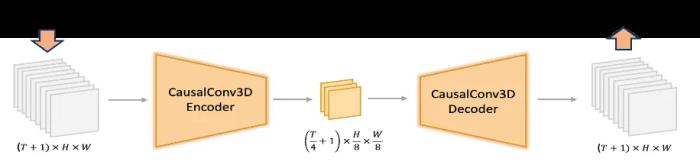
從頭到尾用 full attention(全注意力)的機制,沒有用時空模塊,提升畫面流暢度。混元視頻生成模型采用基于單雙流模型機制的全注意力網絡架構,使得每幀視頻的銜接更為流暢,并能實現主體一致的多視角鏡頭切換。與「分離的時空注意力機制」分別關注視頻中的空間特征和時間特征,相比之下,全注意力機制則更像一個純視頻模型,表現出更優越的效果。其次,它支持圖像和視頻的統一生成,簡化了訓練過程并提高了模型的可擴展性。最后,它更有效地利用了現有的大型語言模型(LLM)相關的加速能力,從而提升了訓練和推理的效率。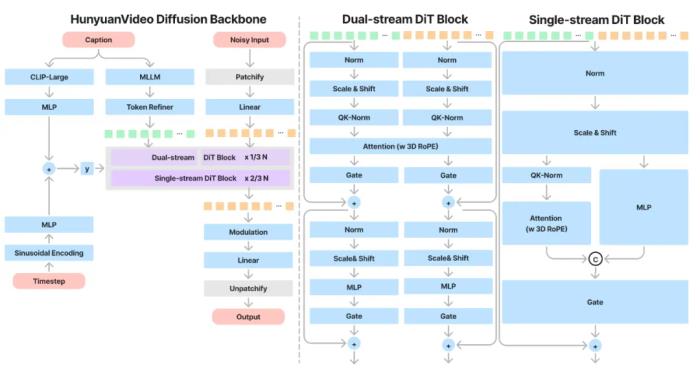
根據自研的圖像視頻 Scaling Law 設計和訓練了最優配比模型。Scaling Law 通常用來描述模型性能如何隨著模型大小、訓練數據和計算資源的增加而變化。在人工智能研究的早期,訓練模型往往需要在諸多超參數之間反復嘗試,而 Scaling Law 提供了指導如何擴展這些參數的經驗公式,使模型達到更好的性能?。Scaling Law 在 AI 領域的應用非常廣泛。尤其是在大模型的訓練中,幫助科學家們確定,如果需要模型有更好的表現,應該優先增加模型參數、訓練數據的規模還是訓練計算量。Google、OpenAI 等領先的科技公司對 Scaling Law 進行了大量的探索,這些研究為現代大型 AI 模型的成功奠定了基礎?。但是多模態模型領域(如圖像、視頻、音頻等)的 Scaling Law 尚沒有被真真切切地驗證過。騰訊混元團隊在過億級別的圖像視頻數據上,較為系統的訓練驗證了圖像視頻生成模型的 Scaling Law。根據我們的發現,我們可以準確的設計出最優的模型參數 / 數據 / 算力配比,也給了后續學術界和業界開發更大規模模型一個經驗公式,到底什么樣規模的模型需要多少訓練數據和算力,使模型達到更好的效果性能,可以推動業界在視頻生成領域的發展。?騰訊混元系列大模型全面開源從年初以來,騰訊混元系列模型的開源速度就在不斷加快。5 月 14 日,騰訊宣布旗下的混元文生圖大模型全面升級并對外開源,這是業內首個中文原生的 DiT 架構(DiT,即 Diffusion With Transformer)文生圖開源模型,支持中英文雙語輸入及理解,參數量 15 億,整體能力屬于國際領先水平。11 月 5 日,騰訊混元宣布最新的 MoE 模型「混元 Large」以及混元 3D 生成大模型「Hunyuan3D-1」正式開源。Hunyuan-Large 總參數量約 389B,激活參數量約 52B,文本長度 256k。這是當前業界參數規模最大、效果排名第一的 MoE 開源模型。其在 CMMLU、MMLU、CEval、MATH 等多學科綜合評測集以及中英文 NLP 任務、代碼和數學等 9 大維度全面領先,超過 Llama3.1、Mixtral 等一流的開源大模型。混元 3D 生成大模型則是首個同時支持文字、圖像生成 3D 的開源大模型。一期開源模型包含輕量版和標準版,輕量版僅需 10s 即可生成高質量 3D 資產。該模型在今年年初已在騰訊內部上線發布并應用于實際業務中,如 UGC 3D 創作、商品素材合成、游戲 3D 資產生成等。本次視頻生成大模型的開源,也是騰訊混元擁抱開源,用技術反饋社區的一大成果。至此,騰訊混元全系列大模型已實現全面開源。騰訊在開源上一直持開放態度,已開源了超 170 個優質項目,均來源于騰訊真實業務場景,覆蓋微信、騰訊云、騰訊游戲、騰訊 AI、騰訊安全等核心業務板塊,目前在 Github 上已累計獲得超 47 萬開發者關注及點贊。騰訊混元也會繼續保持開放,將更多經過騰訊應用場景經驗的模型開源出來,促進大模型生態的繁榮發展。未來衍生模型和生態插件展示未來我們會開源更多基于視頻創作生態的模型,這里小小劇透一些片段。視頻配音

語音驅動數字人

姿態控制
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
