

 新火種
2024-11-16
新火種
2024-11-16 


Sigmoid注意力一樣強,蘋果開始重新審視注意力機制
注意力是 Transformer 架構的關鍵部分,負責將每個序列元素轉(zhuǎn)換為值的加權和。將查詢與所有鍵進行點積,然后通過 softmax 函數(shù)歸一化,會得到每個鍵對應的注意力權重。
盡管 SoftmaxAttn 中的 softmax 具有廣泛的用途和有效性,但它并非沒有局限性。例如,softmax 函數(shù)有時會導致注意力集中在少數(shù)幾個特征,而忽略了其他信息。
近來,一些研究探索了 Transformer 中 softmax 注意力的替代方案,例如 ReLU 和 sigmoid 激活函數(shù)。最近,來自蘋果的研究者重新審視了 sigmoid 注意力并進行了深入的理論和實驗分析。
該研究證明:從理論上講,與 softmax 注意力相比,具有 sigmoid 注意力的 Transformer 是通用函數(shù)逼近器,并且受益于改進的正則化。

論文地址:https://arxiv.org/pdf/2409.04431
項目地址:https://github.com/apple/ml-sigmoid-attention
論文標題:Theory, Analysis, and Best Practices for Sigmoid Self-Attention
該研究還提出了一種硬件感知且內(nèi)存高效的 sigmoid 注意力實現(xiàn) ——FLASHSIGMOID。FLASHSIGMOID 在 H100 GPU 上的推理內(nèi)核速度比 FLASHATTENTION2 提高了 17%。
跨語言、視覺和語音的實驗表明,合理歸一化的 sigmoid 注意力與 softmax 注意力在廣泛的領域和規(guī)模上性能相當,而之前的 sigmoid 注意力嘗試無法實現(xiàn)這一點。
此外,該研究還用 sigmoid 內(nèi)核擴展了 FLASHATTENTION2,將內(nèi)核推理掛鐘時間減少了 17%,將現(xiàn)實世界推理時間減少了 8%。
論文作者 Jason Ramapuram 表示:如果想讓注意力快 18% 左右,你不妨試試 Sigmoid 注意力機制。他們用 Sigmoid 和基于序列長度的常量標量偏置取代了注意力機制中的傳統(tǒng) softmax。

Sigmoid 注意力
假設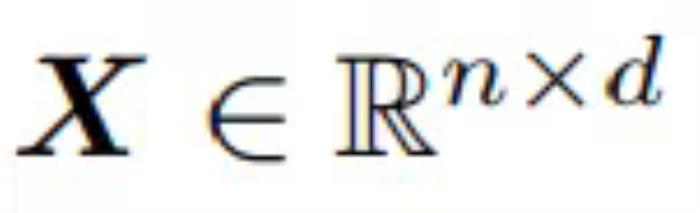 為向量 n 的輸入序列,每個向量是 d 維。接著研究者定義了三個可學習權重矩陣
為向量 n 的輸入序列,每個向量是 d 維。接著研究者定義了三個可學習權重矩陣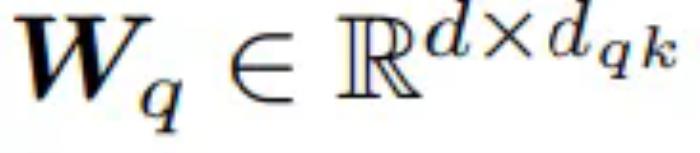 、
、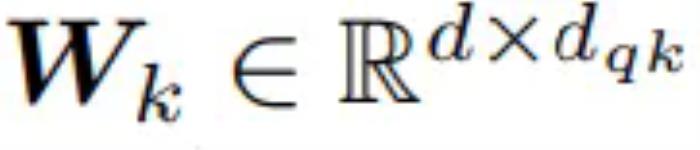 以及
以及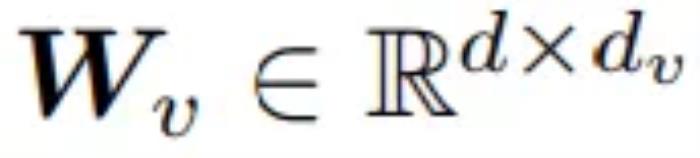 。這三個矩陣用于計算查詢
。這三個矩陣用于計算查詢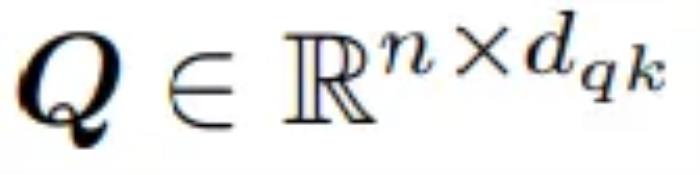 ,鍵
,鍵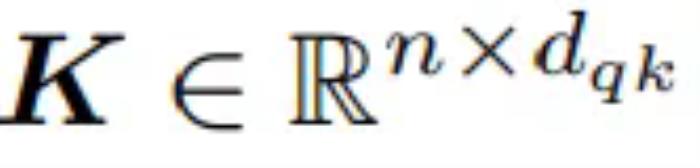 ,以及值
,以及值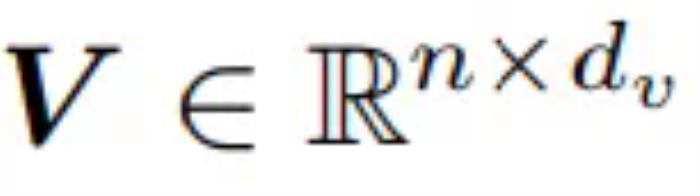 。可以得到如下公式:
。可以得到如下公式:
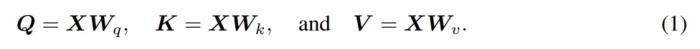
根據(jù)先前的研究,自注意力可以簡寫為:
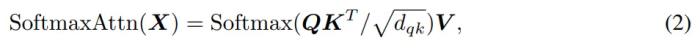
其中 Softmax 函數(shù)將輸入矩陣的每一行進行了歸一化。該研究將 Softmax 做了以下替換:
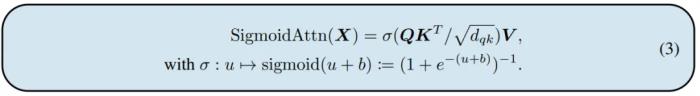
實際上,將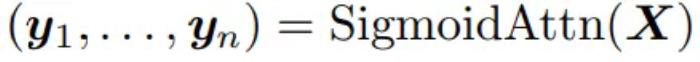 作為輸出序列,可以得到:
作為輸出序列,可以得到:

將多個 SigmoidAttn 輸出進行組合,得到多個頭的形式,如下所示:
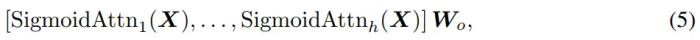
Sigmoid 注意力理論基礎
該研究對 SigmoidAttn 進行了分析,分析的目的主要有兩個:(1)證明當 SigmoidAttn 取代 SoftmaxAttn 時,Transformer 架構仍然是一個通用函數(shù)逼近器;(2)通過計算 SigmoidAttn 的 Lipschitz 常數(shù)來恢復其規(guī)律性。
具有 Sigmoid 注意力的 Transformer 是通用逼近器嗎?
經(jīng)典 Transformer 可以將連續(xù)的序列到序列函數(shù)近似到任意精度,這一特性稱為通用近似特性 (UAP,Universal Approximation Property)。UAP 非常受歡迎,因為它證明了架構的通用性和表示能力。由于 SigmoidAttn 修改了 Transformer 架構,因此從理論上保證這種修改不會影響表示能力并保留 UAP 的性能至關重要。該研究通過以下定理提供此保證。

結果表明,即使使用 SigmoidAttn,一系列 transformer 塊也可以實現(xiàn)上下文映射。
Sigmoid 注意力的正則性
與神經(jīng)網(wǎng)絡中的任何層一樣,SigmoidAttn 的正則性值得研究,因為它可以深入了解相應網(wǎng)絡的魯棒性及其優(yōu)化的難易程度。
SigmoidAttn 正則性定理為:
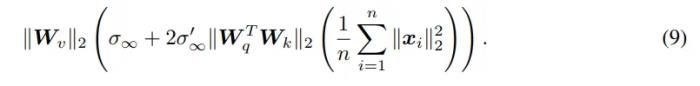
結果證明,SigmoidAttn 的局部 Lipschitz 常數(shù)遠低于 SoftmaxAttn 的最差局部 Lipschitz 常數(shù)。
FLASHSIGMOID:硬件感知實現(xiàn)
現(xiàn)代架構上的注意力計算往往會受到內(nèi)存訪問 IO 的限制。FLASHATTENTION 和 FLASHATTENTION2 通過優(yōu)化 GPU 內(nèi)存層次結構利用率來加速注意力計算。得益于這些方法提供的速度提升,該研究開發(fā)了 SigmoidAttn 的硬件感知實現(xiàn) ——FLASHSIGMOID,采用了三個核心思路:
Tiling:注意力分而治之的方法:與 FLASHATTENTION 和 FLASHATTENTION2 類似,F(xiàn)LASHSIGMOID 并行處理輸入部分以計算塊中的注意力輸出,有效地組合部分結果以生成最終的注意力輸出。
內(nèi)核融合:與 FLASHATTENTION 和 FLASHATTENTION2 一樣,F(xiàn)LASHSIGMOID 將 SigmoidAttn 的前向和后向傳遞的計算步驟實現(xiàn)為單個 GPU 內(nèi)核,通過避免高帶寬內(nèi)存 (HBM) 上的中間激活具體化,最大限度地減少內(nèi)存訪問并提高內(nèi)存效率。
激活重計算:sigmoid 注意力的向后傳遞需要 sigmoid 激活矩陣,如果在 GPU HBM 上具體化,則會導致執(zhí)行速度變慢和內(nèi)存效率低下。FLASHSIGMOID 通過僅保留查詢、鍵和值張量來解決這個問題,以便在向后傳遞期間重新計算 sigmoid 激活矩陣。盡管增加了 FLOPs,但事實證明,與具體化和保留注意力矩陣的替代方法相比,這種方法在掛鐘時間上更快,并且內(nèi)存效率更高。
實驗
為了實驗驗證 SigmoidAttn,該研究在多個領域進行了評估:使用視覺 transformer 進行監(jiān)督圖像分類、使用 SimCLR 進行自監(jiān)督圖像表示學習、BYOL(Bootstrap Your Own Latent)和掩碼自動編碼器 (MAE) 以及自動語音識別 (ASR) 和自回歸語言建模 (LM)。
該研究還在 TED-LIUM v3 上驗證了 ASR 的序列長度泛化,在所有這些領域和算法中,該研究證明 SigmoidAttn 的性能與 SoftmaxAttn 相當(圖 2 和 21),同時提供訓練和推理加速。
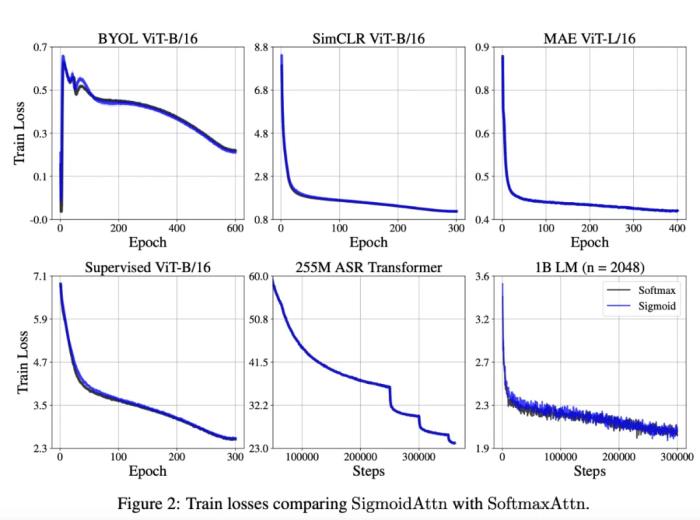
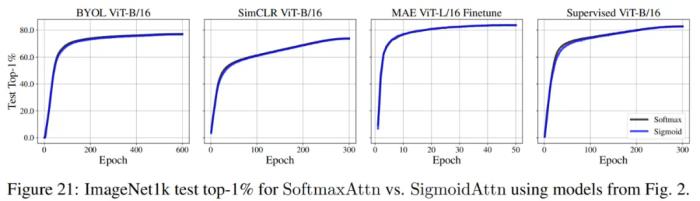
該研究得出以下觀察結果:
SigmoidAttn 對于沒有偏置的視覺任務是有效的(MAE 除外),但依賴于 LayerScale 以無超參數(shù)的方式匹配基線 SoftmaxAttn(圖 9-a)的性能。除非另有說明,否則為 SoftmaxAttn 呈現(xiàn)的所有結果也公平地添加了 LayerScale。
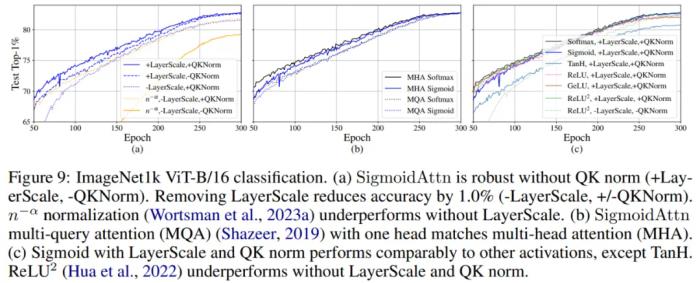
LM 和 ASR 對初始范數(shù)
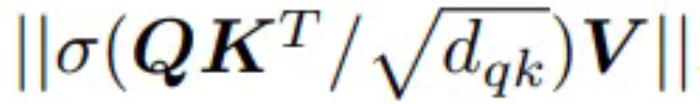
較為敏感。需要通過 (a) 相對位置嵌入進行調(diào)整;(b) 適當初始化 b 以實現(xiàn)相同效果 —— 允許使用任何位置嵌入。
感興趣的讀者可以閱讀論文原文,了解更多研究內(nèi)容。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關的任何行動之前,請務必進行充分的盡職調(diào)查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
