基于Transformer和注意力的可解釋核苷酸語言模型,用于pegRNA優化設計
基因編輯是一種新興的、比較精確的能對生物體基因組特定目標基因進行修飾的一種基因工程技術。先導編輯(Prime editor, PE)是美籍華裔科學家劉如謙(David R.Liu)團隊開發的精準基因編輯系統,PE 是一種很有前途的基因編輯工具,但由于缺乏準確和廣泛適用的方法,
基因編輯是一種新興的、比較精確的能對生物體基因組特定目標基因進行修飾的一種基因工程技術。先導編輯(Prime editor, PE)是美籍華裔科學家劉如謙(David R.Liu)團隊開發的精準基因編輯系統,PE 是一種很有前途的基因編輯工具,但由于缺乏準確和廣泛適用的方法,

觀點網訊:3月31日,百度發布業界首個基于全新互相關注意力(Cross-Attention)的端到端語音語言大模型,實現超低時延與超低成本。在電話語音頻道的語音問答場景中,調用成本較行業均值下降約50%-90%。當日,文小言宣布品牌煥新,率先接入該模型,還帶來多模型融合調度、圖片問答等功能升級。免責

注意力是 Transformer 架構的關鍵部分,負責將每個序列元素轉換為值的加權和。將查詢與所有鍵進行點積,然后通過 softmax 函數歸一化,會得到每個鍵對應的注意力權重。盡管 SoftmaxAttn 中的 softmax 具有廣泛的用途和有效性,但它并非沒有局限性。例如,softmax 函數

要點:1. Meta提出的注意力機制S2A能有效提升LLM回答問題的事實性和客觀性,降低模型對無關信息的敏感度,使其更準確。2. S2A通過深思熟慮的注意力機制(System2Attention)解決了LLM在回答問題時容易受上下文中虛假相關性影響的問題,提高了模型的推理能力。3. S2A的實現方式
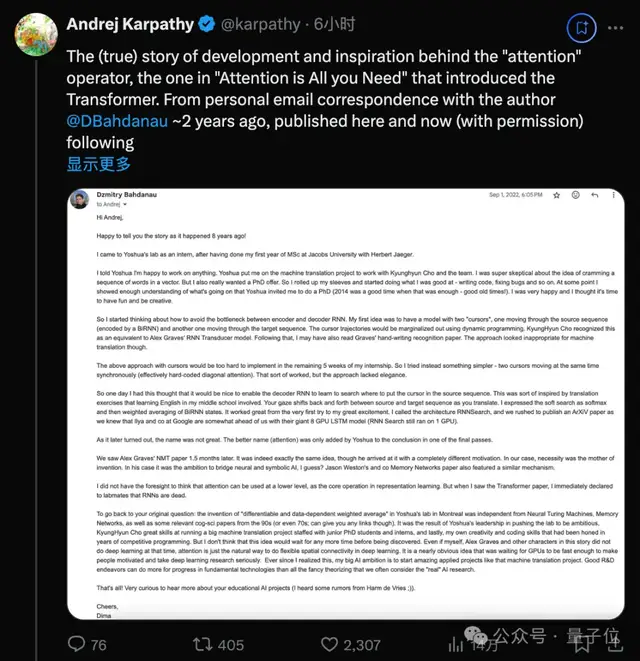
大模型的核心組件注意力機制,究竟如何誕生的?可能已經有人知道,它并非2017年Transformer開山論文《Attention is all you need》首創,而是來自2014年Bengio實驗室的另一篇論文。現在,這項研究背后更多細節被公開了!來自Karpathy與真正作者兩年前的郵件往來
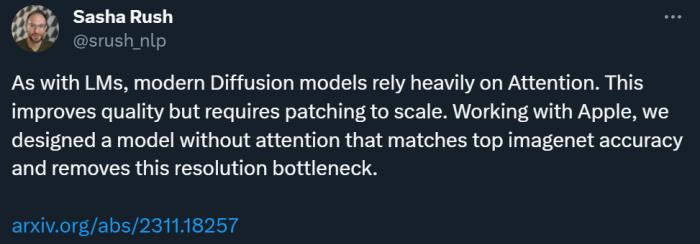
替代注意力機制,SSM 真的大有可為?為了用更少的算力讓擴散模型生成高分辨率圖像,注意力機制可以不要,這是康奈爾大學和蘋果的一項最新研究所給出的結論。眾所周知,注意力機制是 Transformer 架構的核心組件,對于高質量的文本、圖像生成都至關重要。

導讀:Transformer在自然語言處理、計算機視覺和音頻處理方面取得了巨大成功。作為其核心組成部分之一,Softmax Attention模塊能夠捕捉長距離的依賴關系,但由于Softmax算子關于序列長度的二次空間和時間復雜性,使其很難擴展。針對這點,研究者提出利用核方法以及稀疏注意力機制的方法

幾個小時前,著名 AI 研究者、OpenAI 創始成員之一 Andrej Karpathy 發布了一篇備受關注的長推文,其中分享了注意力機制背后一些或許少有人知的故事。

來自清華大學的研究者提出了一種新的注意力范式——代理注意力 (Agent Attention)。近年來,視覺 Transformer 模型得到了極大的發展,相關工作在分類、分割、檢測等視覺任務上都取得了很好的效果。然而,將 Transformer 模型應用于視覺領域并不是一件簡單的事情。
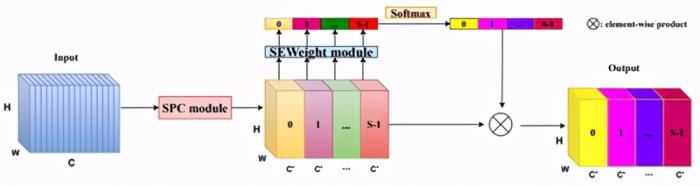
轉載:Bestsong簡介(1)Pyramid Split Attention Block用于增強特征提取(2)即插即用,可將Pyramid Split Attention Block取代ResNet的3×3卷積,提出基準網絡ESPANet(3)目標分類與目標檢測任務達到state-of-the-a