

 新火種
2024-01-03
新火種
2024-01-03 


Softmax注意力與線性注意力的優雅融合,AgentAttention推動注意力新升級
來自清華大學的研究者提出了一種新的注意力范式——代理注意力 (Agent Attention)。
近年來,視覺 Transformer 模型得到了極大的發展,相關工作在分類、分割、檢測等視覺任務上都取得了很好的效果。然而,將 Transformer 模型應用于視覺領域并不是一件簡單的事情。與自然語言不同,視覺圖片中的特征數量更多。由于 Softmax 注意力是平方復雜度,直接進行全局自注意力的計算往往會帶來過高的計算量。針對這一問題,先前的工作通常通過減少參與自注意力計算的特征數量的方法來降低計算量。例如,設計稀疏注意力機制(如 PVT)或將注意力的計算限制在局部窗口中(如 Swin Transformer)。盡管有效,這樣的自注意力方法很容易受到計算模式的影響,同時也不可避免地犧牲了自注意力的全局建模能力。
與 Softmax 注意力不同,線性注意力將 Softmax 解耦為兩個獨立的函數,從而能夠將注意力的計算順序從 (query?key)?value 調整為 query?(key?value),使得總體的計算復雜度降低為線性。然而,目前的線性注意力方法效果明顯遜于 Softmax 注意力,難以實際應用。
注意力模塊是 Transformers 的關鍵組件。全局注意力機制具良好的模型表達能力,但過高的計算成本限制了其在各種場景中的應用。本文提出了一種新的注意力范式,代理注意力 (Agent Attention),同時具有高效性和很強的模型表達能力。

具體來說,代理注意力在傳統的注意力三元組 (Q,K,V) 中引入了一組額外的代理向量 A,定義了一種新的四元注意力機制 (Q, A, K, V)。其中,代理向量 A 首先作為查詢向量 Q 的代理,從 K 和 V 中聚合信息,然后將信息廣播回 Q。由于代理向量的數量可以設計得比查詢向量的數量小得多,代理注意力能夠以很低的計算成本實現全局信息的建模。
此外,本文證明代理注意力等價于一種線性注意力范式,實現了高性能 Softmax 注意力和高效線性注意力的自然融合。該方法在 ImageNet 上使 DeiT、PVT、Swin Transformer、CSwin Transformer 等模型架構取得了顯著的性能提升,能夠將模型在 CPU 端加速約 2.0 倍、在 GPU 端加速約 1.6 倍。應用于 Stable Diffusion 時,代理注意力能夠將模型生成速度提升約 1.8 倍,并顯著提高圖像生成質量,且無需任何額外訓練。
方法
在本文中,我們創新性地向注意力三元組 (Q,K,V) 引入了一組額外的代理向量 A,定義了一種四元的代理注意力范式 (Q, A, K, V)。如圖 1 (c) 所示,在代理注意力中,我們不會直接計算 Q 和 K 之間兩兩的相似度,而是使用少量的代理向量 A 來收集 K 和 V 中的信息,進而呈遞給 Q,以很低的計算成本實現全局信息的建模。從整體結構上看,代理注意力由兩個常規 Softmax 注意力操作組成,并且等效為一種廣義的線性注意力,實現了高性能 Softmax 注意力和高效線性注意力的自然融合,因而同時具有二者的優點,即:計算復雜度低且模型表達能力強。
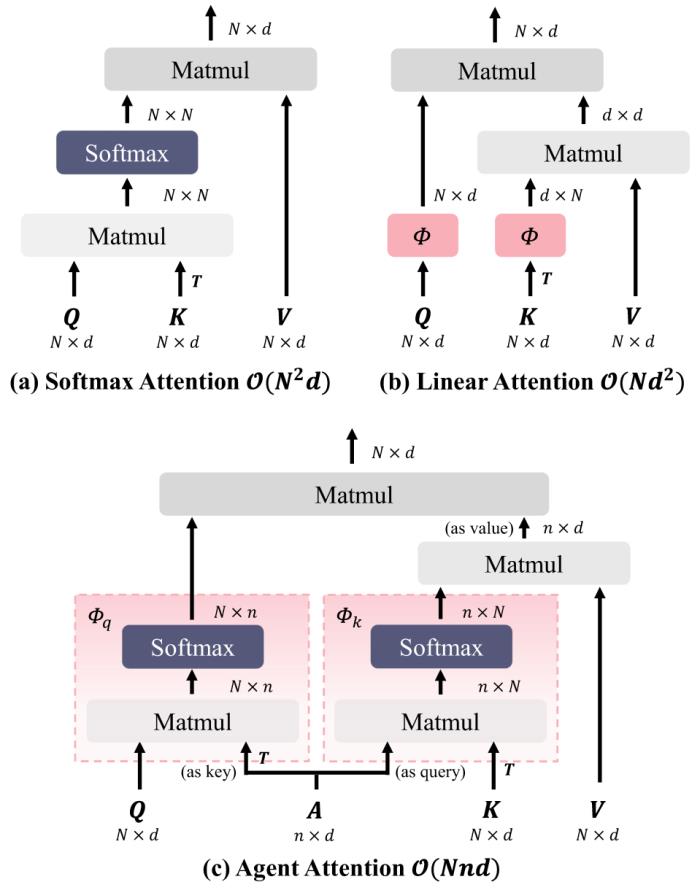
圖 1:Softmax 注意力、線性注意力與代理注意力機制對比
1. 代理注意力

圖 2:代理注意力示意圖
上圖即為代理注意力的示意圖,下面給出具體數學形式。為了書寫方便,我們將 Softmax 注意力和線性注意力分別縮寫為:
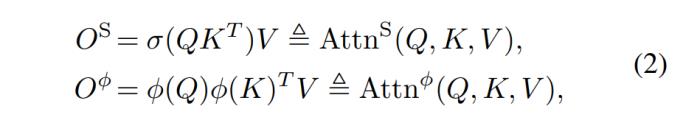
其中,Q,K,V 分別為 Query、Key、Value 矩陣,表示 Softmax 函數,為線性注意力中的映射函數。則代理注意力可以表示為:

另一個等效的表示為:
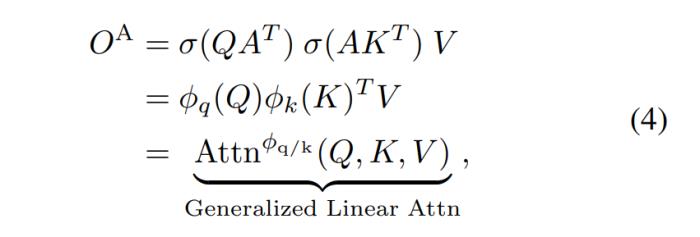
其中 A 為新定義的代理矩陣。
如公式 (3) 和示意圖第一行所示,代理注意力由兩個 Softmax 注意力操作組成,分別為代理特征聚合和廣播。具體來說,我們首先將 A 作為 Query,在 A、K 和 V 之間進行注意力計算,從所有特征中匯聚信息,得到代理特征 。隨后,我們將 A 作為 Key,
。隨后,我們將 A 作為 Key, 作為 Value,和 Q 進行第二次注意力計算,將代理特征中的全局信息廣播回每一個特征,并獲得最終輸出 O。這樣一來,我們避免了 Q 和 K 之間相似度的計算,而是通過代理向量實現了每個 query-key 之間的信息交換。可以看到,在這一計算范式中,少量的代理特征 A 充當了 Q 的 “代理人”—— 從 K 和 V 中收集信息并呈遞給 Q,因而本文將這種注意力機制命名為代理注意力。實際應用中,我們將 A 的數量設置為一個小的超參數 n,從而以線性計算復雜度
作為 Value,和 Q 進行第二次注意力計算,將代理特征中的全局信息廣播回每一個特征,并獲得最終輸出 O。這樣一來,我們避免了 Q 和 K 之間相似度的計算,而是通過代理向量實現了每個 query-key 之間的信息交換。可以看到,在這一計算范式中,少量的代理特征 A 充當了 Q 的 “代理人”—— 從 K 和 V 中收集信息并呈遞給 Q,因而本文將這種注意力機制命名為代理注意力。實際應用中,我們將 A 的數量設置為一個小的超參數 n,從而以線性計算復雜度 實現了全局建模。
實現了全局建模。
值得指出的是,如公式 (4) 和示意圖第二行所示,代理注意力實際上將高性能的 Softmax 注意力和高效的線性注意力融合在了一起,通過使用兩次 Softmax 注意力操作實現了廣義線性注意力范式,其中等效映射函數定義為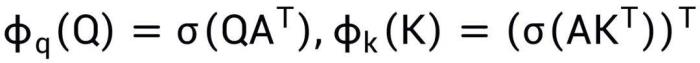 。
。
實際應用中,代理向量可以通過不同的方法獲得,例如設置為一組可學習參數,或通過池化等方式從輸入特征中得到。我們也可以使用更加優越的方法來獲得代理向量,例如 Deformable Points、Token Merging 等。本文中,我們采用簡單的池化來獲取代理向量。
2. 代理注意力模塊
為了更好地發揮代理注意力的潛力,本文進一步做出了兩方面的改進。一方面,我們定義了 Agent Bias 以促進不同的代理向量聚焦于圖片中不同的位置,從而更好地利用位置信息。另一方面,作為一種廣義的線性注意力,代理注意力也面臨特征多樣性不足的問題,因此我們采用一個輕量化的 DWC 作為多樣性恢復模塊。
在以上設計的基礎上,本文提出了一種新的代理注意力模塊,其結構如下圖:
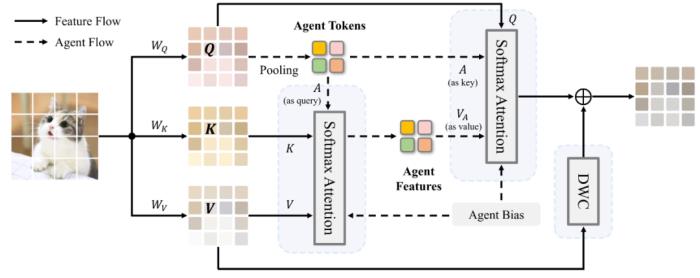
圖 3:代理注意力模塊
結合了 Softmax 注意力和線性注意力的優勢,代理注意力模塊具有以下特點:
(1) 計算復雜度低且模型表達能力強。之前的研究通常將 Softmax 注意力和線性注意力視為兩種不同的注意力范式,試圖解決各自的問題和局限。代理注意力優雅地融合了這兩種注意力形式,從而自然地繼承了它們的優點,同時享受低計算復雜性和高模型表達能力。
(2) 能夠采用更大的感受野。得益于線性計算復雜度,代理注意力可以自然地采用更大的感受野,而不會增加模型計算量。例如,可以將 Swin Transformer 的 window size 由 7^2 擴大為 56^2,即直接采用全局自注意力,而完全不引入額外計算量。
實驗結果
1. 分類任務
代理注意力是一個通用的注意力模塊,本文基于 DeiT、PVT、Swin Transformer、CSwin Transformer 等模型架構進行了實驗。如下圖所示,在 ImageNet 分類任務中,基于代理注意力構建的模型能夠取得顯著的性能提升。例如,Agent-Swin-S 可以取得超越 Swin-B 的性能,而其參數量和計算量不到后者的 60%。
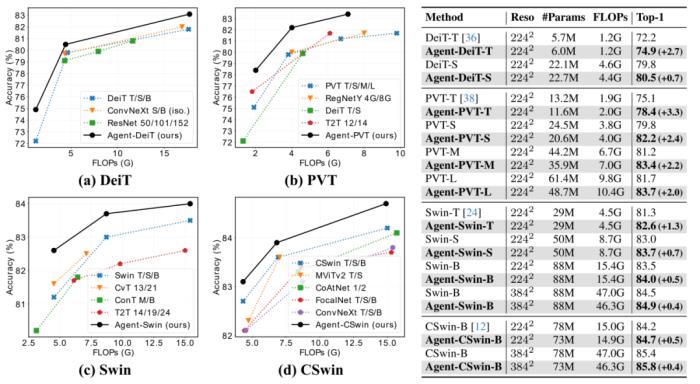
圖 4:ImageNet 圖片分類結果
在實際推理速度方面,代理注意力也具有顯著的優勢。如下圖所示,在 CPU/GPU 端,代理注意力模型能夠取得 2.0 倍 / 1.6 倍左右的加速,同時取得更好的性能。
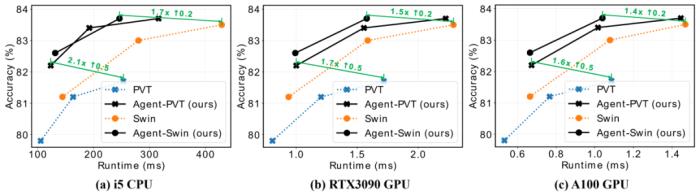
圖 5:實際測速結果
2. 檢測和分割
在檢測和分割任務中,相較于基礎模型,Agent Transformer 也能夠取得十分顯著的性能提升,這在一定程度上得益于代理注意力的全局感受野。
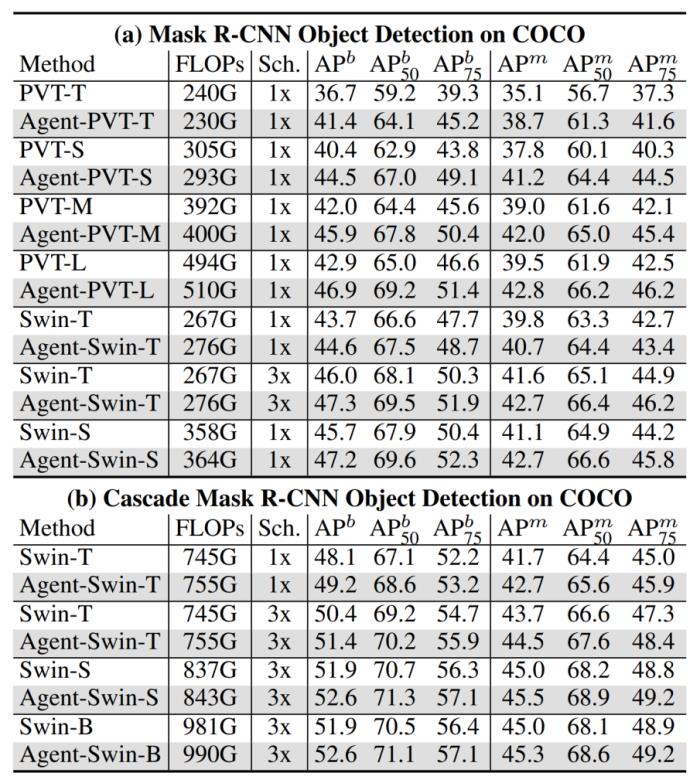
圖 6:COCO 物體檢測與分割結果
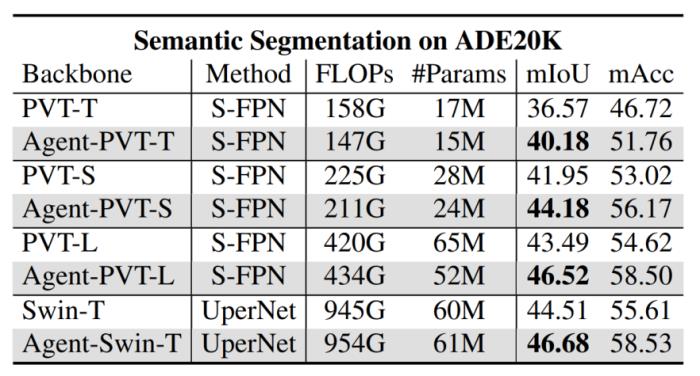
圖 7:ADE20K 語義分割結果
3.Agent Stable Diffusion
特別值得指出的是,代理注意力可以直接應用于 Stable Diffusion 模型,無需訓練,即可加速生成并顯著提升圖片生成質量。如下圖所示,將代理注意力應用于 Stable Diffusion 模型,能夠將圖片生成速度提升約 1.8 倍,同時提升圖片的生成質量。
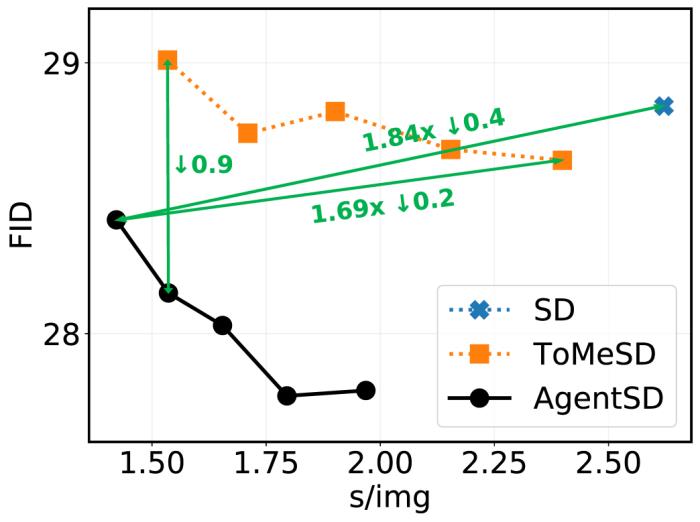
圖 8:Stable Diffusion, ToMeSD 和 AgentSD 的定量化結果
下圖中給出了生成圖片的樣例。可以看到,代理注意力能夠顯著降低 Stable Diffusion 模型生成圖片的歧義和錯誤,同時提升生成速度和生成質量。

圖 9:生成圖片的樣例
4. 高分辨率與大感受野
本文還探究了分辨率和感受野對模型性能的影響。如下圖所示,我們基于 Agent-Swin-T 將窗口大小由 7^2 逐步擴大到 56^2。可以看到,隨著感受野的擴大,模型性能穩步提升。這說明盡管 Swin 的窗口劃分是有效的,但它依然不可避免地損害了模型的全局建模能力。
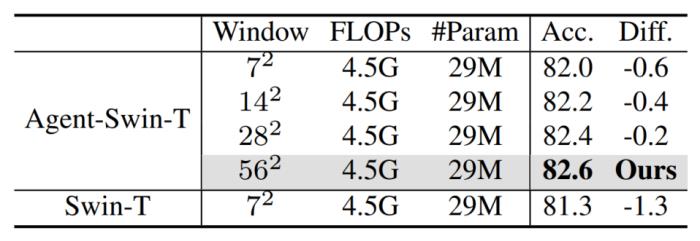
圖 10:感受野大小的影響
下圖中,我們將圖片分辨率由 256^2 逐步擴大到 384^2。可以看到,在高分辨率的場景下,代理注意力模型持續展現出顯著的優勢。
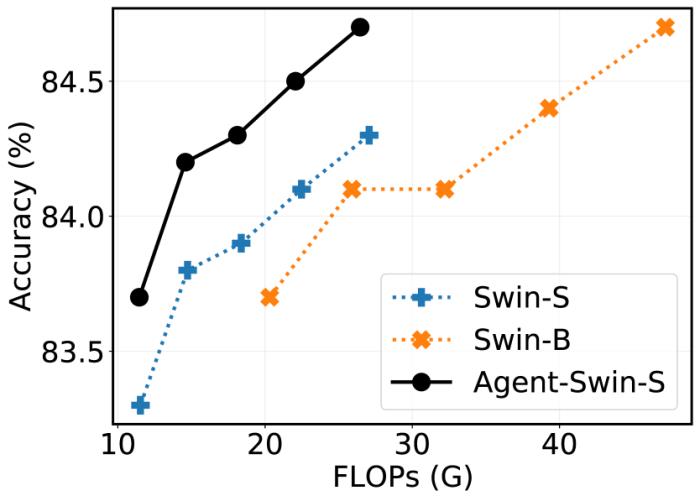
圖 11:高分辨率場景
總結
本文的貢獻主要在三個方面:
(1) 提出了一種新穎、自然、有效且高效的注意力范式 —— 代理注意力,它自然地融合了高性能的 Softmax 注意力和高效的線性注意力,以線性計算量實現有效的全局信息建模。
(2) 在分類、檢測、分割等諸多任務中充分驗證了代理注意力的優越性,特別是在高分辨率、長序列的場景下,這或為開發大尺度、細粒度、面向實際應用場景的視覺、語言大模型提供了新的方法。
(3) 創新性地以一種無需訓練的方式將代理注意力應用于 Stable Diffusion 模型,顯著提升生成速度并提高圖片質量,為擴散模型的加速和優化提供了有效的新研究思路。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
