

 財聯社周子意
2024-11-16
財聯社周子意
2024-11-16 

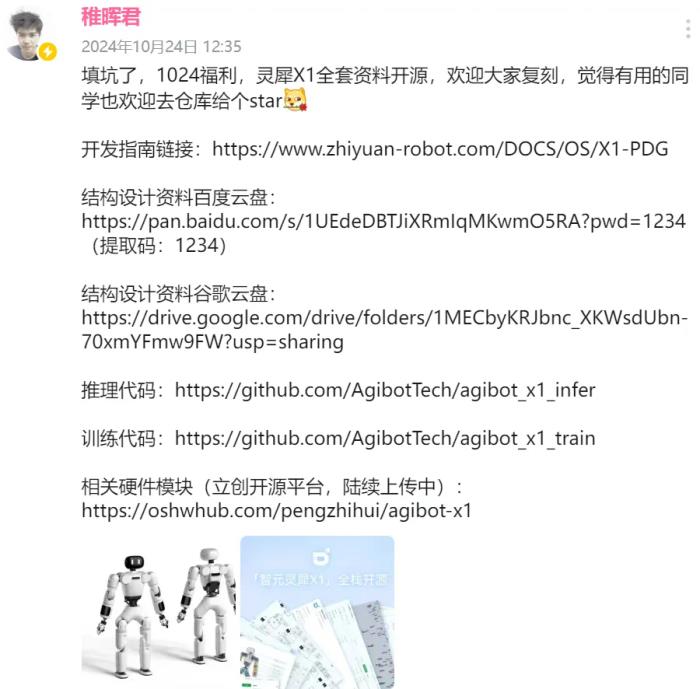
大語言模型并非AI“盡頭”?Meta首席科學家:仍無法企及人類智慧
5月23日訊(編輯 周子意)Meta的首席人工智能(AI)科學家楊立昆(Yann LeCun)認為,現有的大型語言模型(LLM)永遠無法實現像人類一樣的推理和計劃能力。
楊立昆表示,大型語言模型“對邏輯的理解非常有限,它不了解物質世界,沒有持久的記憶,不能以任何合理的術語定義來推理,也不能進行分層規劃”。
在一次最新采訪中,他認為并不能依靠現有的先進大型語言模型來創造出媲美人類智慧的通用人工智能(AGI),因為這些模型只有在獲得了正確的訓練數據的情況下才能準確回答提示,因此“本質上是不安全的”。
具體來說就是,楊立昆認為,目前的大型語言模型盡管在自然語言處理、對話理解、對話交互、文本創作上有著出色的表現,但其仍然只是一種“統計建模”技術,通過學習數據中的統計規律來完成相關任務,本質上并非真正擁有理解和推理能力。
而楊立昆本人則在努力開發全新一代的人工智能系統,他希望該系統將為具有人類智能水平的機器提供動力,在機器中創造“超級智能”。不過他指出,這一愿景可能需要10年才能實現。
“世界建模”方法
楊立昆在Meta的基礎人工智能研究(Fair)實驗室管理著一個約500人的團隊。他們正致力于創造一種能夠形成“常識”的人工智能,并以與人類相似的方式觀察和體驗、并學習世界的運作方式,并最終實現通用人工智能(AGI),這種方法被稱為“世界建模”。
2022年,楊立昆首次發表了一篇關于“世界建模”愿景的論文,此后Meta基于該方法發布了兩個研究模型。
楊立昆最新指出,Fair實驗室正在測試各種想法,希望讓人工智能最終能達到人類的智力水平,然而“這其中有很多不確定性和探索,我們也無法判斷哪個會成功,哪個最終會被選中”。
此外,他還堅定認為,“我們正處于下一代人工智能系統的風口浪尖。”
內部矛盾
然而,這位科學家的實驗性愿景對Meta公司來說是一場代價高昂的賭博,因為目前的投資者更希望看到人工智能投資的快速回報。
也因此,Meta公司內部也出現了關于“短期收入”和“長期價值”之間的觀念分歧。這一點分歧從去年GenAI團隊的成立便可看出。
Meta于2013年成立了Fair實驗室,以開拓人工智能研究領域,并聘請了該領域的頂尖學者。然而在2023年,Meta單獨劃出了一個新的GenAI團隊,由首席產品官Chris Cox領導,該團隊從Fair實驗室挖來了許多人工智能研究人員和工程師,并領導了Llama 3模型的工作,并將其整合到其新的人工智能助手和圖像生成工具等產品中。
一些內部人士認為,GenAI團隊的成立,或許因為楊立昆和Meta首席行政官扎克伯格兩者在理念上存在某種矛盾。在投資者的壓力以及盈利壓力下,扎克伯格一直在推動人工智能的更多的商業化應用;而Fair實驗室內部的學院派文化卻讓Meta在生成式人工智能熱潮中稍顯“弱勢”。
在楊立昆發表這一觀點之際,Meta及其競爭對手正在推進更多增強版本的大型語言模型,包括OpenAI上周發布的更快的GPT-4o模型;谷歌推出了一款新的“多模態”AI助理Project Astra;Meta上月還推出了最新的 Llama 3模型。
對于這些最新的大型語言模型,楊立昆是不屑的,他認為,“大型語言模型的這種進化是膚淺和有限的,只有當人類工程師介入并根據這些信息進行訓練時,模型才會學習,而不是像人類那樣自然地得出結論。”這也相當于在打自家Llama模型的臉。
盡管觀念上存有矛盾,不過有知情人士透露,楊立昆依舊是扎克伯格的核心顧問之一,因為他在人工智能領域享有極大聲譽。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
