

 新火種
2024-11-15
新火種
2024-11-15 


無需訓練即可創建數字人,字節PersonaTalk視頻口型編輯超SOTA
在 AIGC 的熱潮下,基于語音驅動的視頻口型編輯技術成為了視頻內容個性化與智能化的重要手段之一。尤其是近兩年爆火的數字人直播帶貨,以及傳遍全網的霉霉講中文、郭德綱用英語講相聲,都印證著視頻口型編輯技術已經逐漸在行業中被廣泛應用,備受市場關注。
近期,字節跳動一項名為 PersonaTalk 的相關技術成果入選了 SIGGRAPH Asia 2024-Conference Track,該方案能不受原視頻質量的影響,保障生成視頻質量的同時兼顧 zero-shot 技術的便捷和穩定,可以通過非常便捷高效的方式用語音修改視頻中人物的口型,完成高質量視頻編輯,快速實現數字人視頻制作以及口播內容的二次創作。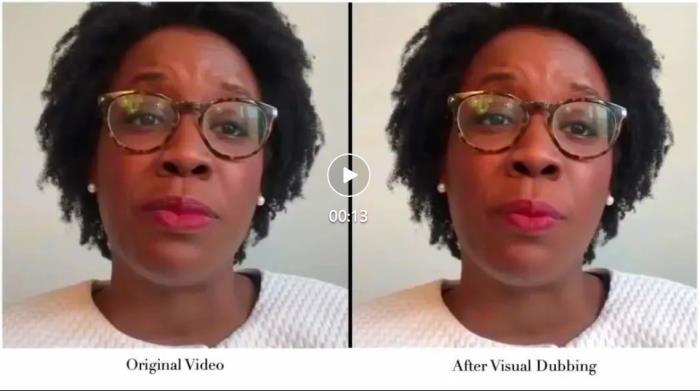
肖像來自學術數據集 HDTF
目前的視頻改口型技術大致可以分為兩類。一類是市面上最常見的定制化訓練,需要用戶首先提供 2-3mins 的人物視頻數據,然后通過訓練讓模型對這段數據中的人物特征進行過擬合,最終實現該數據片段中人物口型的修改。這類方案在效果上相對成熟,但是需要耗費幾個小時甚至幾天的模型訓練時間,成本較高,很難實現視頻內容的快速生產;與此同時,這類方案對人物視頻的質量要求往往偏高,如果視頻中的人物口型動作不標準或者環境變化太復雜,訓練后的效果會大打折扣。除了定制化訓練之外,還有另一類 zero-shot 方案,可以通過大量數據來對模型進行預訓練,讓模型具備較強的泛化性,在實際使用的過程中不需要再針對特定人物去做模型微調,能做到即插即用,成功解決了定制化方案成本高,效果不魯棒的問題。但這類方案大都把重點放在如何實現聲音和口型的匹配上,往往忽略了視頻生成的質量。這會導致一個重要的問題,最終生成的視頻不論是在外貌等面部細節,還是說話的風格,跟本人會有明顯的差異。
PersonaTalk 作為一項創新視頻生成技術,構建了一個基于注意力機制的雙階段框架,實現了這兩類方案優勢的統一。
 論文鏈接:https://arxiv.org/pdf/2409.05379項目網頁:https://grisoon.github.io/PersonaTalk技術方案為了達到上述目標,技術團隊首先用一個風格感知的動畫生成模塊(Style-Aware Geometry Construction)在 3D 幾何空間生成人物的口型動畫序列;然后通過一個雙分支并行的注意力模塊(Dual-Attention Face Rendering)進行人像渲染,生成最終的視頻。
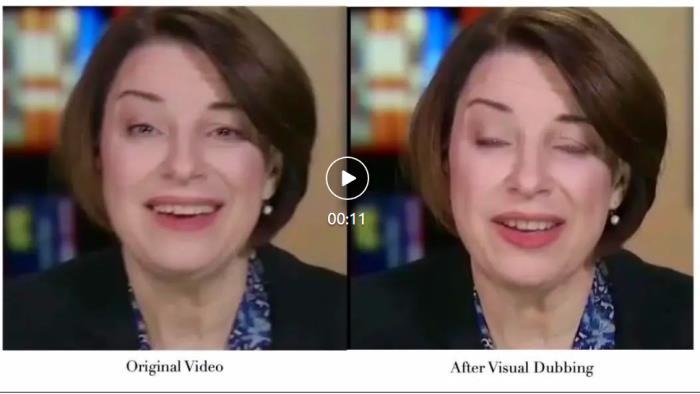
論文鏈接:https://arxiv.org/pdf/2409.05379項目網頁:https://grisoon.github.io/PersonaTalk技術方案為了達到上述目標,技術團隊首先用一個風格感知的動畫生成模塊(Style-Aware Geometry Construction)在 3D 幾何空間生成人物的口型動畫序列;然后通過一個雙分支并行的注意力模塊(Dual-Attention Face Rendering)進行人像渲染,生成最終的視頻。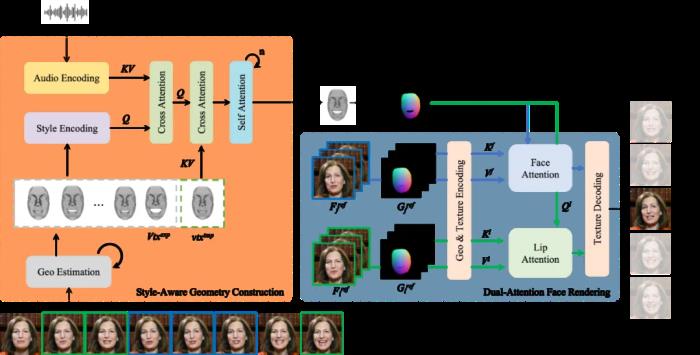 肖像來自學術數據集 HDTFStyle-Aware Geometry Construction:這一階段的目標是在 3D 幾何空間中生成具備人物風格的人臉動畫。除了通過常規的語音信號來控制生成結果,這里還從參考視頻中提取說話者個性化的面部特征并分析出特征的統計特性,通過 Cross Attention 注入到模型中,來引導生成的動畫具備說話者本人的面部運動風格。此外,文中還提出了一種 Hybrid 3D Reconstruction 方案,通過結合深度學習和迭代式優化的方法,來提升人臉三維重建的精度和穩定性。Dual-Attention Face Rendering:在渲染過程中,作者團隊創新性地設計了兩個并行的注意力模塊 Face-Attention 和 Lip-Attention,通過 Cross Attention 來融合 3D 動畫和人物參考圖特征,分別渲染臉部和嘴部的紋理。在推理過程中,文中還針對這兩個模塊分別設計了參考圖挑選策略,其中人臉部分參考圖從以當前幀為中心的一個滑動窗口中來獲取,以此降低人臉紋理的采集和生成難度,確保視頻畫面的穩定性和保真度;口型部分則是先按照口型張幅大小對整個視頻中的人臉進行排序,然后均勻挑選出不同張幅的口型圖片組成一個集合,以確保口腔內的信息可以被完整性獲取。實驗效果對比在實驗章節中,該研究從多個方面詳細對比了 PersonaTalk 和其他市面上 SOTA 方案,以此來證明該方法的有效性。從視頻效果和定量指標上看,PersonaTalk 在唇動同步、視覺質量與個性化特征保留方面均表現突出,明顯優于其他 zero-shot 方法。
肖像來自學術數據集 HDTFStyle-Aware Geometry Construction:這一階段的目標是在 3D 幾何空間中生成具備人物風格的人臉動畫。除了通過常規的語音信號來控制生成結果,這里還從參考視頻中提取說話者個性化的面部特征并分析出特征的統計特性,通過 Cross Attention 注入到模型中,來引導生成的動畫具備說話者本人的面部運動風格。此外,文中還提出了一種 Hybrid 3D Reconstruction 方案,通過結合深度學習和迭代式優化的方法,來提升人臉三維重建的精度和穩定性。Dual-Attention Face Rendering:在渲染過程中,作者團隊創新性地設計了兩個并行的注意力模塊 Face-Attention 和 Lip-Attention,通過 Cross Attention 來融合 3D 動畫和人物參考圖特征,分別渲染臉部和嘴部的紋理。在推理過程中,文中還針對這兩個模塊分別設計了參考圖挑選策略,其中人臉部分參考圖從以當前幀為中心的一個滑動窗口中來獲取,以此降低人臉紋理的采集和生成難度,確保視頻畫面的穩定性和保真度;口型部分則是先按照口型張幅大小對整個視頻中的人臉進行排序,然后均勻挑選出不同張幅的口型圖片組成一個集合,以確保口腔內的信息可以被完整性獲取。實驗效果對比在實驗章節中,該研究從多個方面詳細對比了 PersonaTalk 和其他市面上 SOTA 方案,以此來證明該方法的有效性。從視頻效果和定量指標上看,PersonaTalk 在唇動同步、視覺質量與個性化特征保留方面均表現突出,明顯優于其他 zero-shot 方法。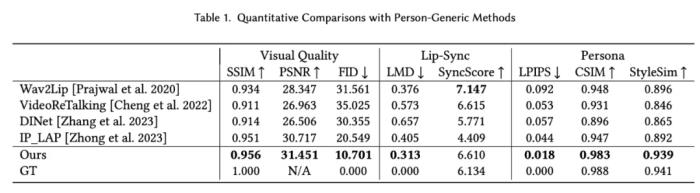
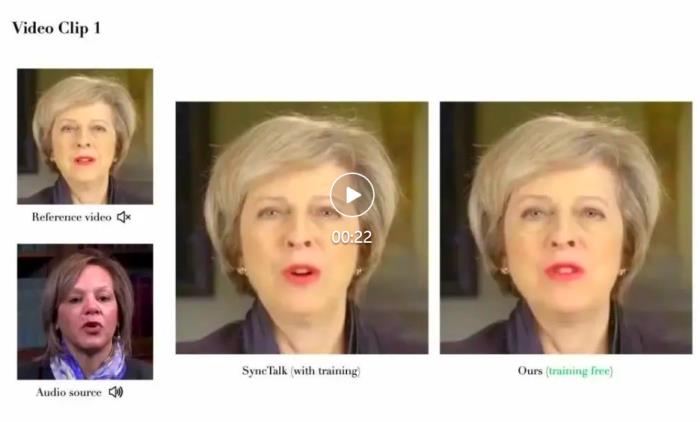
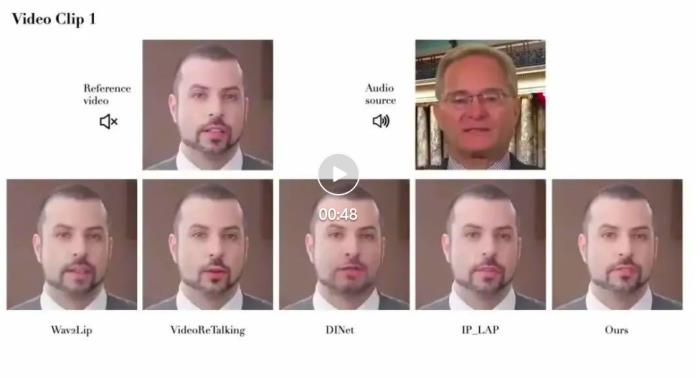 肖像來自學術數據集 HDTF 以及自有版權數據同時,PersonaTalk 作為一個不需要額外訓練和微調的方案,在視頻結果的表現上甚至優于學術界最新的定制化訓練方案。
肖像來自學術數據集 HDTF 以及自有版權數據同時,PersonaTalk 作為一個不需要額外訓練和微調的方案,在視頻結果的表現上甚至優于學術界最新的定制化訓練方案。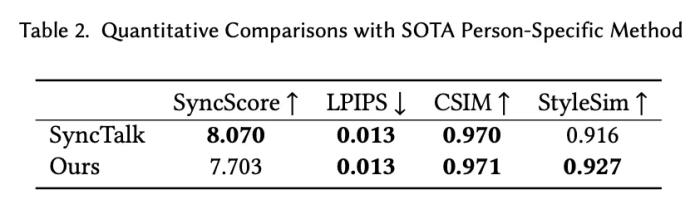
 肖像來自學術數據集 HDTF 及網絡公開數據此外,作者團隊通過對目標用戶進行問卷調查和訪談,收集了對 PersonaTalk 生成內容的反饋,結果顯示大多數用戶對視頻質量感到滿意,認為其足夠逼真且高度還原了人物特征。
肖像來自學術數據集 HDTF 及網絡公開數據此外,作者團隊通過對目標用戶進行問卷調查和訪談,收集了對 PersonaTalk 生成內容的反饋,結果顯示大多數用戶對視頻質量感到滿意,認為其足夠逼真且高度還原了人物特征。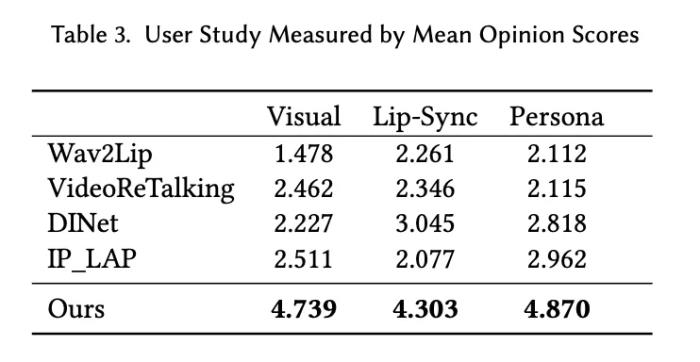 更多應用該項研究可以應用在視頻翻譯、虛擬教師、AIGC 創作等多個場景。以下數據均來自于網絡公開數據或 AIGC 生成。虛擬教師
更多應用該項研究可以應用在視頻翻譯、虛擬教師、AIGC 創作等多個場景。以下數據均來自于網絡公開數據或 AIGC 生成。虛擬教師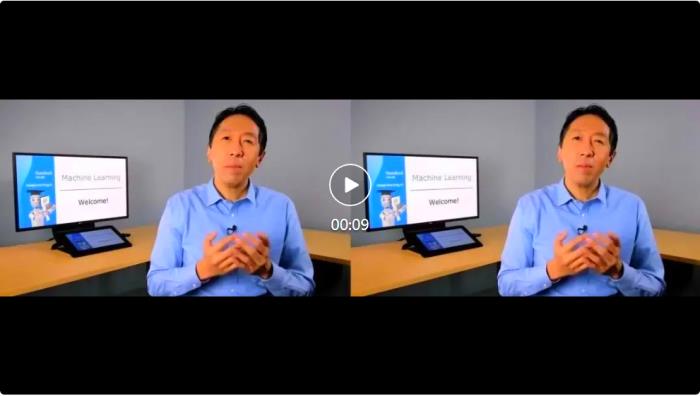
 原視頻 介紹 Deep Learning 課程AIGC 創作
原視頻 介紹 Deep Learning 課程AIGC 創作


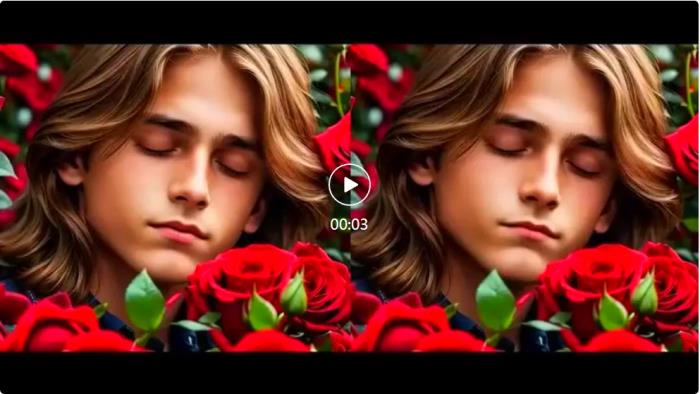 結論PersonaTalk 通過注意力機制的雙階段框架,有效突破了已有視頻口型編輯技術的瓶頸,可以用很低的成本來生成高質量的人物口播視頻,實現了效果和效率的兼顧。PersonaTalk 不僅具有廣泛的應用前景,還為多領域的創新提供了新思路。無論是在娛樂、教育、廣告等行業,都能實現更加個性化和互動式的用戶體驗。隨著技術的不斷發展,相信 PersonaTalk 將使視頻內容以及數字人創作變得更加生動、真實,從而拉近虛擬世界與現實生活之間的距離。通過整合先進的音頻技術和深度學習算法,PersonaTalk 也正在開啟一種全新的視聽交互方式,讓交流變得更加豐富與多元化。安全說明此工作僅以學術研究為目的,會嚴格限制模型的對外開放和使用權限,防止未經授權的惡意利用。文中使用的圖片 / 視頻均已注明來源,如有侵權,請聯系作者及時刪除。團隊介紹字節跳動智能創作數字人團隊,智能創作是字節跳動 AI & 多媒體技術團隊,覆蓋了計算機視覺、音視頻編輯、特效處理等技術領域,借助公司豐富的業務場景、基礎設施資源和技術協作氛圍,實現了前沿算法 - 工程系統 - 產品全鏈路的閉環,旨在以多種形式為公司內部各業務提供業界前沿的內容理解、內容創作、互動體驗與消費的能力和行業解決方案。其中數字人方向專注于建設行業領先的數字人生成和驅動技術,豐富智能創作內容生態。目前,智能創作團隊已通過字節跳動旗下的云服務平臺火山引擎向企業開放技術能力和服務。更多大模型算法相關崗位開放中。
結論PersonaTalk 通過注意力機制的雙階段框架,有效突破了已有視頻口型編輯技術的瓶頸,可以用很低的成本來生成高質量的人物口播視頻,實現了效果和效率的兼顧。PersonaTalk 不僅具有廣泛的應用前景,還為多領域的創新提供了新思路。無論是在娛樂、教育、廣告等行業,都能實現更加個性化和互動式的用戶體驗。隨著技術的不斷發展,相信 PersonaTalk 將使視頻內容以及數字人創作變得更加生動、真實,從而拉近虛擬世界與現實生活之間的距離。通過整合先進的音頻技術和深度學習算法,PersonaTalk 也正在開啟一種全新的視聽交互方式,讓交流變得更加豐富與多元化。安全說明此工作僅以學術研究為目的,會嚴格限制模型的對外開放和使用權限,防止未經授權的惡意利用。文中使用的圖片 / 視頻均已注明來源,如有侵權,請聯系作者及時刪除。團隊介紹字節跳動智能創作數字人團隊,智能創作是字節跳動 AI & 多媒體技術團隊,覆蓋了計算機視覺、音視頻編輯、特效處理等技術領域,借助公司豐富的業務場景、基礎設施資源和技術協作氛圍,實現了前沿算法 - 工程系統 - 產品全鏈路的閉環,旨在以多種形式為公司內部各業務提供業界前沿的內容理解、內容創作、互動體驗與消費的能力和行業解決方案。其中數字人方向專注于建設行業領先的數字人生成和驅動技術,豐富智能創作內容生態。目前,智能創作團隊已通過字節跳動旗下的云服務平臺火山引擎向企業開放技術能力和服務。更多大模型算法相關崗位開放中。 相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
