

 新火種
2024-11-15
新火種
2024-11-15 


中國科大、科大訊飛團隊開發ChemEval:化學大模型多層次多維度能力評估的新基準

編輯 | ScienceAI
近日,認知智能全國重點實驗室、中國科學技術大學陳恩紅教授團隊,科大訊飛研究院 AI for Science 團隊發布了論文《ChemEval: A Comprehensive Multi-Level Chemical Evaluation for Large Language Models》,介紹了新研發的一個面向化學領域大模型能力的多層次多維度評估框架 ChemEval。

論文鏈接:https://arxiv.org/pdf/2409.13989
項目鏈接: https://github.com/USTC-StarTeam/ChemEval
研究動機
在自然語言處理(NLP)的領域中,大語言模型(LLMs)已經成為推動語言理解與生成能力不斷進步的強大引擎。隨著這些模型在多樣化垂直領域應用的興起,探索如何將它們應用于科學研究,已成為研究的熱點。
對于化學領域,化學是一門深奧的學科,涉及復雜的分子結構、物質性質、反應機制等,這些特點使得 LLMs 在化學領域的應用充滿挑戰和機遇。
盡管 LLMs 在處理文本數據方面取得了令人矚目的成就,但它們在化學領域的應用卻面臨著一系列獨特的挑戰。
化學領域的專業術語眾多,分子間相互作用復雜,且需要對高等化學領域知識有深刻理解。這些挑戰凸顯了對 LLMs 進行系統評估的必要性,以便準確衡量它們在化學領域的實際能力,并識別出潛在的應用領域。
目前盡管已經存在一些基準測試,如 MMLU 涵蓋了包括化學在內的多個領域共 57 項測評任務,但這些測試大部分僅僅面向基礎概念的問答,缺乏對化學領域更深層次能力的評估。
此外,盡管如 ChemLLMbench 等基準在化學任務上相比 MMLU 更為專業,但是該基準仍然缺少對大模型高階能力的評估,如分子理解、化學知識推演等。
針對這一現狀,這篇文章構建了 ChemEval ——一個專門為化學領域設計的多維度能力評估體系。
ChemEval 的開發基于一個核心理念:需要一個能夠全面評估 LLMs 在化學領域能力的基準測試,它不僅能考察大模型對化學基礎知識的掌握,還能評估在高級化學概念方面的理解和應用。
ChemEval 通過一系列精心構建的多級任務,旨在全面評估 LLMs 在化學領域的能力。這些任務設計覆蓋了從化學研究領域的基礎問題到高級挑戰,如分子結構理解、化學反應預測和科學知識推斷等。
ChemEval 不僅能夠為化學領域中的 LLMs 應用提供寶貴的評估和見解,還能為未來模型的優化和應用開辟新的道路。
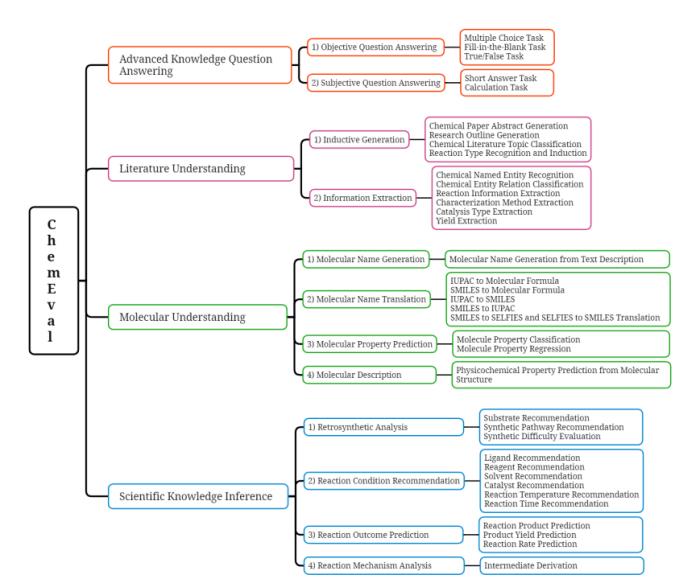
圖 1:Overview of ChemEval。
基準的介紹和構建
在這項研究中建立了一個名為 ChemEval 的基準,專門用于評估化學領域內的大語言模型能力,以填補當前化學領域缺乏多層級、多維度任務體系測評基準的空白。
該基準框架包括化學領域能力的四個級別,每個級別涉及多個化學測評維度,確保對 LLM 的全面評估。ChemEval 通過一系列精心設計的任務來衡量大模型理解和推斷化學知識的能力。
高等知識問答
「高等知識問答」維度旨在評估模型對核心化學概念和原理的理解能力。包括客觀問答和主觀問答兩個維度,共 5 個不同的任務,評估模型在化學術語、定量分析等領域的洞察力。
其中,客觀問答通過多項選擇、填空題等任務評估模型的基本知識掌握程度。此外,主觀問答要求模型提供詳細的解決方案或理由,反映其對化學原理的理解和應用能力。
文獻理解
「文獻理解」維度用于評估模型從科學文獻中提取關鍵信息和歸納總結的能力,包括信息抽取和歸納生成兩個維度,共 15 項任務。
信息提取任務涉及識別化學實體、反應底物和催化類型等,確保模型能夠定位和抽取文本中的化學信息。歸納生成任務要求模型根據現有數據和知識生成總結性的內容,如文獻摘要和反應類型識別歸納等。
分子理解
「分子理解」維度考察模型在分子水平上的理解和生成能力。包括分子名稱生成、分子名稱翻譯、分子性質預測和分子描述四個維度,共 9 項任務。
分子名稱生成任務評估模型生成有效化學結構表示的能力。分子名稱翻譯任務通過模型在不同格式之間轉換分子名稱,評估模型理解各種格式的分子名稱以及互譯的能力。分子特性預測任務關注分子的物理、化學等屬性的知識掌握能力。分子描述任務則評估模型從分子結構中預測物理化學性質的能力。
科學知識推演
「科學知識推演」維度重點評估模型在化學研究中的推理和創新能力,包括逆合成分析、反應條件推薦、反應結果預測和反應機制分析四個關鍵維度,共13項任務。逆合成分析任務評估模型合成路徑的分析規劃能力。
反應條件推薦任務用于評估特定化學反應條件推薦的準確性。反應結果預測任務旨在評估模型預測化學反應結果的能力。反應機制分析任務考察模型從反應物轉化為產物的步驟分析能力。
綜上所述,ChemEval 通過精心設計的任務和數據集,覆蓋了化學研究的多個層面。如圖 1 所示,ChemEval 包含化學領域的 4 個關鍵層級,評估了 12 個維度的 LLMs 能力,涵蓋了 42 個獨特的化學任務。
這些任務由開源數據和化學專家精心設計的數據構成,確保了任務的實用價值,并能有效評估 LLMs 的能力。
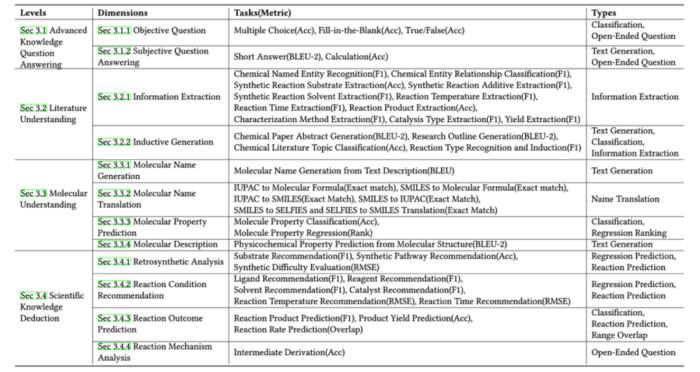
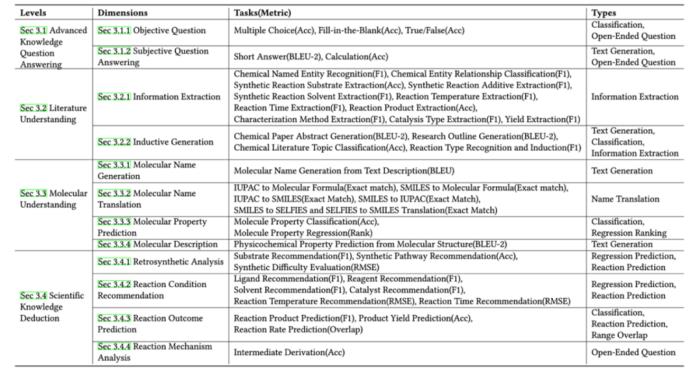
圖 2:任務層級及任務類型。
數據集構建過程
這項研究對大模型進行了全面的評估工作,其中數據來源主要包括開源數據和領域專家數據。開源數據通過關鍵詞檢索并下載相關的開源數據集,從中篩選化學評估方向的下游任務,并下載這些任務的官方數據集。
同時,領域專家從科學文獻、專業教材以及化學實驗數據中手動構建了部分任務類型對應的問答對。
在數據處理階段,需要對化學領域原始數據進行了仔細篩選和過濾,以適應多樣的任務需求。
對于高級知識問答,主要從本科和研究生教材及教輔材料中編制了廣泛的問答對,涵蓋有機化學、無機化學、材料化學等七個類別,確保化學概念和原理的多樣性。
對于文獻理解,從科學文獻中提取相關片段和問題,結合任務特定答案創建測試集。分子理解和科學知識推演則結合開放數據集與實驗室專有數據,設計測試集以滿足下游任務的評估需求。
實驗結果
在 ChemEval 的基準測試中,一共評估了 12 個主流的 LLMs,包括 8 個通用模型和 4 個化學領域模型。
實驗結果表明,盡管像 GPT-4 和 Claude-3.5 這樣的通用 LLMs 在文獻理解和指令遵循方面表現出色,但它們在需要高級化學知識的任務上表現不佳。
相反,化學的領域 LLMs 表現出更強的化學能力,但它們的文獻理解能力有所下降。
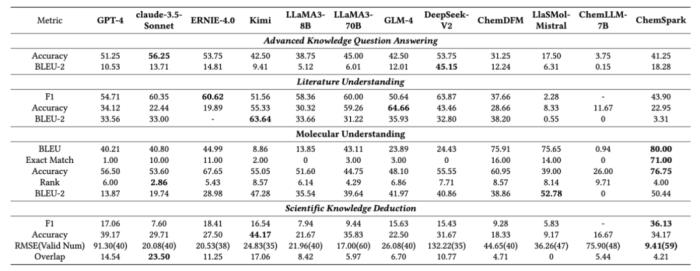
圖 3:主要實驗結果。
此外,還有以下相關結論:
化學領域模型在需要深層化學知識的任務上優于通用模型。大語言模型也難以在沒有嚴格格式化約束的情況下一致地生成準確的化學公式。化學領域模型在遵循指令方面的能力明顯低于通用模型。??更多詳細的任務的設計、評估指標以及各個子任務的實驗結果,歡迎查看 ChemEval 原文。這項工作不僅為化學研究中 LLMs 的應用提供了寶貴的見解,還為未來 LLMs 在化學領域的優化和應用提供了指導。
團隊介紹
認知智能全國重點實驗室(主頁:https://cogskl.iflytek.com/)是由科大訊飛股份有限公司和中國科學技術大學聯合共建的國家級科研平臺,2022 年 5 月,成為科技部遴選的首批 20 家全國重點實驗室之一。開展包括大模型在內的認知智能共性基礎問題研究和前沿技術攻關。
科大訊飛研究院,成立于 2005 年,是科大訊飛旗下專注于人工智能核心技術研究的機構。研究院在智能語音、計算機視覺、自然語言處理等領域積累了豐富的研究成果,并在業界保持領先地位。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
