國(guó)際最新AI基準(zhǔn)測(cè)試SPECML首提模算效率,填補(bǔ)大模型計(jì)算效率評(píng)測(cè)空白
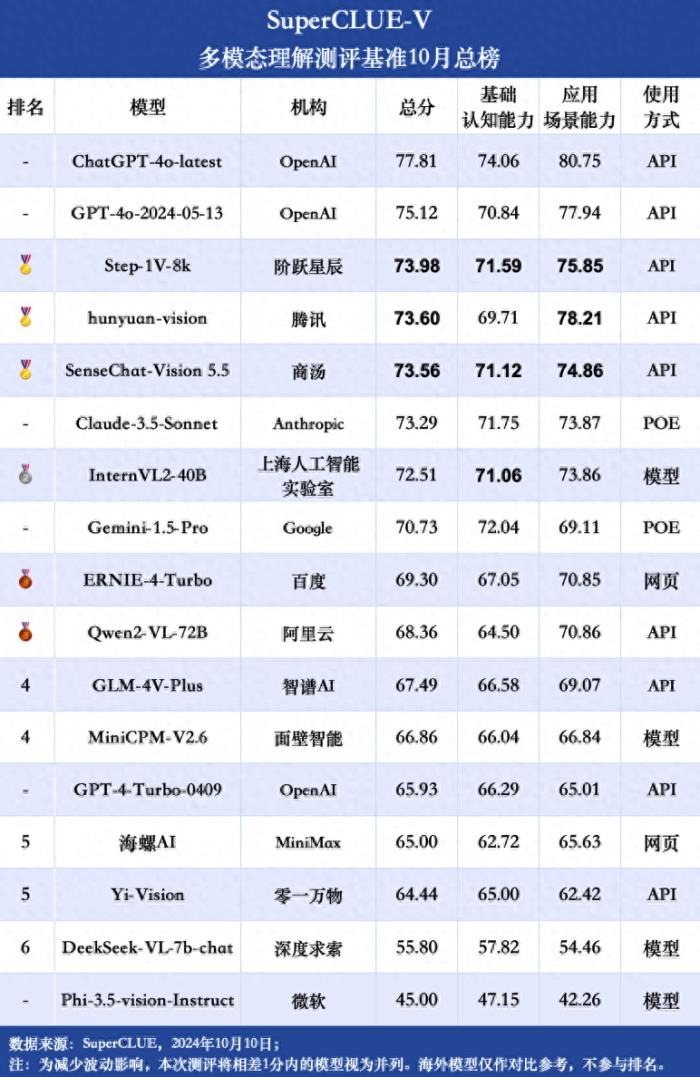
北京2025年1月8日 /美通社/ -- 日前,國(guó)際標(biāo)準(zhǔn)性能評(píng)估組織SPEC公布了AI基準(zhǔn)測(cè)試SPEC ML最新進(jìn)展,該基準(zhǔn)已完成面向不同AI負(fù)載下的軟硬件系統(tǒng)的性能、擴(kuò)展性和模算效率三大關(guān)鍵指標(biāo)構(gòu)建。其中模算效率首次納入SPEC ML基準(zhǔn)評(píng)測(cè),將填補(bǔ)大模型計(jì)算效率評(píng)測(cè)基準(zhǔn)領(lǐng)域的研究空白。隨著人工智