

 新火種
2024-11-15
新火種
2024-11-15 


EvaluationisAllYouNeed!首個開源多模態(tài)大模型通用評測器LLaVA-Critic
作者介紹:本文作者來自于字節(jié)跳動和馬里蘭大學。其中第一作者為馬里蘭大學博士生熊天翼,主要研究領域為計算機視覺,多模態(tài)基礎大模型;通訊作者為 Chunyuan Li (https://chunyuan.li/)。本文作者也包括馬里蘭大學博士生王璽堯,字節(jié)跳動研究員 Dong Guo、Qinghao Ye、Haoqi Fan、Quanquan Gu, 馬里蘭大學教授 Heng Huang。引言:Evaluation is All You Need隨著對現(xiàn)有互聯(lián)網數(shù)據(jù)的預訓練逐漸成熟,研究的探索空間正由預訓練轉向后期訓練(Post-training),OpenAI o1 的發(fā)布正彰顯了這一點。而 Post-training 的核心在于評測(Evaluation)。可靠的 AI 評測不僅能在復雜任務的評測中提供可擴展的解決方案,減少人工勞動,還能在強化學習中生成有效的獎勵信號并指導推理過程。例如,一個 AI 評測器可以遵循用戶設計的評分標準,在視覺對話任務中為不同模型的回復(model response)提供 1 到 10 的評分。除了評分外,它還會提供相應的給分理由,確保模型性能評測的透明性和一致性。來自字節(jié)跳動和馬里蘭大學的研究團隊發(fā)布了首個用于多任務評測的開源多模態(tài)大模型 LLaVA-Critic,旨在啟發(fā)社區(qū)開發(fā)通用大模型評測器(generalist evaluator)。


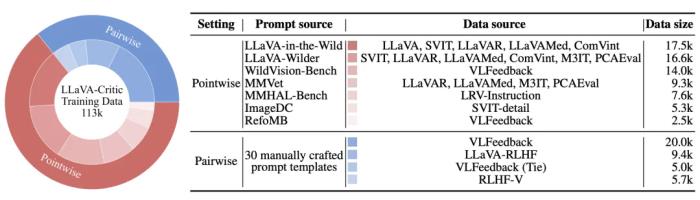
在評分的整體分布和對回復模型 (response model) 的排序層面上,LLaVA-Critic 均展現(xiàn)了與 GPT-4o 的一致性
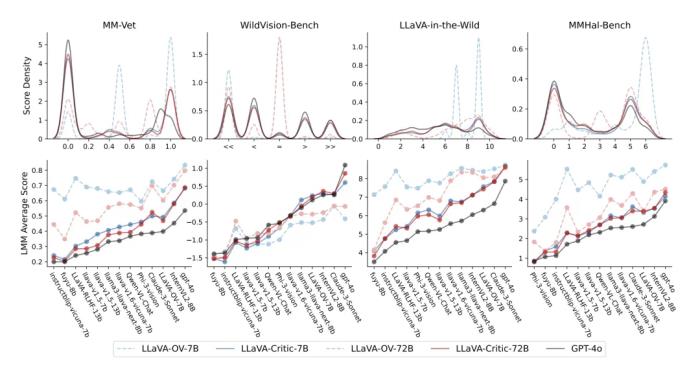
如上圖所示,在單點評分的評估任務中,LLaVA-Critic 大幅超越其基礎模型 LLaVA-OneVision—— 在多個開放式問答評估基準上,其評分一致性和模型排序與 GPT-4o 高度吻合。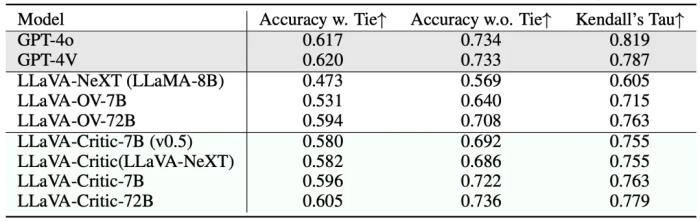
上表展示了 LLaVA-Critic 在 MLLM-as-a-Judge 基準測試中的表現(xiàn),該測試包括了訓練數(shù)據(jù)中未見過的更廣泛評測場景。面對全新的評測任務,LLaVA-Critic 也顯著縮小了開源模型與 GPT-4o/4V 在評測準確性上的差距,充分展現(xiàn)其泛化性與通用性。在上述實驗結果中,72B 模型的表現(xiàn)優(yōu)于 7B 模型,Critic-7B 的表現(xiàn)也優(yōu)于使用弱化版本評測數(shù)據(jù)訓練的 Critic-7B(v0.5)—— 這進一步強調了模型擴展(model scaling)和數(shù)據(jù)擴展(data scaling)在構建通用評測器中的重要性。
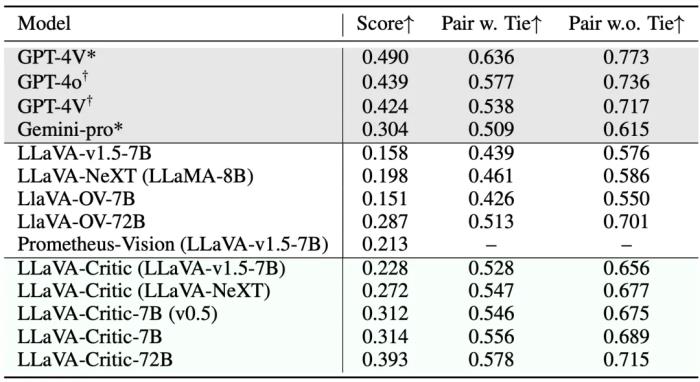
在這個成對排序示例中,LLaVA-Critic 能夠準確識別輸入圖像的內容(手寫數(shù)字 「7」),并基于回復間的差異做出判斷,給出了和人類評估者一致的排序,并提供了清晰的理由說明。后者(評分理由)對于構建可靠人工智能至關重要,它使 LLaVA-Critic 的評測過程更透明,評測結果更可信。場景二:偏好學習(Preference Learning)LLaVA-Critic 的評測能力也可用于比較成對模型回復的好壞,從而作為獎勵信號應用于 RLHF 和 DPO 等強化學習算法。實驗中,該團隊將 LLaVA-Critic 用于迭代直接偏好優(yōu)化( iterative DPO)算法,具體方式如下:給定一個預訓練 LMM 和一組圖片 - 問題輸入,首先讓 LMM 對每一個圖片 - 問題輸入隨機生成 K=5 個候選回復,由此構建出 Kx (K-1)=20 個成對回復。接著,使用 LLaVA-Critic 對這 20 個回復對進行成對排序,選出最好和最壞的回復,形成成對的反饋數(shù)據(jù)集。之后,使用這一數(shù)據(jù)集對于預訓練 LMM 進行直接偏好優(yōu)化(DPO)訓練。在此基礎上,漸進式迭代這一過程共計 M 輪,每次使用最新訓練的模型生成候選回復,最終得到與 LLaVA-Critic 反饋對齊的模型。該團隊采用 LLaVA-OneVision 作為初始 LMM,進行 3 輪 iterative DPO 訓練,最終將訓練后的模型命名為 LLaVA-OneVision-Chat。隨后,他們在多個開放式問答評測基準上測試了最終模型的表現(xiàn),以比較 LLaVA-Critic 和其他獎勵模型的效果。如上表所示,無論是在 7B 還是 72B 基礎模型上,LLaVA-Critic(AI 反饋)均超越了 LLaVA-RLHF (人類反饋),顯著提升了基礎模型在 6 個多模態(tài)開放式問答評測基準上的表現(xiàn)。下方的柱狀圖進一步直觀展示了 LLaVA-Critic 的反饋對 LLaVA-OneVision 模型在視覺問答性能上的提升效果。可見,LLaVA-Critic 作為一種提供有效獎勵信號的可擴展方案,不僅減少了對昂貴人工反饋的依賴,還通過 AI 生成的反饋進一步優(yōu)化了模型的偏好對齊效果。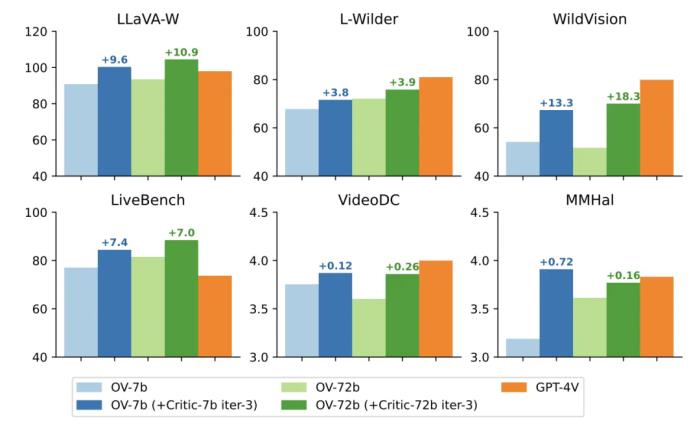
結論LLaVA-Critic 是首個通用的開源多模態(tài)大模型評測器,能夠在多個開放式多模態(tài)場景中評測模型表現(xiàn)。為實現(xiàn)這一目標,研究團隊精心構建了一個高質量的評測指令遵循數(shù)據(jù)集,涵蓋多樣化的評測任務與標準。實驗中展示了 LLaVA-Critic 在兩個關鍵領域的有效性:1.作為通用的評測器,LLaVA-Critic 能夠為需要評測的模型回復提供單點評分和成對排序,這些評分和排序與人類和 GPT-4o 的偏好高度一致,為自動評測多模態(tài)大模型的開放式回復提供了一個可行的開源替代方案。2. 在偏好學習方面,LLaVA-Critic 提供的偏好信號能有效提升多模態(tài)大模型的視覺對話能力,甚至超越了基于人類反饋的 LLaVA-RLHF 獎勵模型。這項工作在利用開源多模態(tài)大模型自身的評價能力方面,邁出了重要的一步。我們期待更多的研究可以由此出發(fā),通過探究更具可擴展性的,超越人類的對齊反饋機制,進一步推動多模態(tài)大模型的發(fā)展。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
