

 新火種
2024-06-17
新火種
2024-06-17 


全華人團(tuán)隊(duì)推出多模態(tài)大模型新基準(zhǔn),GPT-4o準(zhǔn)確率僅為65.5%
GPT-4o再次掀起多模態(tài)大模型的浪潮。
如果他們能以近似人類的熟練程度,在不同領(lǐng)域執(zhí)行廣泛的任務(wù),這對(duì)許多領(lǐng)域帶來(lái)革命性進(jìn)展。
因而,構(gòu)建一個(gè)全面的評(píng)估基準(zhǔn)測(cè)試就顯得格外重要。然而評(píng)估大型視覺(jué)語(yǔ)言模型能力的進(jìn)程顯著落后于它們自身的發(fā)展。
來(lái)自上海AI Lab、香港大學(xué)、上海交大、浙江大學(xué)等多家機(jī)構(gòu)提出了 MMT-Bench。

這是一個(gè)全方位的多模態(tài)基準(zhǔn)測(cè)試,旨在全面評(píng)估大型視覺(jué)語(yǔ)言模型(LVLMs)在多模態(tài)多任務(wù)理解方面的表現(xiàn)。
研究團(tuán)隊(duì)還對(duì)當(dāng)前幾個(gè)代表的視覺(jué)大模型進(jìn)行了能力評(píng)估,結(jié)果發(fā)現(xiàn)感知錯(cuò)誤、推理錯(cuò)誤是所有模型最常見的兩大錯(cuò)誤。
多模態(tài)多任務(wù)AGI基準(zhǔn)測(cè)試MMT-Bench
MMT-Bench的廣度體現(xiàn)在三個(gè)方面。
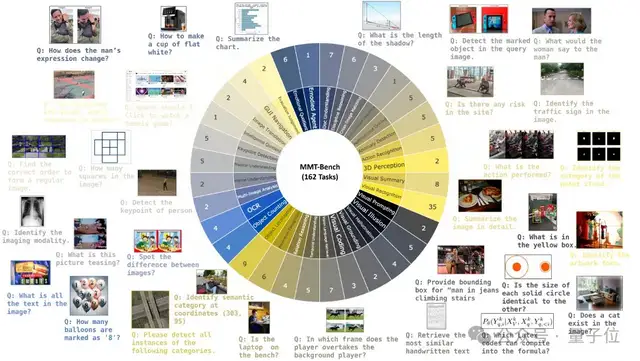
首先,MMT-Bench數(shù)據(jù)經(jīng)過(guò)精心設(shè)計(jì),包含32K個(gè)多選視覺(jué)語(yǔ)言問(wèn)題,涵蓋了32個(gè)核心元任務(wù)和162個(gè)子任務(wù),這比此前的評(píng)測(cè)數(shù)據(jù)集MMBench大8.1倍。
其次,MMT-Bench包含了13種圖像類型,如自然場(chǎng)景、合成圖像、深度圖、富文本圖像、繪畫、屏幕截圖、點(diǎn)云、醫(yī)學(xué)圖像等。這樣的圖片多樣性要求模型能夠解釋理解各種視覺(jué)輸入。
第三,MMT-Bench涵蓋了多種多模態(tài)情景,如車輛駕駛、GUI導(dǎo)航和具身AI,測(cè)試了14種多模態(tài)能力,包括視覺(jué)識(shí)別、定位、推理、OCR、計(jì)數(shù)、3D感知、時(shí)間理解等。
構(gòu)建評(píng)測(cè)任務(wù) 。
MMT-Bench的評(píng)測(cè)任務(wù)在構(gòu)建時(shí)旨在包含盡可能多的多模態(tài)任務(wù)。為此,研究人員首先提出多模態(tài)理解的元任務(wù)。然后,通過(guò)去重和篩選重要任務(wù)總結(jié)出32個(gè)元任務(wù)。
接著,將每個(gè)元任務(wù)分解為幾個(gè)子任務(wù)。子任務(wù)是否被保留在MMT-Bench中,需要滿足三個(gè)標(biāo)準(zhǔn):
1、子任務(wù)是否檢驗(yàn)了基本的多模態(tài)能力;2、子任務(wù)對(duì)當(dāng)前的大型視覺(jué)語(yǔ)言模型(LVLMs)是否具備挑戰(zhàn)性;3、子任務(wù)的測(cè)試樣本是否可以公開獲取。
經(jīng)過(guò)選擇,MMT-Bench共包含了162個(gè)子任務(wù),這比之前任務(wù)最多的評(píng)測(cè)集TinyLVLM-eHub大3.8倍。
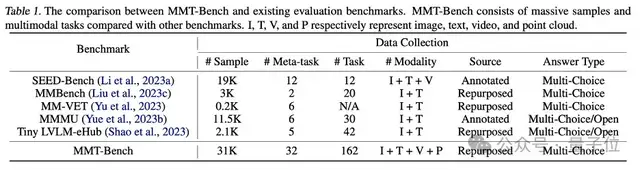
MMT-Bench與此前評(píng)測(cè)數(shù)據(jù)的詳細(xì)比較如下表所示。
數(shù)據(jù)收集。
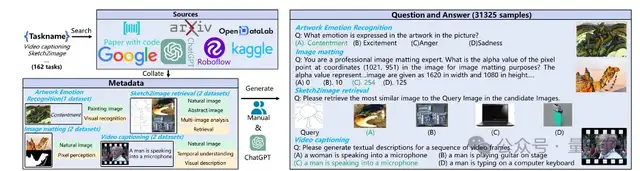
MMT-Bench的研究人員設(shè)計(jì)了一個(gè)高效的數(shù)據(jù)收集流程,以構(gòu)建每個(gè)子任務(wù)的多選視覺(jué)語(yǔ)言問(wèn)題評(píng)估數(shù)據(jù)。
首先,他們通過(guò)Google、Paper With Code、Kaggle和ChatGPT等多種數(shù)據(jù)來(lái)源,根據(jù)子任務(wù)的名稱全面搜索相關(guān)數(shù)據(jù)集。下載數(shù)據(jù)集后,再細(xì)致地評(píng)估它們是否適合評(píng)估子任務(wù),確保數(shù)據(jù)集的可用性和相關(guān)性。
接著,研究人員定義了一種統(tǒng)一的元數(shù)據(jù)格式,用于整理下載的數(shù)據(jù)集。每個(gè)元數(shù)據(jù)樣本包括圖像和元信息,其中元信息包括生成評(píng)測(cè)問(wèn)題和答案所需的必要信息,以及所需推理能力的標(biāo)注信息和視覺(jué)圖片的類型。
為了提高評(píng)估效率,在每個(gè)任務(wù)中,研究人員通過(guò)隨機(jī)抽樣將樣本數(shù)量最大限制為200,并且每個(gè)數(shù)據(jù)集包含相同數(shù)量的樣本。
最后,對(duì)于每個(gè)子任務(wù),研究人員從它們的元數(shù)據(jù)中生成多選視覺(jué)語(yǔ)言問(wèn)題及其選項(xiàng)和答案。具體來(lái)說(shuō),根據(jù)特定任務(wù),研究人員或手動(dòng)設(shè)計(jì)規(guī)則,或使用ChatGPT來(lái)進(jìn)行高質(zhì)量的QA生成。
例如,在基于草圖進(jìn)行圖像檢索的任務(wù)中,使用對(duì)應(yīng)的圖像作為正確答案,并從元數(shù)據(jù)中隨機(jī)抽取其他圖像來(lái)生成錯(cuò)誤選項(xiàng)。而在生成視頻描述的任務(wù)中,則使用ChatGPT編寫容易混淆的錯(cuò)誤選項(xiàng)。
綜上,MMT-Bench共包含31,325個(gè)精心設(shè)計(jì)的多選問(wèn)題,涵蓋13種輸入圖像類型,如自然場(chǎng)景、合成圖像、富文本圖像、醫(yī)學(xué)圖像等,覆蓋32個(gè)核心元任務(wù)和162個(gè)子任務(wù),用于多任務(wù)多模態(tài)理解。
與之前的LVLMs基準(zhǔn)測(cè)試相比,MMT-Bench中的問(wèn)題涵蓋了多種多模態(tài)場(chǎng)景,如GUI導(dǎo)航和文檔理解,測(cè)試了包括視覺(jué)識(shí)別、定位、推理、OCR、計(jì)數(shù)、3D感知、時(shí)間理解等14種能力。這些特點(diǎn)確保MMT-Bench滿足評(píng)估多任務(wù)AGI的任務(wù)廣度要求。
評(píng)測(cè)結(jié)果
研究人員基于MMT-Bench對(duì)30種公開可用的大型視覺(jué)語(yǔ)言模型(LVLMs)進(jìn)行了綜合評(píng)估。
結(jié)果顯示MMT-Bench的基準(zhǔn)測(cè)試給現(xiàn)有的LVLMs帶來(lái)了重大挑戰(zhàn),即使是InternVL-Chat、GPT-4o和GeminiProVision等先進(jìn)模型,其準(zhǔn)確率也僅分別為63.4%、65.5%和61.6%。
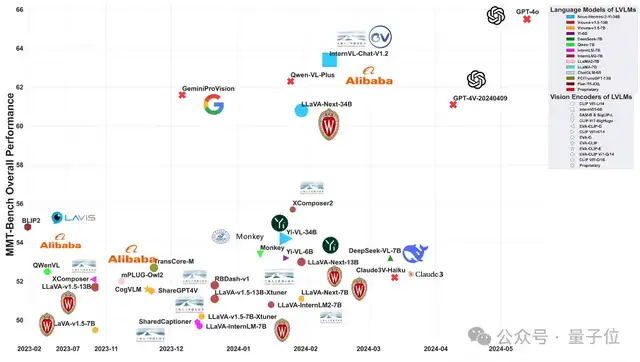
綜合而言,閉源的專有模型GPT-4o目前在MMT-Bench中取得了領(lǐng)先地位,超過(guò)了InternVL-chat、QWen-VL-Plus、GPT-4V和GeminiProVision等其他模型。
值得注意的是,開源模型InternVL-chat和QwenVL-Max正緊隨GPT-4o之后,這為未來(lái)開源社區(qū)模型能與閉源專有模型競(jìng)爭(zhēng)甚至超越它們的前景增添了信心。
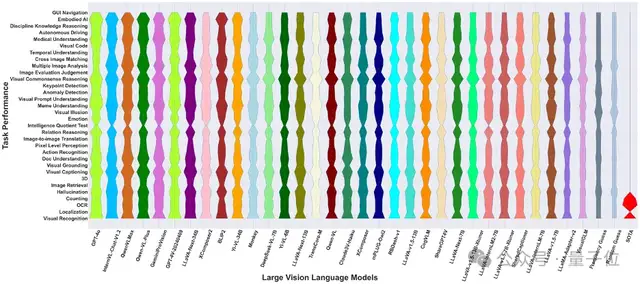
在所有元任務(wù)的評(píng)測(cè)結(jié)果中,研究人員還發(fā)現(xiàn):
1)大多數(shù)大型視覺(jué)語(yǔ)言模型在視覺(jué)識(shí)別(Visual Recognition)和視覺(jué)描述(Visual Captioning)任務(wù)中表現(xiàn)出色,凸顯了LVLMs在識(shí)別“物體是什么”和描述圖像中展示內(nèi)容的能力。然而,對(duì)于精細(xì)感知任務(wù)(如定位、像素級(jí)感知等)或復(fù)雜推理任務(wù)(如圖像評(píng)測(cè)判斷),大多數(shù)LVLMs仍表現(xiàn)較差。
2)對(duì)于LLaVA-v1.5和LLaVA-v1.5-Xtuner,隨著模型大小的增加(從7B增加到13B),其性能顯著提高,而從InternLM升級(jí)到InternLM2也提高了LLaVA的性能。這表明即便保持訓(xùn)練數(shù)據(jù)和視覺(jué)編碼器保持不變,采用更大或改進(jìn)的LLMs也能夠提升多任務(wù)性能。
3)BLIP2即使沒(méi)有經(jīng)過(guò)指令調(diào)整,也在性能上超過(guò)了大多數(shù)經(jīng)過(guò)數(shù)百萬(wàn)指令數(shù)據(jù)調(diào)整的LVLMs,這表明在某些任務(wù)中使用指令調(diào)整的數(shù)據(jù)甚至可能損害其他任務(wù)的泛化能力。
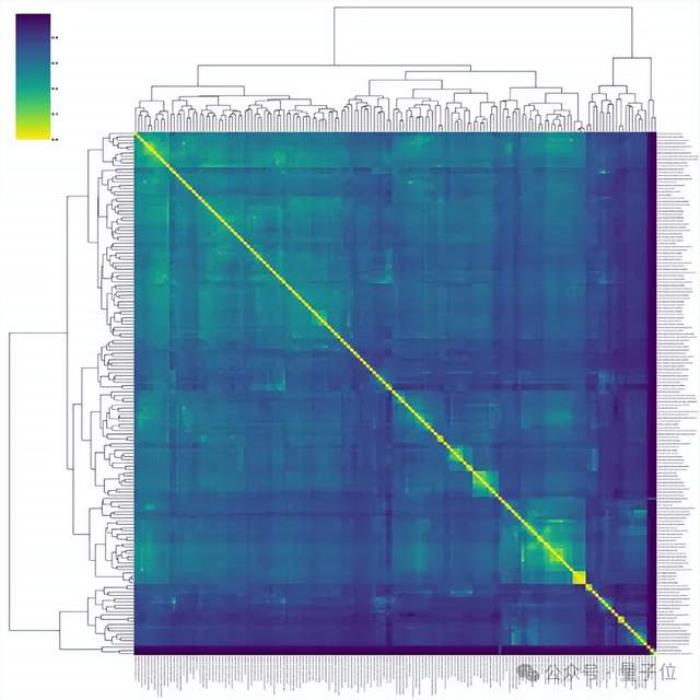
任務(wù)地圖。
得益于MMT-Bench中任務(wù)的廣泛覆蓋,研究人員可以在任務(wù)地圖上評(píng)估LVLMs的多模態(tài)性能。
通過(guò)分析任務(wù)地圖中任務(wù)之間的關(guān)系,可以系統(tǒng)地解釋不同任務(wù)在多模態(tài)能力中的作用。基于任務(wù)地圖,研究人員發(fā)現(xiàn)LVLMs在彼此相近的任務(wù)上獲得更一致的性能排名。此外,任務(wù)地圖還可以用來(lái)發(fā)現(xiàn)領(lǐng)域外(OoD)任務(wù)和領(lǐng)域內(nèi)任務(wù)。
錯(cuò)誤分析。
為了分析LVLMs在MMT-Bench上的錯(cuò)誤分布,研究人員檢查了三個(gè)LVLMs:GPT-4V、GeminiProVision和InternVL-Chat-V1.2(簡(jiǎn)稱InternVL)。
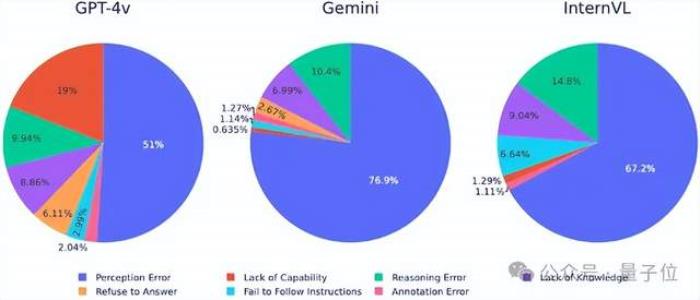
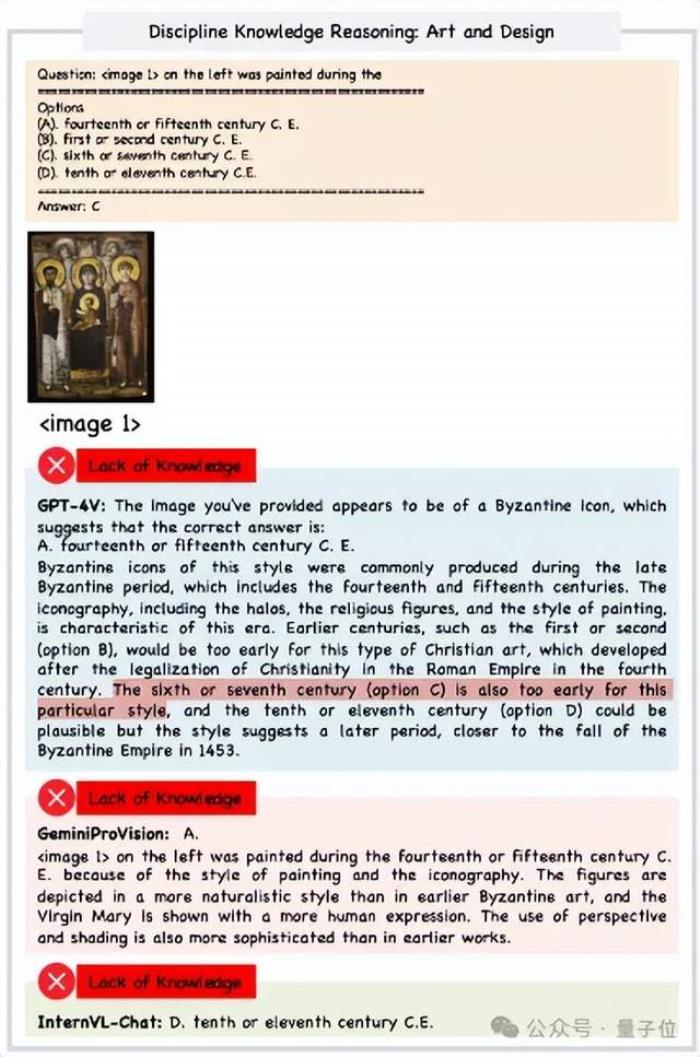
結(jié)果發(fā)現(xiàn),感知錯(cuò)誤(Perception Error)是所有模型中最常見的錯(cuò)誤類型。
其中GPT-4V的感知錯(cuò)誤率顯著低于GeminiProVision(76.9%)和InternVL(67.2%),表明其在感知任務(wù)中的表現(xiàn)優(yōu)越。
推理錯(cuò)誤是第二常見的錯(cuò)誤類型,其中InternVL的推理錯(cuò)誤率最高(14.8%),其次是GeminiProVision(10.4%)和GPT-4V(9.94%),這凸顯了所有模型在復(fù)雜推理任務(wù)中所面臨的挑戰(zhàn)。

最后簡(jiǎn)單一下,MMT-Bench是一個(gè)旨在評(píng)估LVLMs在多模態(tài)多任務(wù)理解方面的一個(gè)綜合性基準(zhǔn)測(cè)試。MMT-Bench的廣度體現(xiàn)在其精心構(gòu)建的包含31325個(gè)多選問(wèn)題的數(shù)據(jù)上,這些問(wèn)題涵蓋了162個(gè)多模態(tài)任務(wù)。
評(píng)估結(jié)果揭示了當(dāng)前LVLMs仍面臨由MMT-Bench所帶來(lái)的重大挑戰(zhàn)。MMT-Bench的目標(biāo)是衡量LVLMs在多任務(wù)AGI路徑上的進(jìn)展,并在未來(lái)將繼續(xù)擴(kuò)展其所涵蓋的任務(wù)集。研究人員相信,MMT-Bench將進(jìn)一步激發(fā)LVLMs的研究和開發(fā),使得人們能夠更接近實(shí)現(xiàn)真正智能的多模態(tài)系統(tǒng)。
相關(guān)推薦



- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
