

 新火種
2024-04-01
新火種
2024-04-01 


GPT4單項僅7.1分,揭露大模型寫代碼三大短板,最新基準(zhǔn)測試來了
首個AI軟件工程師Devin正式亮相,立即引爆了整個技術(shù)界。
Devin不僅能夠輕松解決編碼任務(wù),更可以自主完成軟件開發(fā)的整個周期——從項目規(guī)劃到部署,涵蓋但不限于構(gòu)建網(wǎng)站、自主尋找并修復(fù) BUG、訓(xùn)練以及微調(diào)AI模型等。
這種 “強(qiáng)到逆天” 的軟件開發(fā)能力,讓一眾碼農(nóng)紛紛絕望,直呼:“程序員的末日真來了?”
在一眾測試成績中,Devin在SWE-Bench基準(zhǔn)測試中的表現(xiàn)尤為引人注目。
SWE-Bench是一個評估AI軟件工程能力的測試,重點(diǎn)考察大模型解決實際 GitHub 問題的能力。
Devin以獨(dú)立解決13.86%的問題率高居榜首,“秒殺”了GPT-4僅有的 1.74%得分,將一眾AI大模型遠(yuǎn)遠(yuǎn)甩在后面。
這強(qiáng)大的性能讓人不禁浮想聯(lián)翩:“未來的軟件開發(fā)中,AI將扮演怎樣的角色?”
上海人工智能實驗室聯(lián)合字節(jié)跳動SE Lab的研究人員以及SWE-Bench團(tuán)隊,提出了一個新測試基準(zhǔn)DevBench,首次揭秘大模型在多大程度上可以從PRD出發(fā),完成一個完整項目的設(shè)計、開發(fā)、測試。
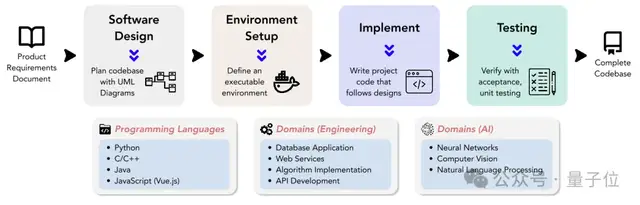
具體地說,DevBench首次對大模型進(jìn)行了從產(chǎn)品需求文檔(PRD)到完整項目開發(fā)各階段表現(xiàn)的評測,包括軟件設(shè)計、依賴環(huán)境搭建、代碼庫級別代碼生成、集成測試和單元測試。

實驗證明,DevBench可以揭露GPT、CodeLlama、DeepSeek-Coder 等大語言模型在軟件研發(fā)不同階段的能力短板,如面向?qū)ο缶幊棠芰Σ蛔恪o法編寫較為復(fù)雜的構(gòu)建腳本(build script),以及函數(shù)調(diào)用參數(shù)不匹配等問題。
目前,DevBench的論文已經(jīng)發(fā)布在預(yù)印平臺arXiv,相關(guān)代碼和數(shù)據(jù)開源在GitHub上。(鏈接見文末)
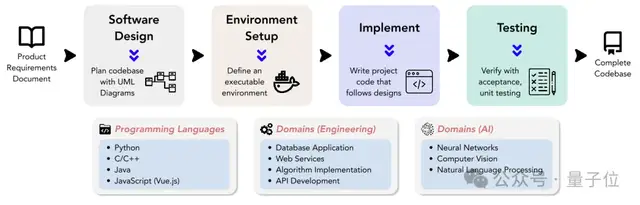
DevBench 有哪些任務(wù)?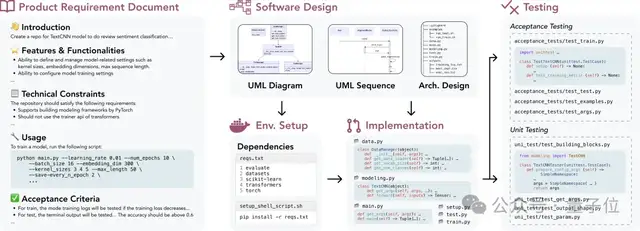
△ 圖為DevBench框架概覽
傳統(tǒng)的編程基準(zhǔn)測試往往關(guān)注代碼生成的某個單一方面,無法全面反映現(xiàn)實世界編程任務(wù)的復(fù)雜性。
DevBench的出現(xiàn),打破了這一局限,它通過一系列精心設(shè)計的任務(wù),模擬軟件開發(fā)的各個階段,從而提供了一個全面評估LLM能力的平臺。
DevBench圍繞五個關(guān)鍵任務(wù)構(gòu)建,每個任務(wù)都關(guān)注軟件開發(fā)生命周期的一個關(guān)鍵階段,模塊化的設(shè)計允許對每個任務(wù)進(jìn)行獨(dú)立的測試和評估。
軟件設(shè)計:利用產(chǎn)品需求文檔PRD創(chuàng)建UML圖和架構(gòu)設(shè)計,展示類、屬性、關(guān)系,以及軟件的結(jié)構(gòu)布局。該任務(wù)參考MT-Bench,采用LLM-as-a-Judge的評測方式。評測主要依據(jù)兩個主要指標(biāo):軟件設(shè)計一般原則(如高內(nèi)聚低耦合等)和忠實度(faithfulness)。
環(huán)境設(shè)置:根據(jù)提供的需求文檔,生成初始化開發(fā)環(huán)境所需的依賴文件。在評測過程中,該依賴文件將在給定的基礎(chǔ)隔離環(huán)境(docker container)內(nèi)通過基準(zhǔn)指令進(jìn)行依賴環(huán)境搭建。隨后在這個模型搭建的依賴環(huán)境中,該任務(wù)通過執(zhí)行代碼倉的基準(zhǔn)示例使用代碼(example usage),評估執(zhí)行基準(zhǔn)代碼的成功率。
代碼實現(xiàn):依據(jù)需求文檔和架構(gòu)設(shè)計,模型需要完成整個代碼庫的代碼文件生成。DevBench開發(fā)了一個自動化測試框架,并針對所使用的具體編程語言進(jìn)行了定制,集成了Python的PyTest、C++的GTest、Java的JUnit和JavaScript的Jest。該任務(wù)評估模型生成代碼庫在基準(zhǔn)環(huán)境中執(zhí)行基準(zhǔn)集成測試和單元測試的通過率。
集成測試:模型根據(jù)需求,生成集成測試代碼,驗證代碼庫的對外接口功能。該任務(wù)在基準(zhǔn)實現(xiàn)代碼上運(yùn)行生成的集成測試,并報告測試的通過率。
單元測試:模型根據(jù)需求,生成單元測試代碼。同樣,該任務(wù)在基準(zhǔn)實現(xiàn)代碼上運(yùn)行生成的單元測試。除了通過率指標(biāo)外,該任務(wù)還引入了語句覆蓋率評價指標(biāo),對測試全面性的進(jìn)行定量評估。
 DevBench 包含哪些數(shù)據(jù)?
DevBench 包含哪些數(shù)據(jù)?
DevBench數(shù)據(jù)準(zhǔn)備過程包括三個階段:倉庫準(zhǔn)備、代碼清理和文檔準(zhǔn)備。
在準(zhǔn)備階段,研究人員從GitHub中選擇高質(zhì)量的倉庫,確保它們的復(fù)雜性可管理。在代碼清理階段,標(biāo)注人員驗證代碼的功能性,對其進(jìn)行精煉,并補(bǔ)充和運(yùn)行測試以確保質(zhì)量。文檔準(zhǔn)備階段涉及為倉庫創(chuàng)建需求文檔、 UML圖和架構(gòu)設(shè)計。
最終,DevBench的數(shù)據(jù)集包含4個編程語言,多個領(lǐng)域,共22個代碼庫。這些代碼倉庫的復(fù)雜性和所使用編程范式的多樣性為語言模型設(shè)置了巨大的挑戰(zhàn)。
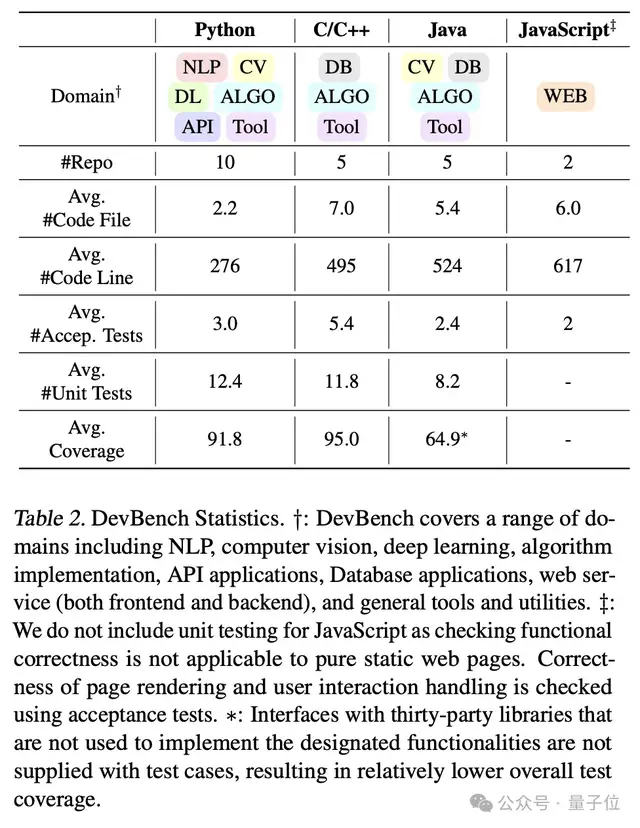
幾個有趣的例子:
TextCNN
大模型能完整地寫一個TextCNN做文本二分類的模型嗎?能夠自己把數(shù)據(jù)集從HF拉下來,把訓(xùn)練跑起來是基本要求。還需模型按照文檔的需求定制超參數(shù)、記錄log、存儲checkpoint、同時保證實驗可復(fù)現(xiàn)性。
(https://github.com/open-compass/DevBench/tree/main/benchmark_data/python/TextCNN)
Registration & Login
前端項目往往依賴較多的組件庫和前端框架,模型是否能夠在可能出現(xiàn)版本沖突的前端項目中應(yīng)對自如?
(https://github.com/open-compass/DevBench/tree/main/benchmark_data/javascript/login-registration)
People Management
模型對SQLite數(shù)據(jù)庫的創(chuàng)建和管理掌握的怎么樣?除了基本的增刪改查操作,模型能否將校園人員信息和關(guān)系數(shù)據(jù)庫的管理和操作封裝成易用的命令行工具?
(https://github.com/open-compass/DevBench/tree/main/benchmark_data/cpp/people_management)
Actor Relationship Game
“六度分隔理論”在影視圈的猜想驗證?模型需要從TMDB API獲取數(shù)據(jù),并構(gòu)建流行演員們之間通過合作電影進(jìn)行連接的人際連系網(wǎng)。
(https://github.com/open-compass/DevBench/tree/main/benchmark_data/java/Actor_relationship_game)
ArXiv digest
ArXiv論文檢索小工具也被輕松拿捏了?ArXiv的API并不支持“篩選最近N天的論文”的功能,但卻可以“按發(fā)表時間排序”,模型能夠以此開發(fā)一個好用的論文查找工具嗎?
(https://github.com/open-compass/DevBench/tree/main/benchmark_data/python/ArXiv_digest)
實驗發(fā)現(xiàn)
研究團(tuán)隊利用DevBench對當(dāng)前流行的LLMs,包括GPT-4-Turbo進(jìn)行了全面測試。結(jié)果顯示,盡管這些模型在簡單的編程任務(wù)中表現(xiàn)出色,但在面對復(fù)雜的、真實世界的軟件開發(fā)挑戰(zhàn)時,它們?nèi)匀挥龅搅酥卮罄щy。特別是在處理復(fù)雜的代碼結(jié)構(gòu)和邏輯時,模型的性能還有待提高。
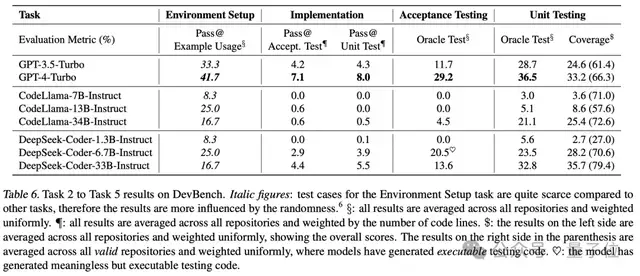
DevBench不僅揭示了現(xiàn)有LLMs在軟件開發(fā)中的局限性,也為未來模型的改進(jìn)提供了寶貴的洞見。通過這一基準(zhǔn)測試,研究人員可以更好地理解 LLMs的強(qiáng)項和弱點(diǎn),從而有針對性地優(yōu)化它們,推動AI在軟件工程領(lǐng)域的進(jìn)一步發(fā)展。
此外,DevBench 框架的開放性和可擴(kuò)展性意味著它可以持續(xù)適配不同的編程語言和開發(fā)場景。DevBench 還在發(fā)展過程中,非常歡迎社區(qū)的朋友參與共建。
Devin 在 SWE-Bench 上一路領(lǐng)先,它的優(yōu)異表現(xiàn)可以擴(kuò)展到其他評測場景嗎?隨著 AI 軟件開發(fā)能力的持續(xù)發(fā)展,這場碼農(nóng)和 AI 的較量讓人倍感期待。
還有OpenCompass大模型評測體系
DevBench現(xiàn)已加入OpenCompass司南大模型能力評測體系,OpenCompass是上海人工智能實驗室研發(fā)推出的面向大語言模型、多模態(tài)大模型等各類模型的一站式評測平臺。
OpenCompass具有可復(fù)現(xiàn)、全面的能力維度、豐富的模型支持、分布式高效評測、多樣化評測范式以及靈活化拓展等特點(diǎn)。基于高質(zhì)量、多層次的能力體系和工具鏈,OpenCompass 創(chuàng)新了多項能力評測方法,支持各類高質(zhì)量的中英文雙語評測基準(zhǔn),涵蓋語言與理解、常識與邏輯推理、數(shù)學(xué)計算與應(yīng)用、多編程語言代碼能力、智能體、創(chuàng)作與對話等多個方面,能夠?qū)崿F(xiàn)對大模型真實能力的全面診斷。DevBench更是拓寬了 OpenCompass 在智能體領(lǐng)域的評測能力。
DevBench論文:https://arxiv.org/abs/2403.08604GitHub:https://github.com/open-compass/devBench/OpenCompass https://github.com/open-compass/opencompass
相關(guān)推薦

- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認(rèn)可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
