

 新火種
2023-11-16
新火種
2023-11-16 


可跨學科理解、多尺度建模,MITLAMM發(fā)布微調的大語言模型MechGPT

編輯 | 蘿卜皮
幾個世紀以來,研究人員一直在尋找連接不同領域知識的方法。隨著人工智能的出現(xiàn),我們現(xiàn)在可以探索跨領域(例如,力學-生物學)或不同領域(例如,失效力學-藝術)的關系。
為了實現(xiàn)這一目標,麻省理工學院(MIT)原子與分子力學實驗室 (Laboratory for Atomistic and Molecular Mechanics,LAMM)的研究人員使用了經過微調的大型語言模型 (LLM),來獲取多尺度材料失效的知識子集。
該方法包括使用通用 LLM 從原始來源中提取問答對,然后進行 LLM 微調。由此產生的 MechGPT LLM 基礎模型用于一系列計算實驗,從而可以探索其知識檢索、各種語言任務、假設生成以及跨不同領域連接知識的能力。
盡管該模型具有一定的能力來回憶訓練中的知識,但研究人員發(fā)現(xiàn) LLM 對于通過本體知識圖提取結構見解更加有意義。這些可解釋的圖形結構提供了解釋性見解、新研究問題的框架以及知識的視覺表示,這些知識也可用于檢索增強生成。
該研究以「MechGPT, a Language-Based Strategy for Mechanics and Materials Modeling That Connects Knowledge Across Scales, Disciplines and Modalities」為題,于 2023 年 10 月 19 日發(fā)布在《Applied Mechanics Reviews》。

對物理、生物和形而上學概念進行建模一直是許多學科研究人員關注的焦點。早期的科學家和工程師往往深深扎根于從科學到哲學、物理到數(shù)學以及藝術的多個領域(例如伽利略·伽利萊、列奧納多·達·芬奇、約翰·沃爾夫岡·馮·歌德),但是隨著科學的發(fā)展,專業(yè)化在如今已經占據主導地位。部分原因是跨領域積累了大量知識,這需要人類花大量的精力去研究實踐。
現(xiàn)在,大型語言模型 (LLM) 的出現(xiàn)挑戰(zhàn)了科學探究的范式,不僅帶來了基于人工智能/機器學習的新建模策略,而且還帶來了跨領域連接知識、想法和概念的機會。這些模型可以補充傳統(tǒng)的多尺度建模,用于分層材料的分析和設計以及力學中的許多其他應用。
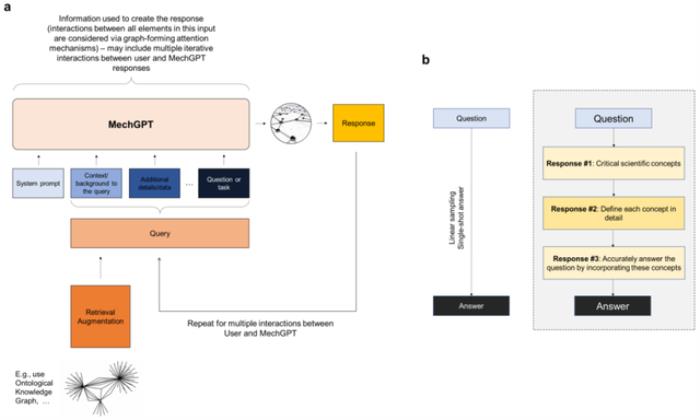
圖:工作流程示意圖。(來源:論文)
在這里,LAMM 的研究人員以最近提出的 LLM 在力學和材料研究和開發(fā)中的用途為基礎,并且基于 Llama-2 based OpenOrca-Platypus2-13B 的通用 LLM,開發(fā)了一個經過微調的 MechGPT 模型,該模型專注于模型材料失效、多尺度建模以及相關學科。
選擇 OpenOrca-Platypus2-13B 模型是因為其在推理、邏輯、數(shù)學/科學和其他學科等關鍵任務上具有高水平的性能,能夠以可管理的模型大小提供跨學科的廣泛的、可轉移的知識和通用概念,并提供計算效率。
LLM 在科學領域有著強大的應用。除了能夠分析大量數(shù)據和復雜系統(tǒng)之外,在力學和材料科學領域,LLM 用于模擬和預測材料在不同條件下的行為,例如機械應力、溫度和化學相互作用等。正如早期工作所示,通過在分子動力學模擬的大型數(shù)據集上訓練 LLM,研究人員可以開發(fā)能夠預測新情況下材料行為的模型,從而加速發(fā)現(xiàn)過程并減少實驗測試的需要。
此類模型對于分析書籍和出版物等科學文本也非常有效,使研究人員能夠從大量數(shù)據中快速提取關鍵信息和見解。這可以幫助科學家識別趨勢、模式以及不同概念和想法之間的關系,并為進一步研究產生新的假設和想法。
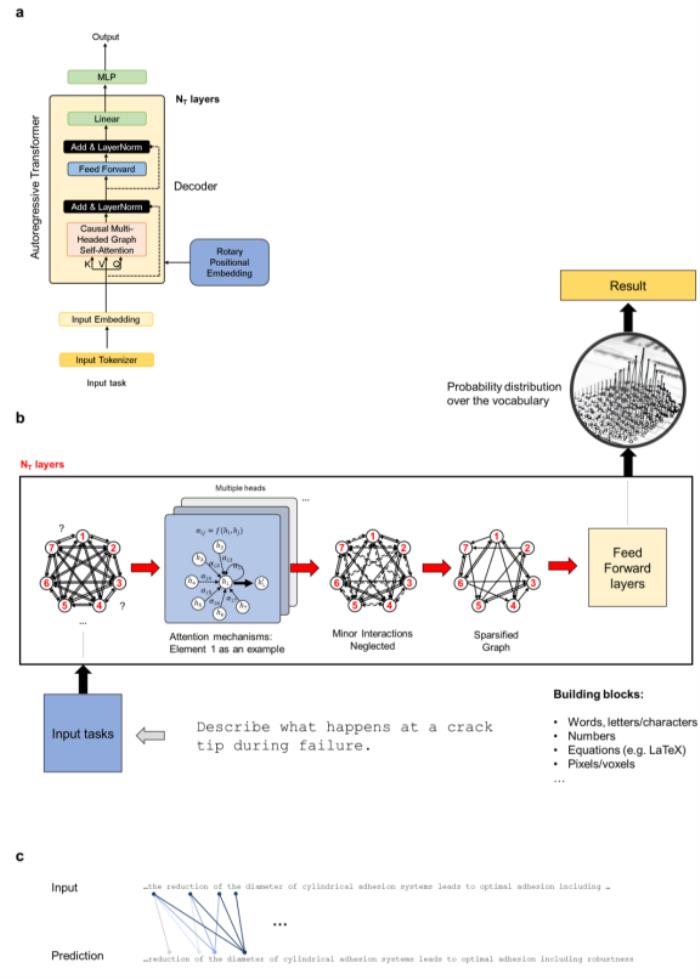
圖:用于構建 MechGPT 的自回歸解碼器 transformer 架構概述。(來源:論文)
在這里,該團隊將重點放在后者的開發(fā)上,并探索 MechGPT 的使用,這是基于 Transformer 的 LLM 系列中的一種生成人工智能工具,專門針對材料失效和相關的多尺度方法進行了訓練,從而評估這些策略的潛力。
該研究提出的策略包括幾個步驟,包括首先是蒸餾步驟,其中研究人員使用 LLM 從原始數(shù)據塊(例如從一個或多個 PDF 文件中提取的文本)中生成問答對,然后在第二步中利用這些數(shù)據來微調模型。這里探索的初始 MechGPT 模型在材料失效的原子建模領域進行了專門訓練,并證明了其在知識檢索、通用語言任務、假設生成等方面的有用性。
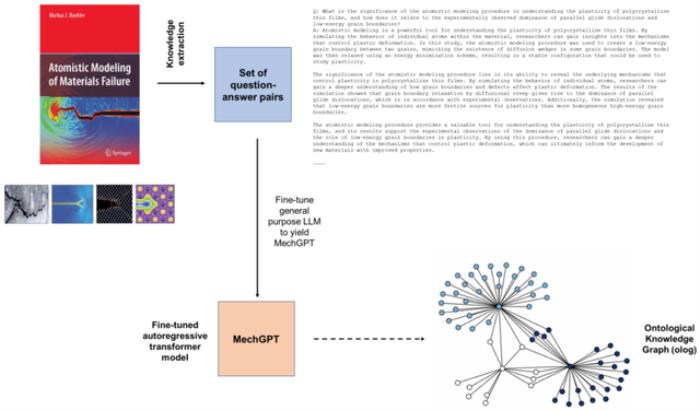
圖:所使用的建模策略概述。(來源:論文)
論文里,研究人員介紹了總體建模策略,使用特定語言建模策略生成數(shù)據集以從源中提取知識,然后使用新穎的力學和材料數(shù)據集訓練模型。研究人員分析討論了 MechGPT 的三個版本,其參數(shù)大小從 130 億到 700 億不等,上下文長度達到超過 10,000 個 token。
在對模型、提示以及訓練方式進行一些一般性評論之后,研究人員應用該模型并在各種設置中測試其性能,包括使用 LLM 進行本體圖生成和開發(fā)有關跨學科復雜主題的見解,以及代理建模,其中多個 LLM 以協(xié)作或對抗的方式交互,以產生對主題領域或問題回答的更深入的見解。
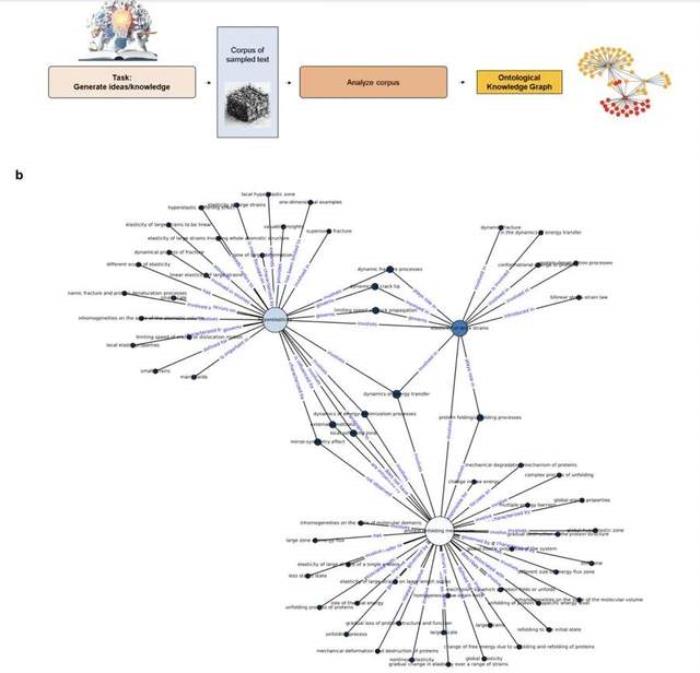
圖:開發(fā)本體知識圖表示,以在超音速斷裂和蛋白質展開機制的背景下關聯(lián)超彈性。(來源:論文)
同時,該團隊進一步提供了不同抽象級別的語言模型和多粒子系統(tǒng)之間的概念比較,并解釋了如何將新框架視為提取管理復雜系統(tǒng)的普遍關系的手段。
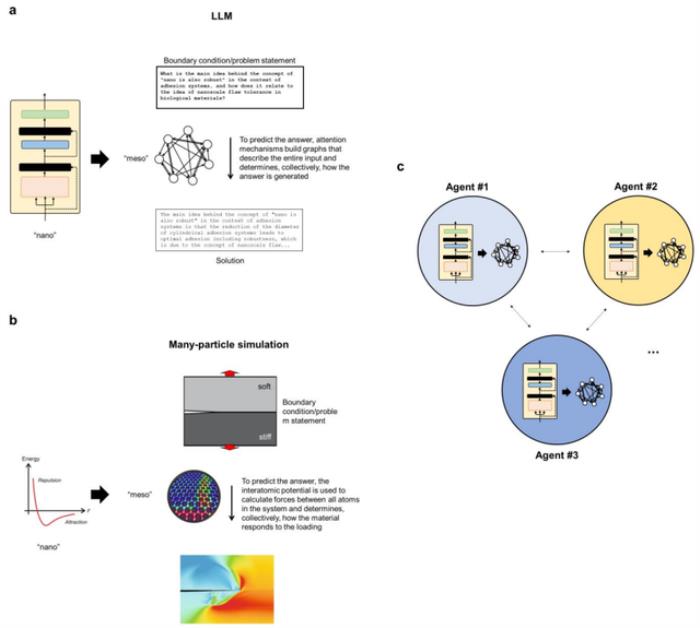
圖:LLM 和多粒子模擬之間的概念類比。(來源:論文)
總體而言,該研究提出的工作有助于開發(fā)更強大、更通用的人工智能模型,這些模型可以幫助推進科學研究并解決特定應用領域的復雜問題,從而可以深入評估模型的性能。與所有模型一樣,它們必須經過仔細驗證,它們的有用性存在于所提出的問題的背景、其優(yōu)點和缺點以及幫助科學家推進科學和工程的更廣泛的工具中。
而且,作為科學探究的工具,它們必須被視為理解、建模和設計我們周圍世界的工具集合。隨著人工智能工具的快速發(fā)展,它們在科學背景下的應用才剛剛開始帶來新的機遇。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
