

 新火種
2024-06-11
新火種
2024-06-11 


清華系細(xì)胞大模型登Nature子刊!能對(duì)人類2萬(wàn)基因同時(shí)建模,代碼已開源
生命科學(xué)領(lǐng)域的基礎(chǔ)大模型來(lái)了!
來(lái)自清華、百圖生科的團(tuán)隊(duì)提出的單細(xì)胞基礎(chǔ)大模型scFoundation,登上Nature Methods。

該模型基于5000萬(wàn)人類單細(xì)胞測(cè)序的數(shù)據(jù)進(jìn)行訓(xùn)練,擁有1億參數(shù),能夠同時(shí)處理約20000個(gè)基因。
團(tuán)隊(duì)在模型架構(gòu)上進(jìn)行了創(chuàng)新,相同參數(shù)量下計(jì)算時(shí)間是傳統(tǒng)Transformer架構(gòu)的3%左右。相關(guān)研究成果也被NeurIPS2024接收。
清華大學(xué)自動(dòng)化系博士研究生郝敏升為該論文的第一作者。清華大學(xué)張學(xué)工教授,馬劍竹教授,百圖生科宋樂教授為通訊作者。
作為基礎(chǔ)模型,它在細(xì)胞測(cè)序深度增強(qiáng)、細(xì)胞藥物響應(yīng)預(yù)測(cè)和細(xì)胞擾動(dòng)預(yù)測(cè)等下游任務(wù)中表現(xiàn)出卓越的性能提升,并為基因網(wǎng)絡(luò)推斷和轉(zhuǎn)錄因子識(shí)別提供了新的研究思路。
細(xì)胞基礎(chǔ)大模型登Nature子刊
通過(guò)在大規(guī)模語(yǔ)料庫(kù)上的訓(xùn)練,大模型才具備了基本的語(yǔ)言理解和識(shí)別能力。
在生命科學(xué)領(lǐng)域,細(xì)胞可以被視為擁有自身“語(yǔ)言”的基本結(jié)構(gòu)和功能單元,由DNA序列、蛋白質(zhì)和基因表達(dá)值等構(gòu)成無(wú)數(shù)“詞語(yǔ)”的“句子”。
那么隨之而來(lái)的問(wèn)題是:
目前訓(xùn)練大規(guī)模單細(xì)胞數(shù)據(jù)主要存在以下三點(diǎn)挑戰(zhàn):
1、基因表達(dá)預(yù)訓(xùn)練數(shù)據(jù)需要涵蓋不同狀態(tài)和類型的細(xì)胞景觀。然而目前大多數(shù)單細(xì)胞數(shù)據(jù)組織松散,全面完整的數(shù)據(jù)庫(kù)仍然缺失。
2、在訓(xùn)練過(guò)程中,傳統(tǒng)的transformer難以處理近20000個(gè)蛋白質(zhì)編碼基因構(gòu)成的“句子”,這使得現(xiàn)有工作通常不得不將模型限制在一小部分預(yù)選的基因列表上。
3、 不同技術(shù)和實(shí)驗(yàn)室的單細(xì)胞轉(zhuǎn)錄數(shù)據(jù)在測(cè)序深度上存在差異,這妨礙了模型學(xué)習(xí)統(tǒng)一且有意義的細(xì)胞和基因表示。
針對(duì)這些問(wèn)題,研究團(tuán)隊(duì)首先收集了超過(guò)5000萬(wàn)個(gè)涵蓋各個(gè)器官、腫瘤和非腫瘤的大規(guī)模人類單細(xì)胞數(shù)據(jù)集用于訓(xùn)練。
與大型語(yǔ)言模型中的“詞-向量”轉(zhuǎn)換不同,scFoundation通過(guò)巧妙設(shè)計(jì),將連續(xù)的基因表達(dá)值轉(zhuǎn)化為向量。
針對(duì)單細(xì)胞數(shù)據(jù)的高稀疏性以及零值和非零值所包含信息量的差異,研究團(tuán)隊(duì)設(shè)計(jì)了一個(gè)非對(duì)稱編碼模塊。
該模塊在保持相同參數(shù)規(guī)模的情況下,所需的計(jì)算量?jī)H為傳統(tǒng)語(yǔ)言模型Transformer的3.4%。
此外,研究團(tuán)隊(duì)還提出了一種測(cè)序深度感知的預(yù)訓(xùn)練任務(wù)“read-depth-aware (RDA)”,能夠?qū)y(cè)序深度進(jìn)行降采樣,使得模型在預(yù)訓(xùn)練階段在完成傳統(tǒng)的掩膜恢復(fù)任務(wù)外,還能夠由低質(zhì)量細(xì)胞恢復(fù)高質(zhì)量細(xì)胞的基因表達(dá)信息。
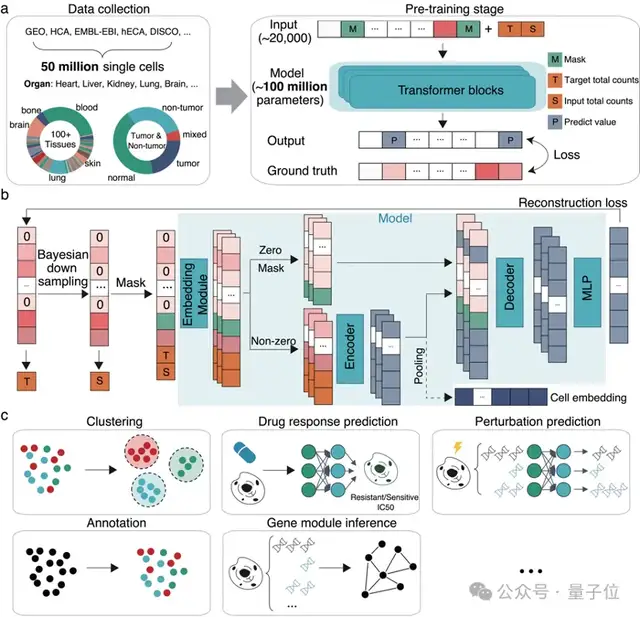
△scFoundation模型及下游應(yīng)用場(chǎng)景
兩種應(yīng)用范式
scFoundation的應(yīng)用范式主要包括開箱即用和微調(diào)兩種:
從scFoundation得到表征,進(jìn)一步利用下游方法分析。訓(xùn)練scFoundation一層和針對(duì)各個(gè)任務(wù)的MLP頭,進(jìn)行標(biāo)簽預(yù)測(cè)。
在開箱即用范式上,受益于RDA預(yù)訓(xùn)練任務(wù),將scFoundation應(yīng)用于細(xì)胞測(cè)序深度增強(qiáng)任務(wù),在不需要進(jìn)一步微調(diào)的情況下達(dá)到了比現(xiàn)有訓(xùn)練方法相當(dāng)甚至更好的效果。
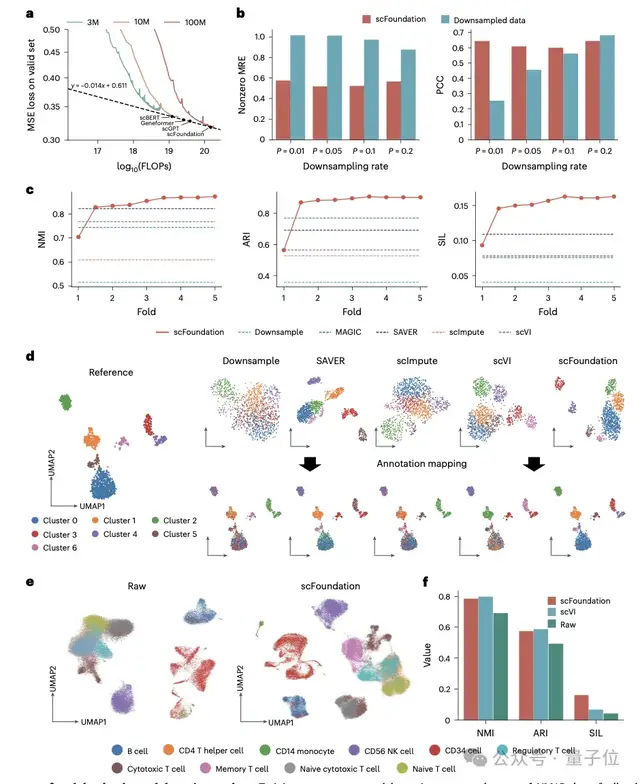
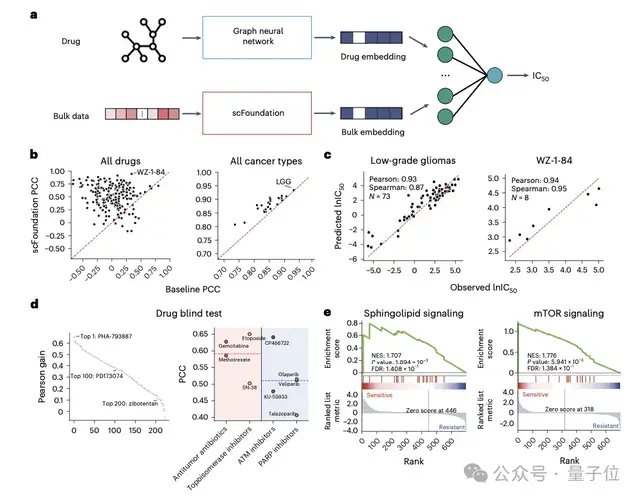
此外,通過(guò)構(gòu)建模型預(yù)測(cè)細(xì)胞對(duì)癌癥藥物干預(yù)的反應(yīng),對(duì)指導(dǎo)抗癌藥物的設(shè)計(jì)及理解癌癥的生物學(xué)機(jī)制至關(guān)重要。
基于scFoundation提取的Bulk基因表達(dá)數(shù)據(jù),能夠預(yù)測(cè)藥物半最大抑制濃度IC50及單細(xì)胞水平的藥物敏感性,顯示出在幾乎所有藥物和癌癥類型上預(yù)測(cè)效果均有顯著提升。
而在細(xì)胞擾動(dòng)預(yù)測(cè)任務(wù)中,通過(guò)提取單個(gè)細(xì)胞的基因表征來(lái)構(gòu)建特定的基因共表達(dá)網(wǎng)絡(luò),scFoundation成功捕捉了不同條件下的細(xì)胞和基因表征,顯著提高了單/雙擾動(dòng)預(yù)測(cè)的準(zhǔn)確度。
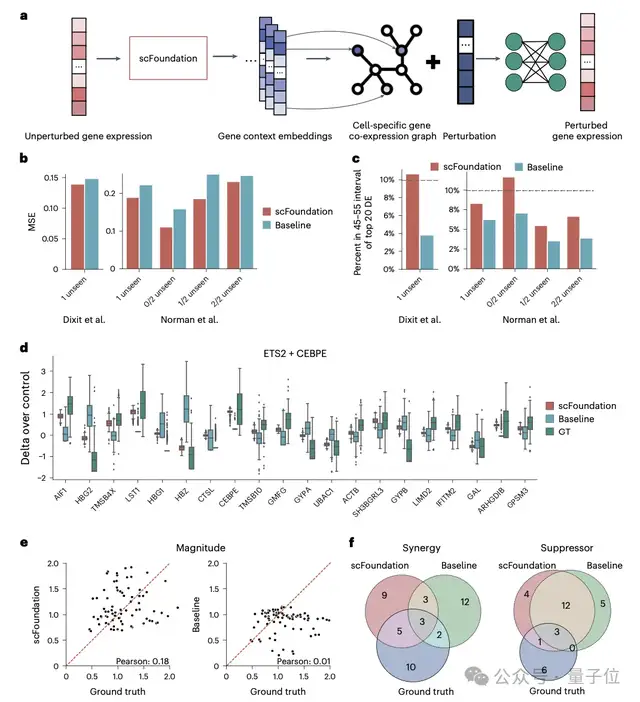
此外,基因表征還可用于構(gòu)建針對(duì)特定細(xì)胞類型的基因網(wǎng)絡(luò)。研究團(tuán)隊(duì)在T、B和Monocyte細(xì)胞類型中識(shí)別出了特異的基因模塊和轉(zhuǎn)錄因子。在微調(diào)應(yīng)用方面,scFoundation在細(xì)胞類型標(biāo)注任務(wù)中的效果遠(yuǎn)超傳統(tǒng)方法。
研究人員還進(jìn)行了豐富的消融實(shí)驗(yàn),揭示了不同模塊設(shè)計(jì)對(duì)性能的影響,相關(guān)模型細(xì)節(jié)已在NeurIPS 2024的xTrimoGene模型中發(fā)表。

綜上所述,scFoundation模型為建立細(xì)胞預(yù)訓(xùn)練大模型的模型架構(gòu)、訓(xùn)練框架,和下游示范應(yīng)用體系都提供了新的思路和方法,為生物醫(yī)學(xué)任務(wù)的學(xué)習(xí)提供了基礎(chǔ)功能,拓展了單細(xì)胞領(lǐng)域基礎(chǔ)模型的邊界。
目前模型權(quán)重及代碼已開源。同時(shí)為了減少計(jì)算負(fù)擔(dān),支持更多用戶輕量使用,研究團(tuán)隊(duì)也提供了模型相應(yīng)的API,用戶可在線獲取scFoundation模型表征,支持CLI、Python SDK和網(wǎng)頁(yè)端調(diào)用。
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
