

 新火種
2024-03-18
新火種
2024-03-18 


開源版“Devin”AI程序員炸場:自己分析股票、做報表、建模型
GitHub三萬Star項目MetaGPT上新,號稱是“開源Devin”——
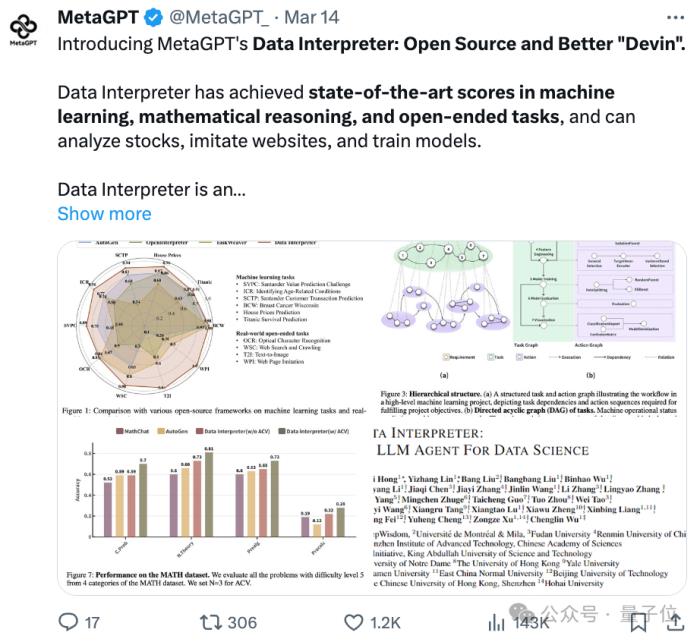
推出數據解釋器(Data Interpreter),能夠應對數據實時變化、任務之間復雜的依賴關系、流程優化需求以及執行結果反饋的邏輯一致性等挑戰。
話不多說,直接看演示。
可以從英偉達股價數據中分析收盤價格趨勢:
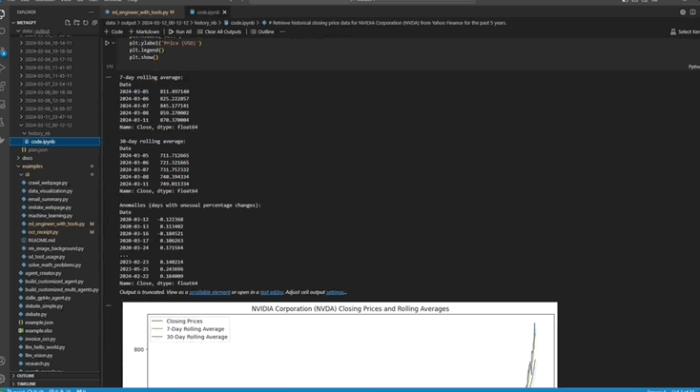
分析數據預測葡萄酒質量:
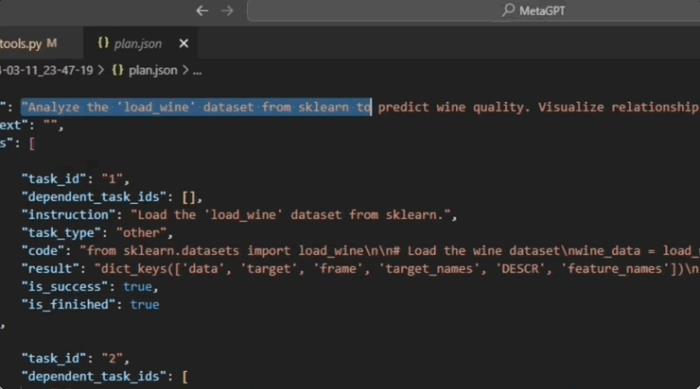
自動摳圖刪除圖片背景:
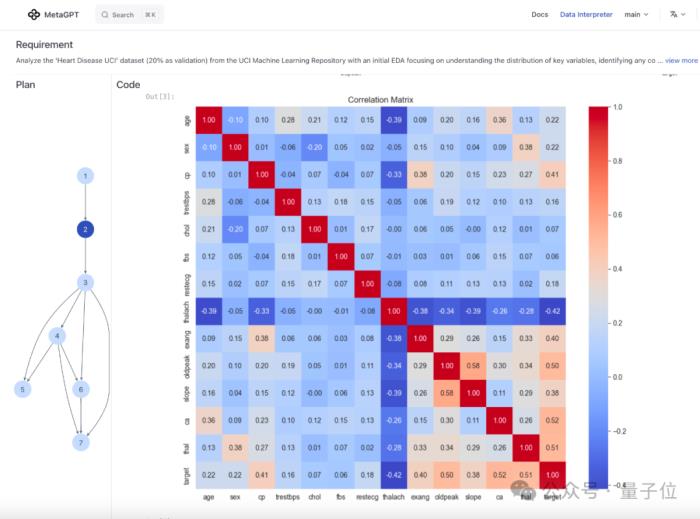
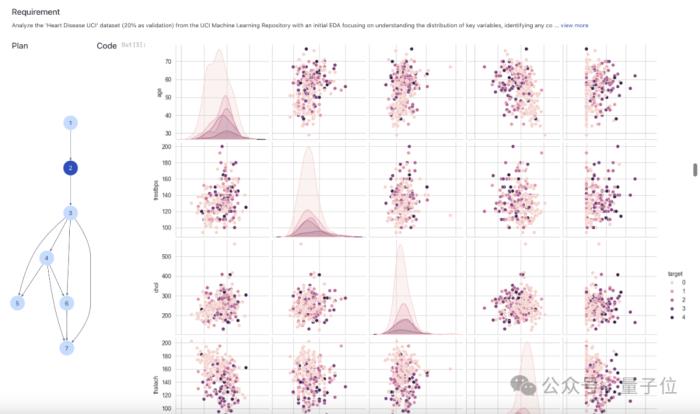
還能針對糖尿病、心臟病等疾病,通過數據分析預測病情進展:
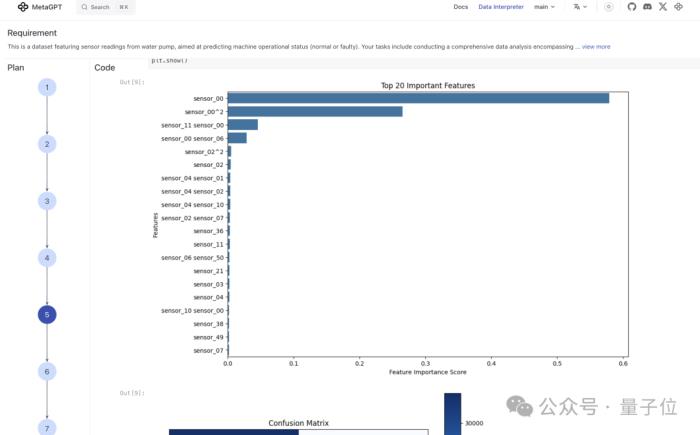
針對水泵傳感器讀數,進行相關性分析、因果推斷、異常檢測等全面分析,預測機器的運行狀態:
Data Interpreter由MetaGPT團隊聯合北京工業大學、復旦大學、華東師范大學、河海大學、加拿大蒙特利爾大學、KAUST、圣母大學、廈門大學、香港中文大學(深圳)、香港大學、耶魯大學、中國科學院深圳先進技術研究院、中國人民大學共同推出。
除了數據分析,Data Interpreter還能很好地迭代式觀察數據,具備構建機器學習模型、進行數學推理的能力,還能自動回復電子郵件、仿寫網站。
在各種數據科學和現實世界任務上,與開源基線相比,Data Interpreter在多種任務上取得SOTA性能。
在機器學習任務中綜合得分從0.86提升至0.95,在MATH數據集上提高了26%,在開放式任務中任務完成率提升112%。
Data Interpreter一經發布,引起不少網友關注,X(原推特)轉贊收藏量2.5k+。
網友再次感慨最近科技圈實在太熱鬧,belike:

這個數據解釋器長啥樣?
由大模型(LLM)驅動的智能體已經證明了它們在處理復雜任務方面的顯著潛力。通過賦予LLM代碼執行能力來提升其問題解決能力正逐漸成為一種趨勢,如Code-Interpreter、OpenInterpreter、TaskWeaver。
然而,在數據科學領域,現有LLM-based智能體的性能仍有待提升。
Data Interpreter提供了一種全新的解決方案,旨在通過增強智能體的任務規劃,工具集成以及推理能力,直面數據科學問題的挑戰。
Data Interpreter提出了三個關鍵技術:
1)基于分層圖結構的動態計劃,基于分層的圖結構進行任務和代碼規劃,有效管理任務間的復雜依賴,靈活應對數據科學任務的實時數據變化;
2)工具集成與進化,通過在代碼生成過程中自動集成代碼片段作為工具,動態嵌入了數據科學領域所需的領域知識;
3)基于驗證與經驗驅動的推理,自動在反饋中增強邏輯一致性檢測,通過基于置信度的驗證提升執行代碼的邏輯合理性,并借助經驗庫增強推理能力。
下面我們逐一展開來看。

基于分層圖結構的動態計劃
這種方法借鑒了自動化機器學習中的層次規劃技術,通過層次結構將復雜的數據科學問題分解為易于管理的小任務,并進一步將這些任務轉化為具體的代碼執行動作,從而實現細致的規劃與執行。
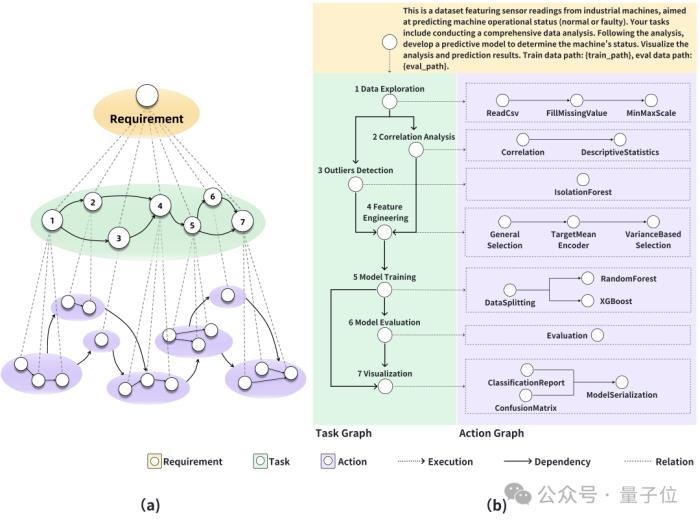
分層結構:(a) 一個有組織的任務和動作圖,展示了高層級機器學習項目的工作流程,包括實現項目目標所需的任務依賴和動作序列。(b) 任務的有向無環圖(DAG),以機器操作狀態預測問題為例。任務圖展示了拆解的計劃任務,而動作圖(也稱為執行圖)則根據計劃的任務圖執行各個節點。每個節點的執行代碼由LLM轉換。
這種動態規劃方法賦予了Data Interpreter在任務變化時的適應性,而有向無環圖(Directed acyclic graph)結構則在監控和處理數據科學問題中的任務依賴關系方面展現出了高效性。
通過這種方式,Data Interpreter能夠有效地管理和優化數據科學任務的執行流程,提高了問題解決的準確性。
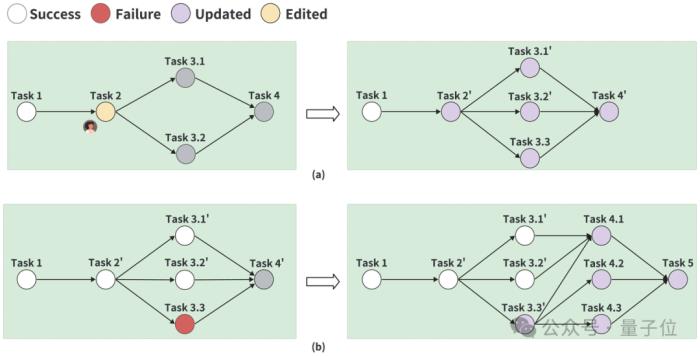
數據解釋器的動態計劃管理:(a) 通過人工編輯進行計劃細化。左側圖像顯示了在圖上經過人工編輯的任務,右側圖像則展示了細化后的計劃,包括更新后的任務3.1’、3.2’以及新增的任務3.3。(b) 對失敗任務的計劃進行細化。在任務執行后,如果任務3.3失敗,細化后的計劃將整合已有的成功任務,用更新后的任務3.3’替換原任務3.3,并引入新任務4.1、4.2、4.3和5。
工具集成與進化
在數據科學任務中,任務的多樣性與專業性要求基于LLM框架具備廣泛的工具調用能力。現有的工具調用方式往往局限于API的形式,無法滿足任務多樣性帶來的動態需求。
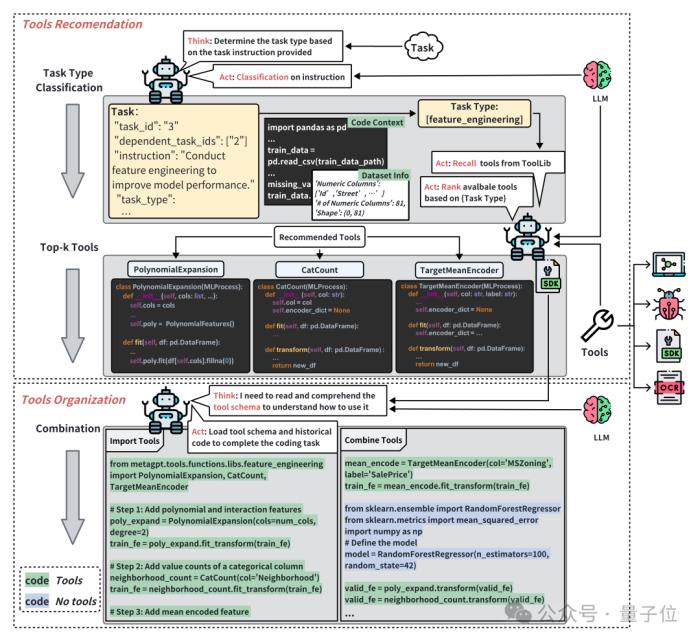
Data Interpreter 提出了工具集成與生成的方法。通過工具推薦與組織,能夠根據任務描述,進行任務分類,從而有效選擇合適的工具集。
在執行階段,Data Interpreter根據工具參數描述、工具方法描述文檔的結構化信息,動態嵌入和調整工具參數,以適應任務的具體需求。
此外,Data Interpreter還能夠通過自我進化,從執行經驗中抽象出工具的核心功能,形成通用的代碼片段,集成到工具函數庫之中。這些工具函數可以在未來的任務中重復使用,從而減少了調試頻率,提高了執行效率。
下圖是數據解釋器中的工具使用流程,工具推薦最初根據任務分類來選擇工具,然后根據任務需求組合多個工具使用:
基于驗證與經驗驅動的推理
解決數據科學問題需要嚴謹的數據與邏輯驗證過程,現有的研究在解決這一類問題的過程中,往往依賴于代碼執行后的錯誤檢測或異常捕獲,這一方式往往會誤解代碼執行正確即任務完成,無法發現邏輯錯誤,難以提升任務實現的有效性。
Data Interpreter 通過結合基于置信度的自動驗證(Automated Confidece-based Verification)策略,顯著提升了其在數據科學問題解決中的推理能力。
ACV策略要求Data Interpreter在執行代碼后生成驗證代碼并執行驗證,根據執行驗證結果校驗任務和實現代碼的一致性,類似于白盒測試流程。
在需要更嚴謹數值反饋的場景中,如使用LLM進行數學推理,Data Interpreter可以增加多次獨立驗證,并通過多次結果的置信度排序來進一步提升效果。
另一方面,Data Interpreter利用經驗池存儲和反思任務執行過程中的經驗,能夠從過去的成功和失敗中學習代碼知識,從而在面對新任務時做出更準確的決策。這種結合實時驗證和經驗學習的方法,顯著增強了解釋器的推理能力,提升了任務的解決質量。
下圖以MATH內的一個任務說明基于置信度自動驗證流程,虛線框內是自動驗證的過程,虛線框下方根據驗證對多個候選答案進行排序:
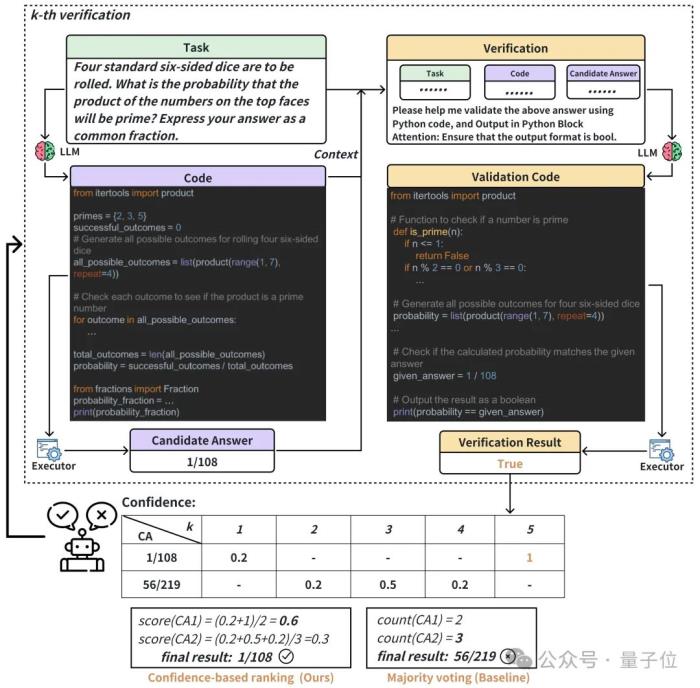
多任務取得新SOTA
在實驗部分,Data Interpreter在多個數據科學和現實世界任務上進行了評估。
基準測試
MATH benchmark涵蓋了從初等代數到微積分等廣泛的數學領域。這個基準測試不僅測試了模型對數學知識的掌握程度,還考察了它們在解決復雜數學問題時的推理能力。
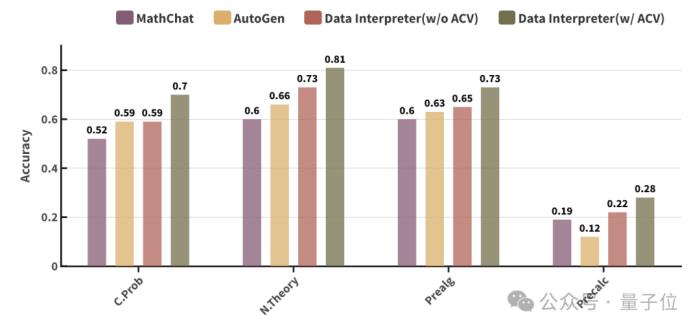
為評估Data Interpreter在這一領域的性能,研究團隊選擇了MATH基準測試中難度最高的Level-5問題,這些問題涉及計數和概率(C.Prob)、數論(N.Theory)、初等代數(Prealg)和微積分(Precalc)等四個類別。
如圖所示,以Accuracy作為這個任務的評估指標,Data Interpreter在4個類別上均取得了最好的成績。特別是在 N.Theory 中,帶有Automated Confidence-based Verification(ACV)策略的Data Interpreter達到了0.81的準確率。
為了測試Data Interpreter的精準和效率,研究團隊還設計了ML-Benchmark,這是一個集合了Kaggle網站上多種經典機器學習任務的測試集。
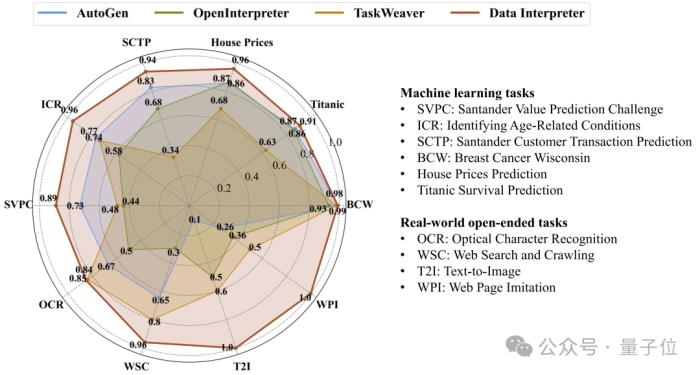
這些任務不僅覆蓋了葡萄酒識別(WR)、Wisconsin乳腺癌(BCW)、Titanic生存預測等經典問題,還包括了房價預測(House Prices)、Santander客戶交易預測(SCTP)、識別與年齡相關的狀況(ICR)以及Santander價值預測挑戰賽(SVPC)等更具挑戰性的項目。
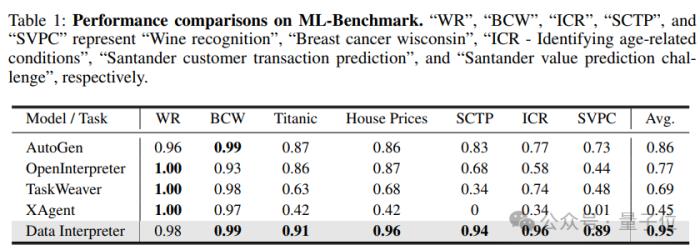
通過任務完成率(CR)、歸一化性能得分(NPS)和綜合得分(CS)這三個關鍵指標,Data Interpreter在七項任務上的平均得分高達0.95,遠超AutoGen的0.86,提升了10.3%。
特別是在ICR和SVPC這兩個數據集上,Data Interpreter的表現尤為出色,分別比AutoGen提高了24.7%和21.2%。
值得一提的是,Data Interpreter是唯一一個在Titanic、House Prices、SCTP和ICR任務上得分均超過0.9的框架,這意味著它在機器學習任務中不僅能夠完成核心步驟,還能在執行過程中持續優化任務效果。
另外,為測試Data Interpreter在開放式任務中的表現。研究人員還整理了一個包含20個任務的開放式任務基準。
這些任務涵蓋了從光學字符識別(OCR)到迷你游戲生成(MGG)等多個領域,包括網絡搜索和爬蟲(WSC)、電子郵件自動回復(ER)、網頁模仿(WPI)、圖像背景去除(IBR)、文本轉圖像(T2I)、圖像到HTML代碼生成(I2C)等多樣化的挑戰。
然后將Data Interpreter與AutoGen和OpenInterpreter這兩個基準模型進行了對比。每個框架對每個任務進行了三次實驗,以平均完成率作為評價標準。
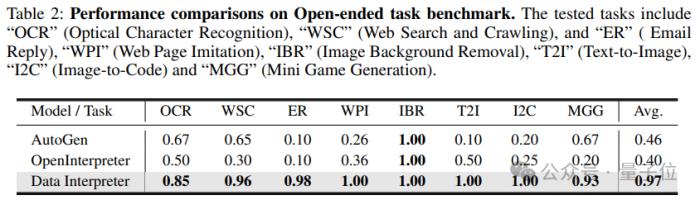
結果顯示,Data Interpreter在開放式任務上的平均完成率為0.97,與AutoGen相比大幅提高了112%。對于去除圖像背景(IBR)任務,所有三個框架都獲得了1.0的完整分數。
在OCR相關任務中,Data Interpreter的平均完成率為0.85,比AutoGen和OpenInterpreter分別高出26.8%和70.0%。
在需要多個步驟并利用多模態工具/能力的任務中,例如網頁模仿(WPI)、圖像到HTML代碼生成(I2C)和文本轉圖像(T2I),Data Interpreter是唯一能夠執行所有步驟的框架。
而在電子郵件自動回復(ER)任務中,AutoGen和OpenInterpreter因為無法登錄并獲取郵箱狀態,導致完成率較低,而Data Interpreter可以在執行過程中動態調整任務,從而在完成率上達到0.98。
消融實驗
為了進一步探討相關方法的有效性,研究人員還進行了消融實驗。
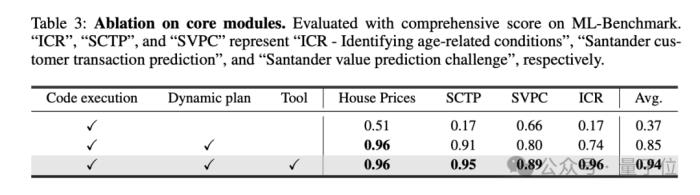
為評估各模塊性能,研究人員在ML-Benchmark上,使用了三種配置進行測試:
1)初始設置:基礎ReAct框架,包含簡單的任務理解提示詞以及支持代碼執行流程;2)增加了基于分層圖結構的動態計劃,包括分層規劃和每一步驟的動態管理,便于實時調整;3)在2)的基礎上增加了工具集成能力。
如表3所示,基于分層圖結構的動態計劃顯著提高了0.48分。它通過準備數據集并實時跟蹤數據變化有助于獲得更優性能,特別是完成率方面效果顯著。此外,工具的使用帶來了額外9.84%的改進,綜合得分達到了0.94分。
Data Interpreter還在包括GPT-4-Turbo、GPT-3.5-Turbo以及不同尺寸的LLMs上進行了實驗。
在機器學習的任務中,更大尺寸的LLM,例如Qwen-72B-Chat和Mixtral-8x7B展現出與GPT-3.5-Turbo相當的表現,而較小的模型則性能下降較多。
如下圖所示,結合Yi-34B-Chat、Qwen-14B-Chat和Llama2-13B-Chat,甚至DeepSeek-7B-Chat,Data Interpreter可以有效地處理數據加載及數據分析等步驟。
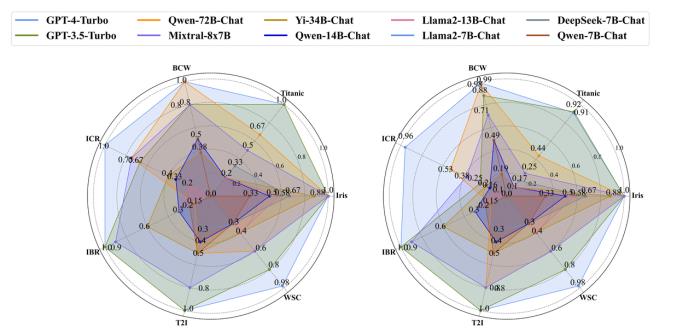
△在ML-BenchMark上使用不同尺寸LLM的評估。左圖:完成率,右圖:綜合得分
然而,這些模型在執行需要較高編碼能力的任務時面臨仍受到自身能力限制,通常導致流程無法完成。在開放式任務中,Mixtral-8x7B在3項任務上的完成率較高,但在網絡搜索和爬蟲(WSC)任務中表現不佳,難以準確地將完整結果輸出到CSV文件。與機器學習任務ML-Benchmark類似,規模較小的模型仍由于編碼能力受限而遇到執行失敗問題。
研究人員還針對經驗池的大小進行了消融實驗。按存儲任務級別的經驗數量,分別設置經驗池大小為0,80和200,對比Data Interpreter在不同任務上所需的代碼debug次數和執行成本的變化,結果如下所示:
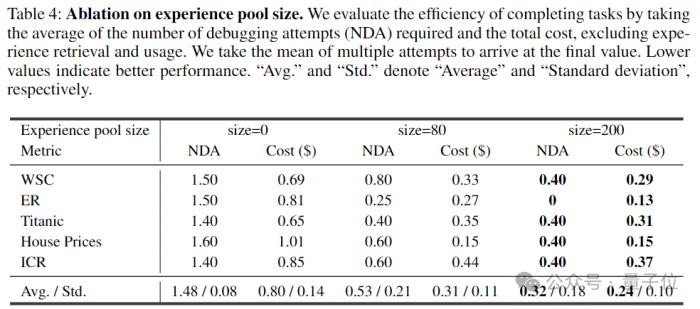
隨著經驗池從1增加至200,平均的debug次數從1.48降低到了0.32,執行成本從0.80美元降低到了0.24美元,表明經驗的累計對于從自然語言描述任務到代碼生成能夠有明顯的幫助。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
