

 新火種
2023-10-29
新火種
2023-10-29 


平安科技前沿技術部門負責人王磊:大規模預訓練模型在垂直領域應用的缺陷與改進

作者 | 王磊
整理 |維克多
編輯 | 青暮目前,大規模預訓練模型已經在自然語言處理領域取得了巨大的成功。BERT、GPT-3等大規模預訓練模型被看做是“暴力美學”的一次勝利,驗證了“模型越大,性能越好”的邏輯,業界也普遍形成了“煉大模型”的競賽趨勢,國內研究機構和企業也相繼發布了大規模預訓練模型,呈現百花齊放、百家爭鳴的發展格局。這些模型的實際應用情況如何?它們能解決哪些實際問題?還有哪些不足?
2021年12月,平安科技前沿技術部門負責人王磊在 CNCC 2021“產業共話:大型預訓練模型的商業應用及技術發展方向”論壇上,做了《大規模預訓練模型金融領域應用中面臨的主要問題與應對技術探討》的報告。在報告中,他指出了當前大規模預訓練模型在垂直領域的“致命”問題,針對這些問題提出了平安科技的解決方案。
例如,他認為大規模預訓練模型在垂直領域性能達不到要求的原因可能是:“大規模預訓練模型的訓練語料庫規模很大,既包含了該領域的關鍵信息也包含了其他無關信息,使得模型缺少對關鍵信息的關注”,“當前大規模預訓練模型的機制改進也也很少涉及對關鍵信息的提取”。
基于此,王磊認為,大規模預訓練模型本質上都是在處理信號,但只要是信號,就可能進行分解,將背景信息和垂直領域的信息分離開來,從而有效貼合下游場景。
另外,金融客戶對上線模型的精度要求很高,不少場景直接使用預加載模型往往很難滿足需求。王磊提出置信度評估方法,利用強化學習和Bagging思想評估模型靠譜程度。
以下是演講全文,AI科技評論做了不改變原意的整理。
本次分享的主題是《大規模預訓練模型金融領域應用中面臨的主要問題與應對技術探討》,主要以中國平安為案例,從問題背景、語義空間分解技術、置信度評估方法以及應用等幾個方面介紹。
問題背景
在平安公司場景下,大規模預訓練模型在金融業務上的應用主要集中在貸款風控與股市投資。同時,這兩個領域近些年的建模在因子層面會比較依賴大數據,例如文本信息,使用預訓練模型進行處理能夠形成一些特征因子,從而方便分析理解。
大規模預訓練模型已經在幾十個任務上刷榜,在醫療領域的表現更是令人瞠目結舌。但是深入到金融領域,其性能仍然無法滿足要求。以選股為例,傳統方法在信息獲取階段會人工從研報、雪球、知乎等論壇找尋一家公司的信息以及風評,然后結合基金經理或投資人自己的判斷獲得對這家公司的洞察,從而決定是否買進。
由于金融領域的容錯性特別低,而且要求模型對專業知識有很深的理解。如果達不到一定的理解水平,從業者寧可不用AI模型。

一般而言,對于單任務,一個模型的性能能達到90%,但如果需要理解一段話或者一段專業評語,則需要三層模型才能形成一定的特征,這時模型性能就會下降為70%左右的水平。因此,在投資等要求嚴格的場景下,預訓練模型很難應用。
為什么會出現這種問題?個人認為,大規模預訓練模型的語料庫是大型文本,它注重廣度和背景,對于深度和細節較少關注。
以國內企業研發的一些預訓練模型為例,其早期改進的方式都集中在Mask層面,而Msak機制更傾向于集中學習信息的廣度。而當模型應用到法律、醫學等領域時,更需要的是“深度”理解。
如何解決?目前有很多思路,例如加入專家知識,知識增強、混合訓練等等。目前,中國平安在探索語義空間分解技術和置信度評估方法。
語義空間分解技術
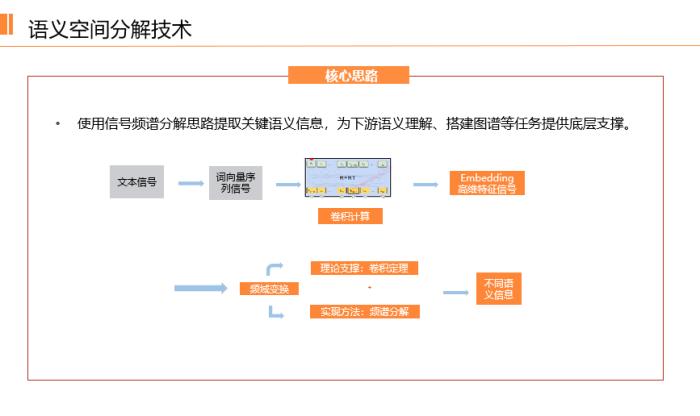
大規模預訓練模型涵蓋了很多背景信息,那么能否進行再一次的分解,將背景信息和垂直領域的知識體系分離開來?分解不能沒有標準和依據,而大規模語言模型實際上是在處理信號,當模型理解信號的時候,雖然信息和語義仍然在,但卻在中間發生了各種形式的變換。因此,無論是哪種大模型,其本質都是將信息或語義重新轉述為信號。
那么,既然是信號,就能夠進行分解。我們已經嘗試了多種方式,其中一種做法是:基于國內機構提出的大規模預訓練模型,加入高中低濾波器,然后用自適應頻譜機制進行處理,可以理解為一個Attention機制,最后進入下游任務訓練。
經過實驗表明,我們提出的頻譜分解網絡結構(Filter-Loss和Filter-layer ) ,結合經典語言模型訓練神經網絡,在各類型任務中均可顯著提升語言模型能力。
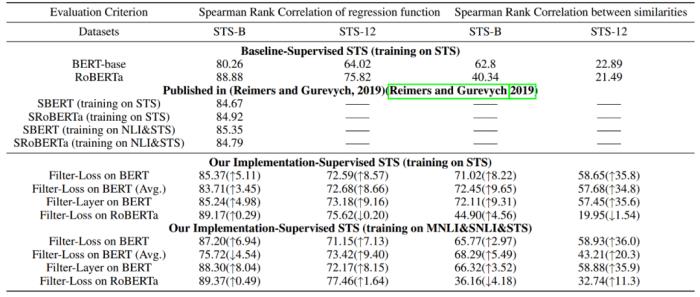
更為具體,不僅是在垂直領域,改進后的語言模型在11個國際公開數據集上測試結果較BERT模型提升3-20%。這也證明,將語義空間進行分離,然后和下游任務結合的做法具有通用性。
置信度評估方法
在金融領域,無論模型達到什么樣的水準,其上限永遠是客戶需求。例如客戶的標準是95%的性能,而模型只能達到92%,僅僅差3個百分點,就會讓模型很難上線。這類問題在金融企業非常容易遇到。
為了解決上述問題,平安科技提出了基于置信度評估的方法,通過這種方法,模型可以評估其“靠譜程度”。如果靠譜程度高,就通過,如果低,那么就需要人類接手,或者直接放棄。因為很多場景并不是信息越多越好,信息冗余已經成為了不可忽視的現象。
而且,還需要解決圍繞各類復雜經濟主體的多源異構大數據難以統一表述、信息難以整體耦合和關聯的問題。平安通過對數據標簽化提取的置信度技術研究,提升金融數據標簽化提取精度,提升流程自動化水平;通過對多尺度多維度融合語義關聯的經濟主體表達技術的研究,構建金融領域知識圖譜。
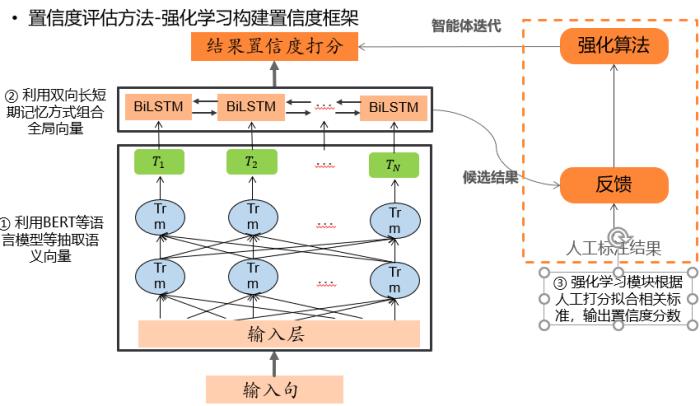
信度評估方法采用的是強化學習構建置信度框架。主要分為三個部分:
1.用BERT等語言模型等抽取語義向量
2.利用雙向長短期記憶方式組合全局向量
3. 強化學習模塊根據人工打分擬合相關標準,輸出置信度分數。
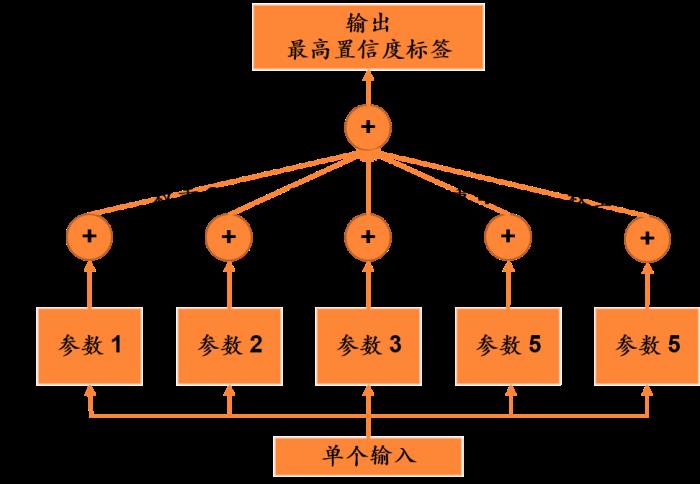
此外,還可以嘗試通過Bagging思想構建置信度框架。模型pipeline有4個階段:
1.利用Bagging思想,從數據中抽樣5份,訓練出5套模型參數;
2. 在少量測試集上測試各套參數性能,根據性能例如F1值,分配各模型置信度權重;
3. 各套參數選擇某個標簽后,在結果統計中累加對應參數權重;
4. 最終輸出累加置信度最高標簽。
技術應用

經過實驗證明,改進后的語言模型在語義相似度、多分類、語義蘊含等多類型國際公開數據集上測試精度較BERT模型的提升大多在10%-20%,但召回率下降20%-50%;在實際項目中從輿情中提取公司標簽的模型精度提升11個百分點,達到93%。
這在商業上非常有價值,例如雖然召回率降低了50個百分點,但意味著只有一半的模型需要人工干預,另一半的模型完全可以交給自動化,這遠比模型無法上線要好的多。
在金融領域,例如選股,模型的精準度是首先需要考慮的,其他指標可以稍差。例如從1000只備選股票中模型只選出了50只良好股票,可能會錯過50只良好股票。但這種錯過也是允許的,畢竟模型會“保證”選出來的50只股票大概率能夠賺錢或有超額收益。

相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
