

 新火種
2024-11-29
新火種
2024-11-29 

準確率84.09%,騰訊AILab發布Interformer,用于蛋白質-配體對接及親和力預測,登Nature子刊
編輯 | 蘿卜皮
近年來,深度學習模型在蛋白質-配體對接和親和力預測中的應用引起了越來越多的關注,而這兩者都對基于結構的藥物設計至關重要。
然而,許多此類模型忽略了復合物中配體和蛋白質原子之間相互作用的復雜建模,從而限制了它們的泛化和可解釋性。
在最新的研究中,騰訊 AI Lab 的研究人員提出了 Interformer,這是一個基于 Graph-Transformer 架構的統一模型。
該模型旨在利用交互感知混合密度網絡捕獲非共價相互作用。該團隊引入了負采樣策略,有助于有效校正相互作用分布以進行親和力預測。
這種方法可以通過準確模擬特定的蛋白質-配體相互作用來提高性能,且具備通用性。
該研究以「Interformer: an interaction-aware model for protein-ligand docking and affinity prediction」為題,于 2024 年 11 月 25 日發布在《Nature Communications》。

在錯綜復雜的藥物研發過程中,蛋白質-配體對接和親和力預測任務多年來一直是藥物發現過程中的重要組成部分。
蛋白質-配體對接是藥物分子結構優化的關鍵任務,目的是預測配體(小分子)與蛋白質受體或酶結合時的位置和方向。
親和力預測任務利用準確的結合姿勢(蛋白質-配體結合復合物構象),提供配體與其目標蛋白質之間結合強度的計算估計,從而有助于篩選具有潛在親和力的配體。
近年來,人們對使用深度學習 (DL) 方法進行分子建模的興趣激增。比如科學家將對接視為生成建模問題,引入了DiffDock,這是一種基于圖神經網絡 (GNN) 的模型,已在結合姿勢生成方面建立了基準。
然而,現有的深度學習模型往往忽視了蛋白質和配體原子之間非共價相互作用的建模,而這對于可解釋性和泛化至關重要。
如圖 1 左圖所示,DiffDock 產生的對接構象與晶體結構非常相似,但無法捕捉非共價相互作用。此外,雖然傳統的親和力預測方法在晶體結構方面表現出色,但在處理不太精確的結合姿勢時,其性能會急劇下降,這對實際應用構成了挑戰。
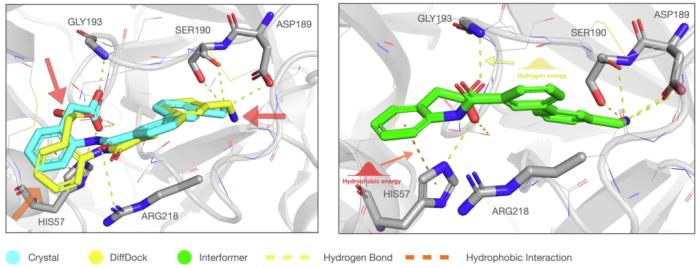
圖 1:對接姿勢中的非共價相互作用與現有和擬議方法的比較。(來源:論文)
新方法:Interformer
在最新的研究中,騰訊 AI Lab 的研究人員提出了 Interformer,這是一種計算 AI 模型,旨在緩解蛋白質-配體對接中的相互作用感知問題,并在實際應用中采用建設性學習進行親和力預測。
首先,研究人員提出了一種相互作用感知混合密度網絡 (MDN) 來模擬非共價相互作用,明確關注蛋白質-配體晶體結構中存在的氫鍵和疏水相互作用。如圖 1 右圖所示,Interformer 可以準確地產生結合姿勢中的特定相互作用。
其次,團隊提出了一個偽 Huber 損失函數,利用對比學習的能力來指導模型區分有利和不利的結合姿勢。
第三,該模型基于 Graph-Transformer 框架,該框架在各種圖表示學習任務中都表現出比基于 GNN 的模型更優的性能。
Interformer 的另一個優點是通過檢查 MDN 的融合系數來解釋蛋白質-配體相互作用的內部機制。
具體來說
Interformer 模型的架構靈感來自 Graph-Transformer,最初是為圖表示學習任務而提出的。
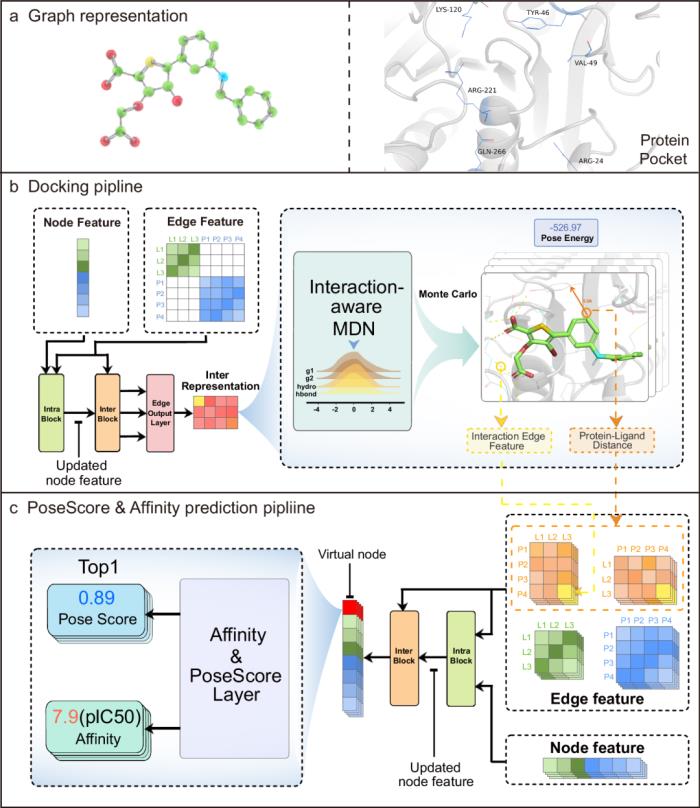
圖 2:Interformer 架構概述。(來源:論文)
在第一階段,該模型從晶體結構中獲取單個初始配體 3D 構象和蛋白質結合位點作為輸入。圖形在各種方法中被廣泛用于說明配體和蛋白質,如圖 2a 所示,其中節點代表原子,邊表示兩個原子之間的接近度。
研究人員使用藥效團原子類型作為節點特征,并使用兩個原子之間的歐幾里得距離作為邊緣特征。這些藥效團原子類型提供了必要的化學信息,從而使模型能夠更好地理解特定的相互作用,例如氫鍵或疏水相互作用。
在第二階段,對接流程如圖 2b 所示,通過 Intra-Blocks 處理來自蛋白質和配體的節點特征和邊緣特征。
Intra-Blocks 旨在通過捕獲同一分子內的內部相互作用來更新每個原子的節點特征。這些更新后的節點特征隨后輸入到 Inter-Blocks,捕捉蛋白質和配體原子對之間的相互作用,進一步更新節點和邊緣特征。
接著,通過交互感知的 MDN 預測每個蛋白質-配體原子對的四個高斯函數參數,并結合形成混合密度函數(MDF),用于估計蛋白質和配體原子之間最可能的距離。MDF 模型能夠精確反映特定的相互作用,如氫鍵和疏水作用,從而生成更加符合自然晶體結構的對接姿勢。
最后,所有蛋白質-配體對的 MDF 聚合后,通過蒙特卡洛采樣方法生成前 k 個候選配體構象。
在第三階段,姿勢得分和親和力預測管道如圖 2c 所示。生成的對接姿勢中蛋白質和配體原子之間的距離和特定相互作用更新了新的邊緣特征。
然后通過塊內和塊間處理節點和邊緣特征以創建隱式交互。虛擬節點通過自注意力機制收集有關綁定姿勢的所有信息。
最后,虛擬節點的綁定嵌入被輸入到親和力和姿勢層,以預測相應對接姿勢的綁定親和力值和置信姿勢得分。
通過納入不良姿勢,對比性偽 Huber 損失函數可用于指導模型辨別姿勢是好還是壞。訓練目標可確保模型為不良姿勢預測較低的值,為良好姿勢預測較高的值。良好姿勢與不良姿勢之間的主要區別在于它們的相互作用。
此策略可幫助模型學習關鍵相互作用,而不是人工特征。研究人員將此特性稱為 pose-sensitive,在現實世界的藥物開發項目中表現出色。
性能評估
當使用兩個廣泛使用的基準對蛋白質-配體對接進行評估時,Interformer 在 Posebusters 基準上實現了 84.09% 的準確率,在 PDBbind 時間分割基準上實現了 63.9% 的準確率,且均方根偏差 (RMSD) 小于 2??,從而實現了 top-1 預測性能。
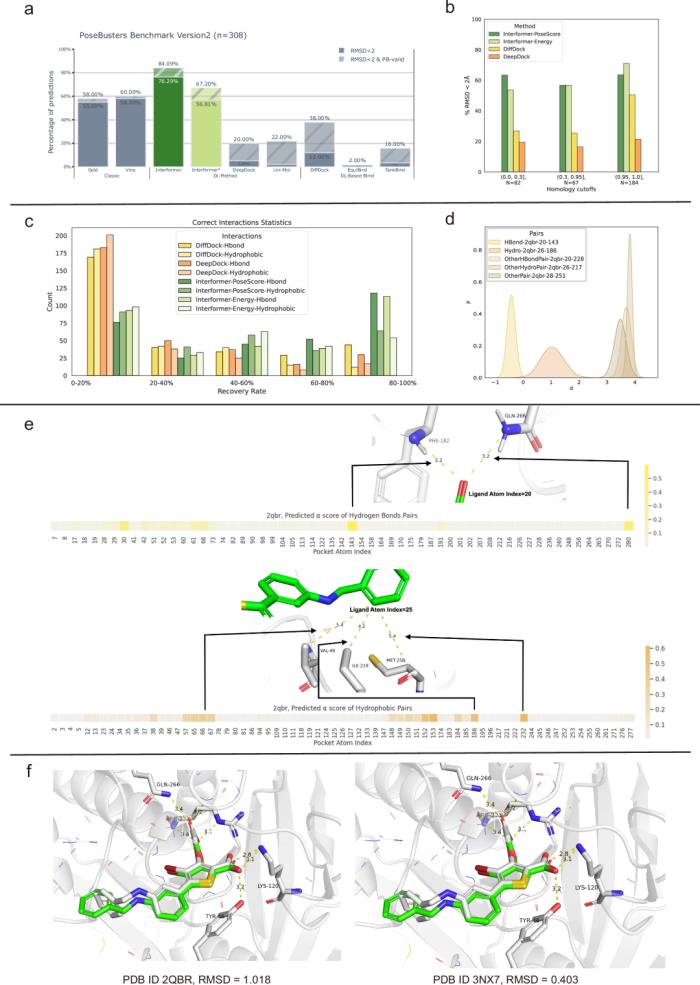
圖 3:對蛋白質-配體對接任務的評估。(來源:論文)
這一改進歸功于該模型增強了捕捉配體和蛋白質之間非共價相互作用的能力,這對于產生不太模糊的構象至關重要,對于下游任務的成功執行至關重要。
此外,即使綁定姿勢不太準確,該模型也能預測合理的親和力值。團隊內部真實世界基準的評估表明,該模型的性能與其他模型相當,證實了其姿勢敏感和強大的泛化能力。
在應用于真實的內部藥物管道時,研究人員成功鑒定出兩個小分子,在各自的項目中,每個小分子的親和力 IC50 值分別為 0.7 nM 和 16 nM,從而證明了其在推進治療發展方面的實用價值。
這種方法使 Interformer 能夠通過關注蛋白質和配體原子對之間的特定相互作用來區分不太準確和更有利的對接姿勢。這種強大的功能使該模型能夠增強在現實場景中預測的通用性。
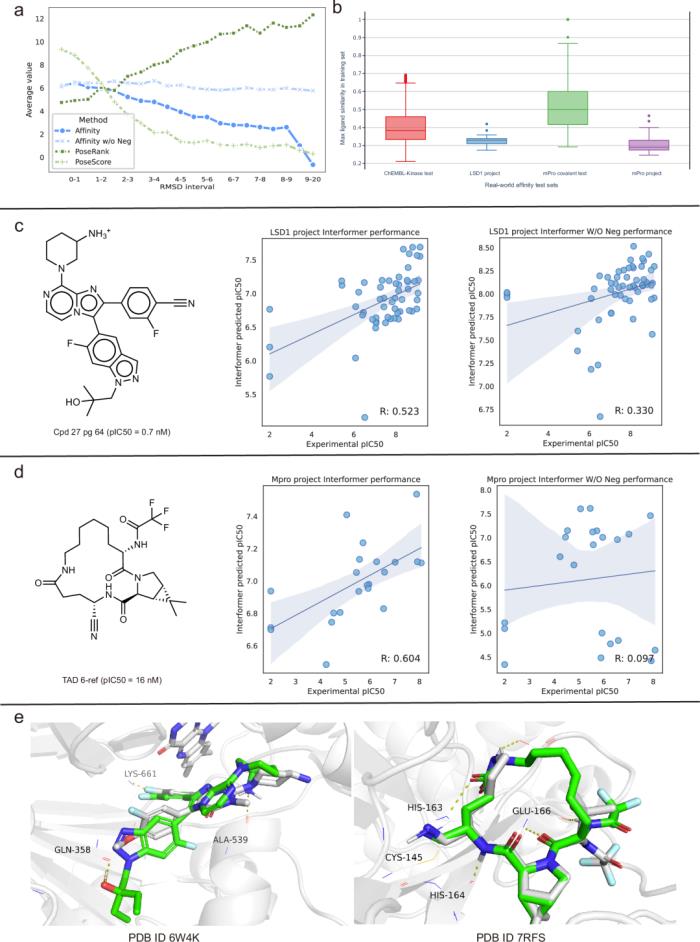
在親和力預測領域,Interformer 在四個內部真實世界親和力基準上表現出持續的進步。Interformer 在兩個內部藥物開發流程中的進一步應用已成功在納摩爾水平上識別出兩種高效分子。
該研究展示了 Interformer 對計算生物學和加速藥物設計過程的巨大潛力。
未來,研究人員的目標是將 Interformer 的應用擴展到更廣泛的現實世界生物挑戰中,并增強其對各種分子相互作用類型的性能,包括蛋白質-蛋白質和蛋白質-核酸相互作用。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
