

 新火種
2024-06-11
新火種
2024-06-11 


OpenAI公開破解GPT-4思維的新方法,Ilya也參與了!
OpenAI研究如何破解GPT-4思維,公開超級對齊團隊工作,Ilya Sutskever也在作者名單之列。
該研究提出了改進大規模訓練稀疏自編碼器的方法,并成功將GPT-4的內部表征解構為1600萬個可理解的特征。
由此,復雜語言模型的內部工作變得更加可理解。

其實,早在6個月前,研究就已經開始進行了:
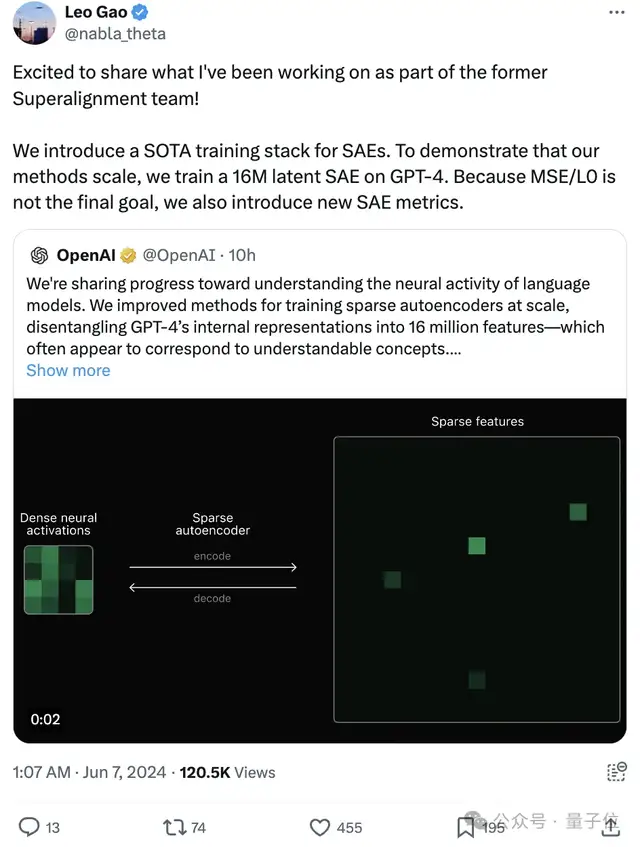
OpenAI將其公開后,前超級對齊團隊成員、論文一作前來轉發分享:
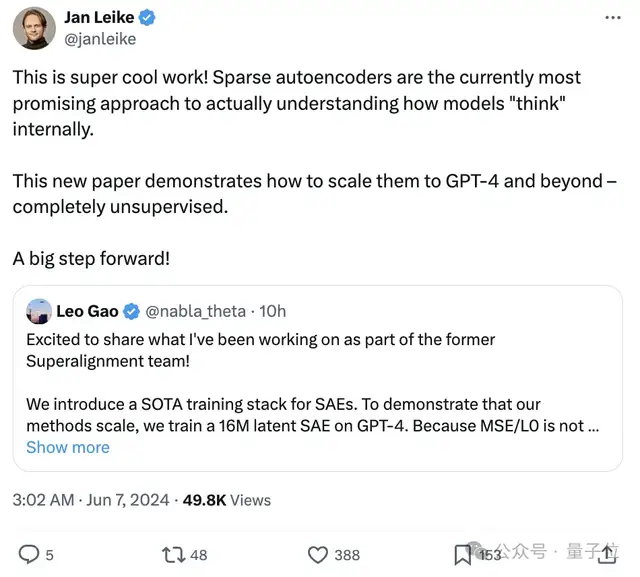
同樣在坐著名單里的、此前在OpenAI超級對齊團隊的Ilya同盟Jan Leike(就是從OpenAI憤而離職剛剛加入Anthropic的RLHF發明者之一)也表示:
更有意思的是,不久前Anthropic發了一項類似的工作。
成功從Claude 3.0 Sonnet的中間層提取了數百萬個特征,為其計算過程中的內部狀態提供了一個大致的概念性圖。

于是有網友就開麥了,工作牛是牛,但OpenAI是不是有點太著急了,論文鏈接沒有指向Arxiv,分析似乎也沒有那么深入。

回歸正題,OpenAI超級對齊團隊是如何想法子破解GPT-4思維的?
在OpenAI新公布研究中再見Ilya的名字
目前,語言模型神經網絡的內部工作原理仍是個“黑盒”,無法被完全理解。
為了理解和解釋神經網絡,首先需要找到對神經計算有用的基本構件。
然鵝,神經網絡中的激活通常表現出不可預測和復雜的模式,且每次輸入幾乎總會引發很密集的激活。而現實世界中其實很稀疏,在任何給定的情境中,人腦只有一小部分相關神經元會被激活。
由此,研究人員開始研究稀疏自編碼器,這是一種能在神經網絡中識別出對生成特定輸出至關重要的少數“特征”的技術,類似于人在分析問題時腦海中的那些關鍵概念。
它們的特征展示出稀疏的激活模式,這些模式自然地與人類易于理解的概念對齊,即使沒有直接的可解釋性激勵。
不過,現有的稀疏自編碼器訓練方法在大規模擴展時會面臨重建與稀疏性權衡、latent失活等問題。
在OpenAI超級對齊團隊的這項研究中,他們推出了一種基于TopK激活函數的新稀疏自編碼器(SAE)訓練技術棧,消除了特征縮小問題,能夠直接設定L0(直接控制網絡中非零激活的數量)。
該方法在均方誤差(MSE)與L0評估指標上表現優異,即使在1600萬規模的訓練中,幾乎不產生失活的潛在單元(latent)。
具體來看,他們使用GPT-2 small和GPT-4系列模型的殘差流作為自編碼器的輸入,選取網絡深層(接近輸出層)的殘差流,如GPT-4的5/6層、GPT-2 small的第8層。
并使用之前工作中提出的基線ReLU自編碼器架構,編碼器通過ReLU激活獲得稀疏latent z,解碼器從z中重建殘差流。損失函數包括重建MSE損失和L1正則項,用于促進latent稀疏性。
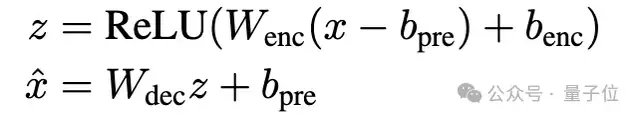
然后,團隊提出使用TopK激活函數代替傳統L1正則項。TopK在編碼器預激活上只保留最大的k個值,其余清零,從而直接控制latent稀疏度k。
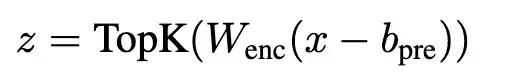
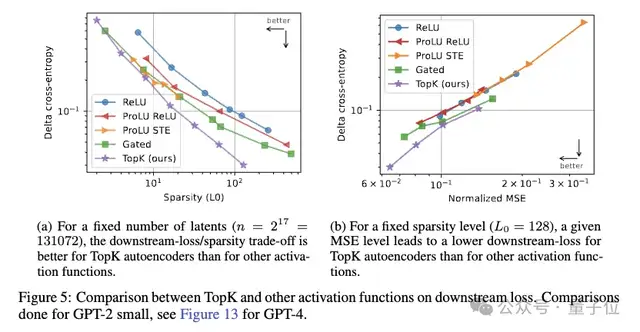
不需要L1正則項,避免了L1導致的激活收縮問題。實驗證明,TopK相比ReLU等激活函數,在重建質量和稀疏性之間有更優的權衡。
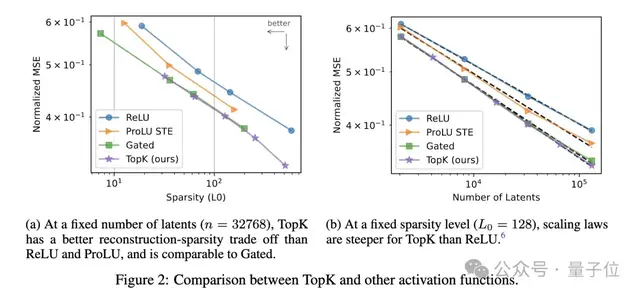
此外,自編碼器訓練時容易出現大量latent永遠不被激活(失活)的情況,導致計算資源浪費。
團隊的解決方案包括兩個關鍵技術:
將編碼器權重初始化為解碼器權重的轉置,使latent在初始化時可激活。添加輔助重建損失項,模擬用top-kaux個失活latent進行重建的損失。
如此一來,即使是1600萬latent的大規模自編碼器,失活率也只有7%。
團隊還提出了多重TopK損失函數的改進方案,提高了高稀疏情況下的泛化能力,并且探討了兩種不同的訓練策略對latent數量的影響,這里就不過多展開了。
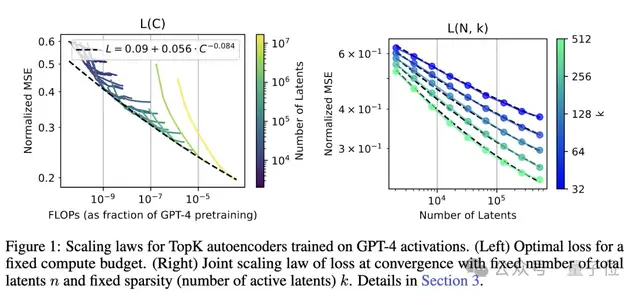
為了證明該方法的可擴展性,團隊訓練了上述提到的一個具有1600萬個latent的稀疏自編碼器,并在GPT-4模型的激活上處理了40億個token。
在GPT-4激活上處理40億token
接下來,評估自編碼器質量的關鍵在于提取出的特征是否對下游應用任務有用,而不僅僅是優化重建損失和稀疏性。
因此,團隊提出了幾種評估自編碼器質量的新方法,包括:
下游損失(Downstream Loss):評估自編碼器重建的latent對語言模型性能的影響。探測損失(Probe Loss):檢查自編碼器是否能夠恢復我們認為可能發現的特征。可解釋性(Explainability):評估自編碼器latent的激活是否能夠通過簡單且精確的解釋來理解。剔除稀疏性(Ablation sparsity):評估移除個別latent對下游預測的影響。
實驗發現,TopK自編碼器在下游損失上的改進幅度超過了重建MSE的改進。
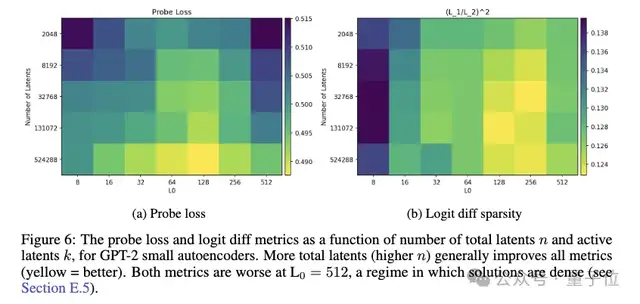
探測損失隨latent數量增加而改善,但在某些區間會先升后降。
此外,研究人員發現精確度和召回率在latent數量較大、稀疏度適中時最優。
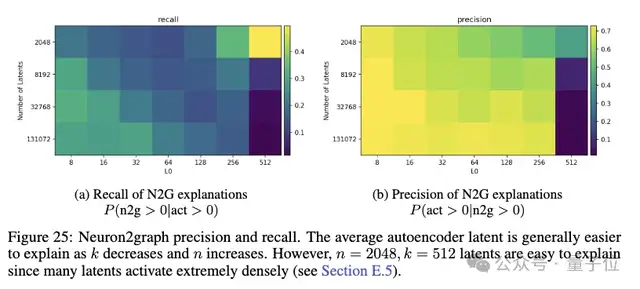
TopK模型相比ReLU模型有更高的召回率,能更好地壓制虛假激活。
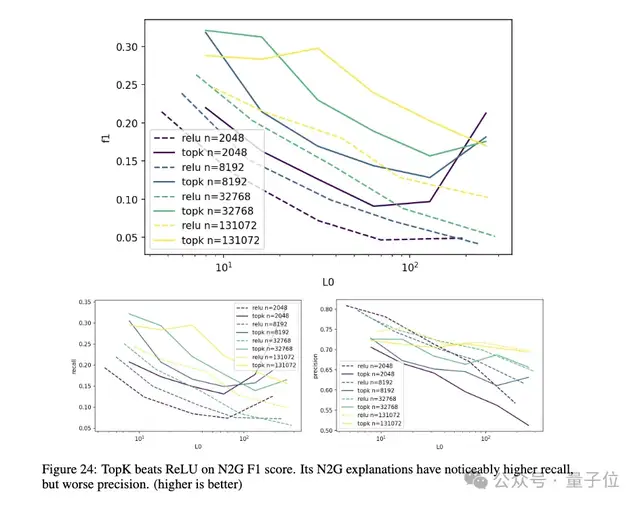
剔除稀疏性方面(見上圖6 b),團隊發現自編碼器latent的影響較為稀疏,遠小于直接ablating殘差流通道。但當稀疏度k過高時,影響的稀疏性會下降。
最后,論文一作表示稀疏自編碼器的問題仍然遠未解決,這項研究中的SAE只捕獲了GPT-4行為的一小部分,即使看起來單義的latent也可能難以精確解釋。而且,從表現優異的SAE到更好地理解模型的行為,還需要大量的工作。
關于這項研究的更多細節,感興趣的家人可以查看原論文。
OpenAI還公開發布了完整源代碼和針對GPT-2的多個小規模自編碼器模型權重。還發布了一個在線可視化工具,用于查看包括這個1600萬latent GPT-4自編碼器在內的多個模型的激活特征。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
