清華團隊提出機器學習設計新方法,快速優化多目標超材料結構
2021 年,美國骨科及醫療科技公司史賽克(Stryker)由于骨植入物強度不夠而被召回相關產品,引起領域內的高度關注。那么,這種現象是否有可能從源頭被解決呢?清華大學溫鵬副教授團隊以解決實際應用問題為出發點,提出一種數據高效的新方法:生成式設計-多目標主動學習循環方法。
2021 年,美國骨科及醫療科技公司史賽克(Stryker)由于骨植入物強度不夠而被召回相關產品,引起領域內的高度關注。那么,這種現象是否有可能從源頭被解決呢?清華大學溫鵬副教授團隊以解決實際應用問題為出發點,提出一種數據高效的新方法:生成式設計-多目標主動學習循環方法。

現在,視頻生成模型無需訓練即可加速了?!Meta提出了一種新方法AdaCache,能夠加速DiT模型,而且是無需額外訓練的那種(即插即用)。話不多說,先來感受一波加速feel(最右):可以看到,與其他方法相比,AdaCache生成的視頻質量幾乎無異,而生成速度卻提升了2.61倍。據了解,AdaCac

選自Stanford News機器之心編譯參與:劉曉坤、李澤南斯坦福大學的研究者們正在使用計算機視覺系統,利用谷歌街景圖片上街邊汽車的型號來識別給定社區的政治傾向,其識別準確率超過了 80%。這項研究的論文已發表在《美國科學院論文集》上,研究人員表示,新的研究不僅可以節省大量人力開支,也可以為人口統

“越大越好”的路徑走不通?OpenAI正在尋求訓練模型的新方法

人工智能 AI 正在加快速度從云端走向邊緣,進入到越來越小的物聯網設備中。而這些物聯網設備往往體積很小,面臨著許多挑戰,例如功耗、延時以及精度等問題,傳統的機器學習模型無法滿足要求,

摩爾線程科研團隊近日發布了一項新的研究成果《Round Attention:以輪次塊稀疏性開辟多輪對話優化新范式》,使得端到端延遲低于現在主流的Flash Attention推理引擎,kv-cache顯存占用節省最多82%。

美圖影像研究院(MT Lab)與中國科學院大學突破性地提出了基于文生圖模型的視頻生成新方法EI2,用于提高視頻編輯過程中的語義和內容兩方面的一致性。該論文從理論角度分析和論證視頻編輯過程中出現的不一致的問題,主要由引入的時序信息學習模塊使特征空間出現協變量偏移造成,
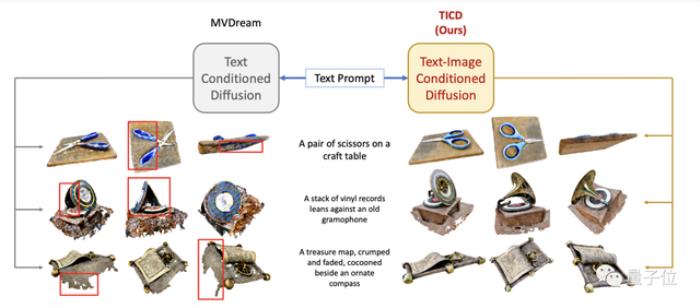
近日,清華大學劉永進教授課題組提出了一種基于擴散模型的文生3D新方式。無論是不同視角間的一致性,還是與提示詞的匹配度,都比此前大幅提升。文生3D是3D AIGC的熱點研究內容,得到了學術界和工業界的廣泛關注。

OpenAI研究如何破解GPT-4思維,公開超級對齊團隊工作,Ilya Sutskever也在作者名單之列。該研究提出了改進大規模訓練稀疏自編碼器的方法,并成功將GPT-4的內部表征解構為1600萬個可理解的特征。由此,復雜語言模型的內部工作變得更加可理解。其實,早在6個月前,研究就已經開始進行了:

神經網絡的性能評估 (精度、召回率、PSNR 等) 需要大量的資源和時間,是神經網絡結構搜索(NAS)的主要瓶頸。早期的 NAS 方法需要大量的資源來從零訓練每一個搜索到的新結構。近幾年來,網絡性能預測器作為一種高效的性能評估方法正在引起更多關注。然而,當前的預測器在使用范圍上受限,因為它們只能建模