

 新火種
2024-01-19
新火種
2024-01-19 

谷歌數學AI登Nature:IMO金牌幾何水平,定理證明超越吳文俊法
谷歌DeepMind再發Nature,Alpha系列AI重磅回歸,數學水平突飛猛進。

有當年AlphaZero無需人類知識學圍棋《Mastering the game of Go without human knowledge》的感覺了。
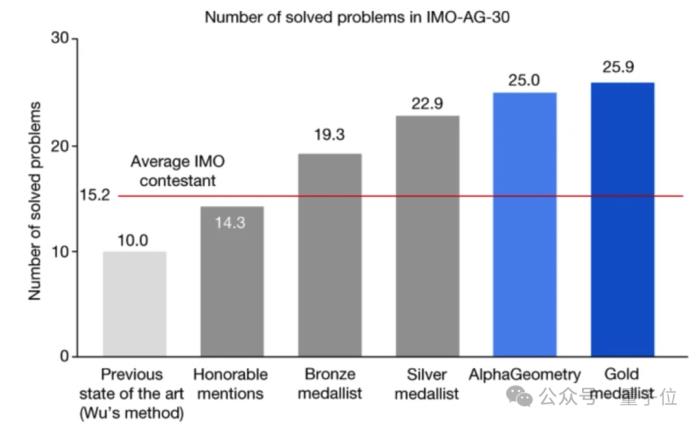
具體來說,30道IMO難度的幾何定理證明題,AlphaGeometry做對25道,人類金牌選手平均25.9道,之前SOTA方法(1978年的吳文俊法)做對10道。
IMO金牌得主陳誼廷(Evan Chen)負責評估AI生成的答案,他評價到:
除成績亮眼之外,這項研究中還有三個重點引起業界關注:
無需人類演示,也就是只用了AI合成數據訓練,延續了AlphaZero自學圍棋的方式。大模型結合其他AI方法,與AlphaGo和OpenAI Q*傳聞相似。與許多先前方法不同,AlphaGeometry可以生成人類可讀的證明過程,且模型和代碼都開源。
團隊認為,AlphaGeometry提供了一個實現高級推理能力、發現新知識的潛在框架。

另外,新火種在與作者團隊交流過程中,打聽到了是否真的會讓AlphaGeometry去參加一屆IMO競賽,就像當年AlphaGo挑戰人類圍棋冠軍一樣。
他們表示正在努力提高系統的能力,還需要讓AI能解決幾何之外更廣泛的數學問題。
AI證明幾何也畫輔助線
此前AI系統不能很好解決幾何問題,卡就卡在缺乏優質訓練數據。
人類學習幾何可以借助紙和筆,在圖像上使用現有知識來發現新的、更復雜的幾何屬性和關系。
谷歌團隊為此用生成了10億個隨機幾何對象圖,以及其中點和線間的所有關系,最終篩選出1億不同難度的獨特定理和證明,AlphaGeometry在這些數據上完全從頭訓練。

系統由兩個模塊組成,相互配合尋找復雜的幾何證明。
語言模型,預測可用來解決問題的幾何結構(也就是添加輔助線)。符號推理引擎,使用邏輯規則推導出結論。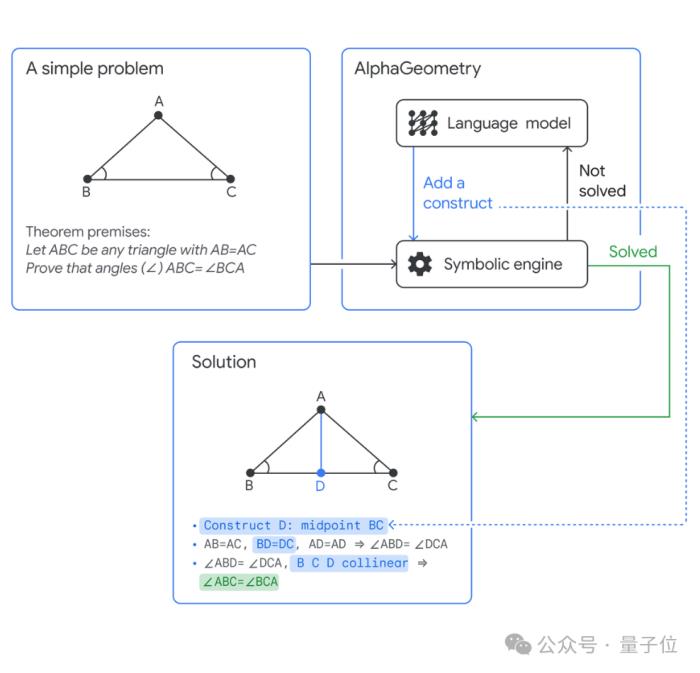
一作Trieu Trinh介紹,AlphaGeometry的運作過程類似人腦分為快與慢兩種類型。
也就是諾貝爾經濟學獎得主丹尼爾·卡尼曼的暢銷書《思考快與慢》中普及的“系統1、系統2”概念。
系統1提供快速、直觀的想法,系統2提供更加深思熟慮、理性的決策。
一方面,語言模型擅長識別數據中的模式和關系,可以快速預測潛在有用的輔助結構,但通常缺乏嚴格推理或解釋其決策的能力。
另一方面,符號推理引擎基于形式邏輯并使用明確的規則來得出結論。它們是理性且可解釋的,但它們緩慢且不靈活,尤其是在獨自處理大型、復雜的問題時。
例如在解決一道IMO 2015年的競賽題時,藍色部分為AlphaGeometry的語言模型添加的輔助結構,綠色部分是最終證明的精簡版,共有109個步驟。
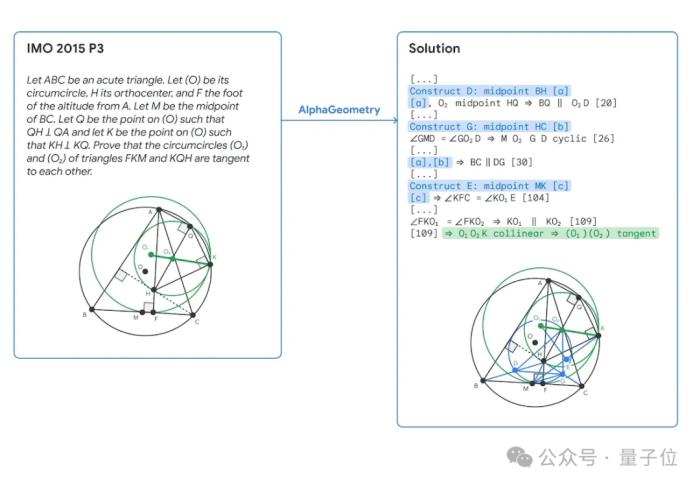
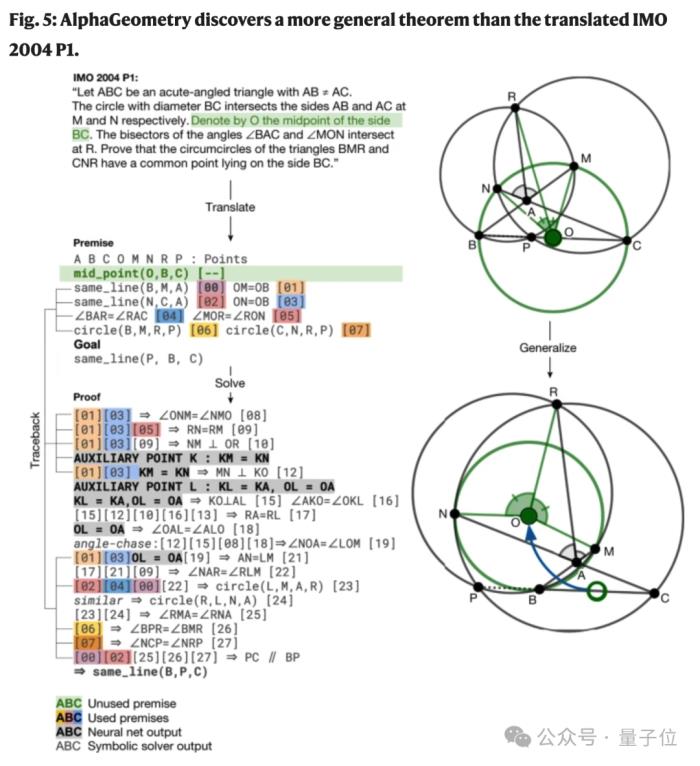
在做題過程中,AlphaGeometry還發現了2004年IMO競賽題中一個未使用的前提條件,并因此發現了更廣義的定理版本。
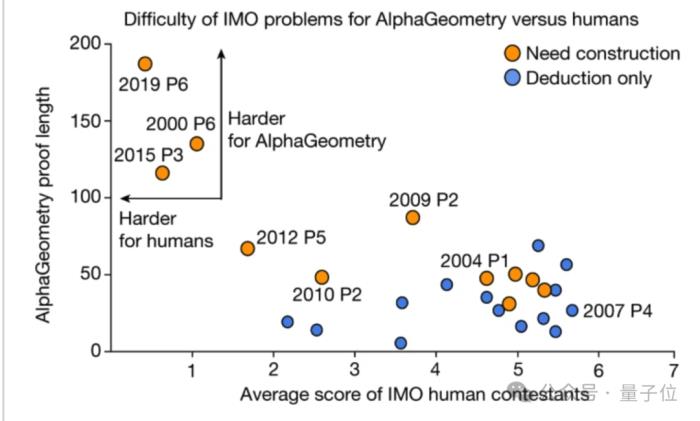
另外研究還發現,對于人類得分最低的3個問題,AlphaGeometry也需要非常長的證明過程和添加非常多的輔助結構才能解決。
但在相對簡單的問題上,人類平均得分和AI生成的證明長度之間沒有顯著相關性 (p?=??0.06)。
 One More Thing
One More Thing
對于AlphaGeometry與AlphaGo的聯系和區別,在與團隊交流過程中,谷歌科學家Quoc Le介紹到:
雖然這次成果隨Alpha系列命名,第一單位也是Google DeepMind,但其實作者主要是前谷歌大腦成員。
Quoc Le大神不用過多介紹,一作Trieu Trinh與通訊作者Thang Luong都在谷歌工作了六七年,Thang Luong自己高中時也是IMO選手。
兩位華人作者中,何河是紐約大學助理教授。吳宇懷此前參與了谷歌數學大模型Minerva研究,現在已經離開谷歌加入馬斯克團隊,成為xAI的聯合創始人之一。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
