

 新火種
2024-12-28
新火種
2024-12-28 


國產大模型DeepSeek-V3一夜火爆全球,671B的MoE,訓練成本僅558萬美元
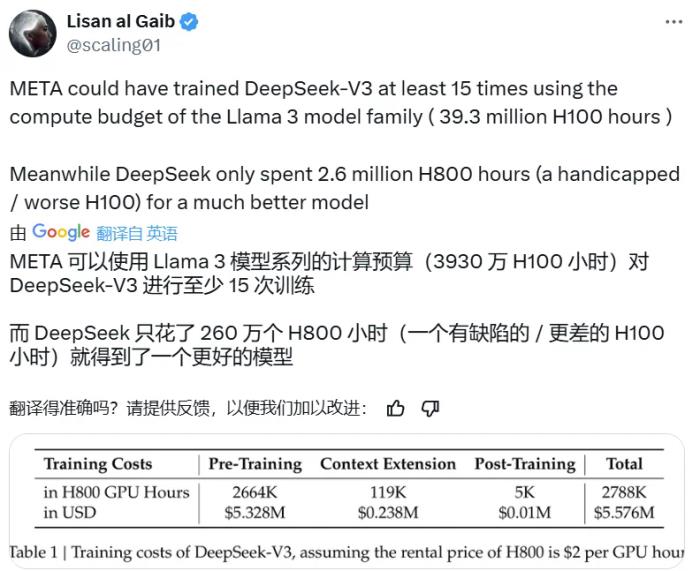
今天,一個國產大模型火遍了世界。打開 X,滿眼都是討論 DeepSeek-V3 的推文,而其中最熱門的話題之一是這個參數量高達 671B 的大型語言模型的預訓練過程竟然只用了 266.4 萬 H800 GPU Hours,再加上上下文擴展與后訓練的訓練,總共也只有 278.8 H800 GPU Hours。相較之下,Llama 3 系列模型的計算預算則多達 3930 萬 H100 GPU Hours—— 如此計算量足可訓練 DeepSeek-V3 至少 15 次。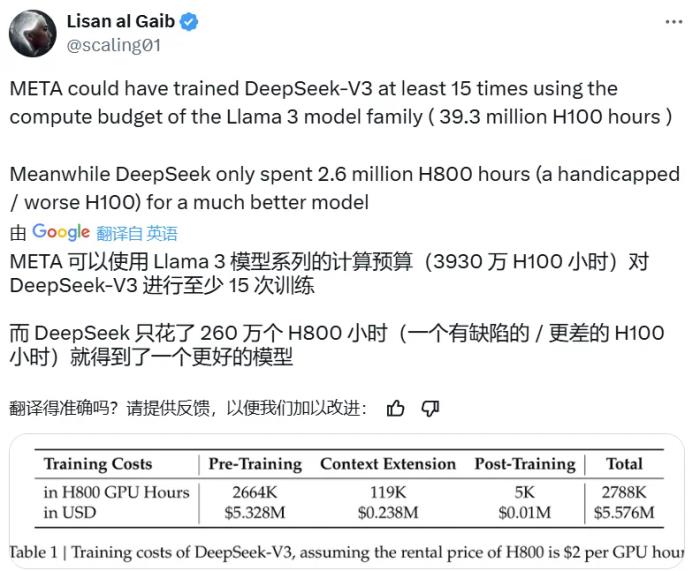
雖然相對于其它前沿大模型, DeepSeek-V3 消耗的訓練計算量較少,但其性能卻足以比肩乃至更優。據最新發布的 DeepSeek-V3 技術報告,在英語、代碼、數學、漢語以及多語言任務上,基礎模型 DeepSeek-V3 Base 的表現非常出色,在 AGIEval、CMath、MMMLU-non-English 等一些任務上甚至遠遠超過其它開源大模型。就算與 GPT-4o 和 Claude 3.5 Sonnet 這兩大領先的閉源模型相比,DeepSeek-V3 也毫不遜色,并且在 MATH 500、AIME 2024、Codeforces 上都有明顯優勢。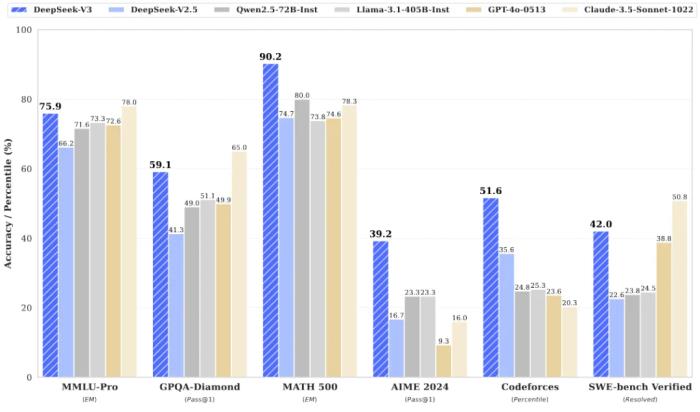 DeepSeek-V3 的驚人表現主要是得益于其采用的 MLA(多頭隱注意力)和 DeepSeekMoE 架構。此前,這些技術已經在 DeepSeek-V2 上得到了驗證,現在也成為了 DeepSeek-V3 實現高效推理和經濟訓練的基石。此外,DeepSeek-V3 率先采用了無輔助損失的負載平衡策略,并設定了多 token 預測訓練目標,以實現更強大的性能。他們使用的預訓練 token 量為 14.8 萬億,然后還進行了監督式微調和強化學習。正是在這些技術創新的基礎上,開源的 DeepSeek-V3 一問世便收獲了無數好評。
DeepSeek-V3 的驚人表現主要是得益于其采用的 MLA(多頭隱注意力)和 DeepSeekMoE 架構。此前,這些技術已經在 DeepSeek-V2 上得到了驗證,現在也成為了 DeepSeek-V3 實現高效推理和經濟訓練的基石。此外,DeepSeek-V3 率先采用了無輔助損失的負載平衡策略,并設定了多 token 預測訓練目標,以實現更強大的性能。他們使用的預訓練 token 量為 14.8 萬億,然后還進行了監督式微調和強化學習。正是在這些技術創新的基礎上,開源的 DeepSeek-V3 一問世便收獲了無數好評。
 Meta AI 研究科學家田淵棟對 DeepSeek-V3 各個方向上的進展都大加贊賞。
Meta AI 研究科學家田淵棟對 DeepSeek-V3 各個方向上的進展都大加贊賞。
著名 AI 科學家 Andrej Karpathy 也表示,如果該模型的優良表現能夠得到廣泛驗證,那么這將是資源有限情況下對研究和工程的一次出色展示。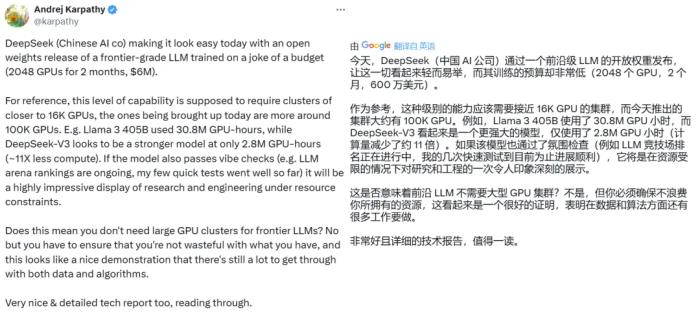
正在創業(Lepton AI)的著名研究者賈揚清也給出了自己的深度評價。他認為 DeepSeek-V3 的誕生標志著我們正式進入了分布式推理的疆域,畢竟 671B 的參數量已經無法放入單臺 GPU 了。
DeepSeek-V3 再一次引爆了人們對開源模型的熱情。OpenRouter 表示自昨天發布以來,該平臺上 DeepSeek-V3 的使用量已經翻了 3 倍!

一些已經嘗鮮 DeepSeek-V3 的用戶已經開始在網上分享他們的體驗。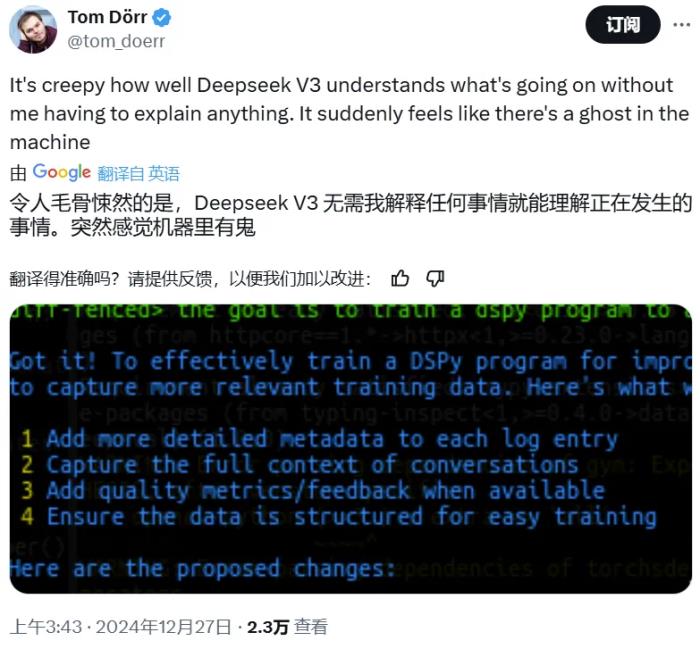
接下來我們看技術報告內容。
報告地址:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf項目地址:https://github.com/deepseek-ai/DeepSeek-V3Hugging Face:https://huggingface.co/collections/deepseek-ai/deepseek-v3-676bc4546fb4876383c4208b架構為了高效的推理和經濟的訓練,DeepSeek-V3 采用了用于高效推理的多頭潛在注意力(MLA)(DeepSeek-AI,2024c)和用于經濟訓練的 DeepSeekMoE(Dai et al., 2024),并提出了多 token 預測(MTP)訓練目標,以提高評估基準的整體性能。對于其他細節,DeepSeek-V3 遵循 DeepSeekV2(DeepSeek-AI,2024c)的設置。與 DeepSeek-V2 相比,一個例外是 DeepSeek-V3 為 DeepSeekMoE 額外引入了輔助無損耗負載平衡策略(Wang et al., 2024a),以減輕因確保負載平衡而導致的性能下降。圖 2 展示了 DeepSeek-V3 的基本架構: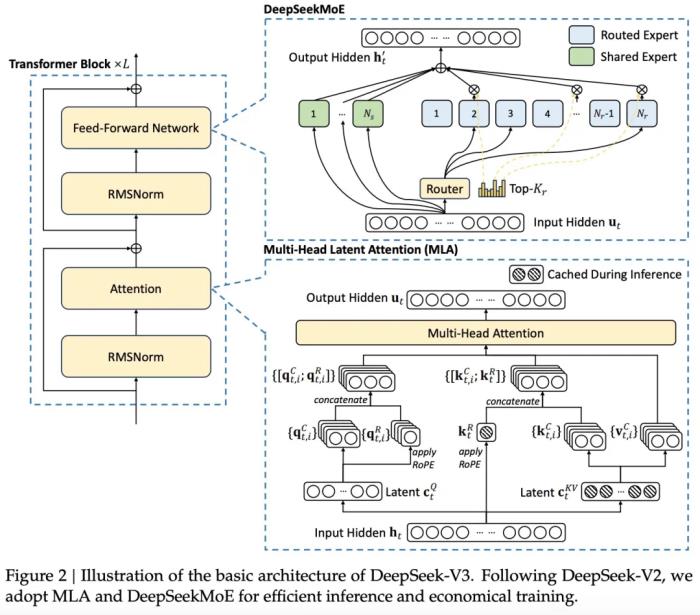
MTP 將預測范圍擴展到每個位置的多個未來 token。一方面,MTP 目標使訓練信號更加密集,并且可以提高數據效率。另一方面,MTP 可以使模型預規劃其表征,以便更好地預測未來的 token。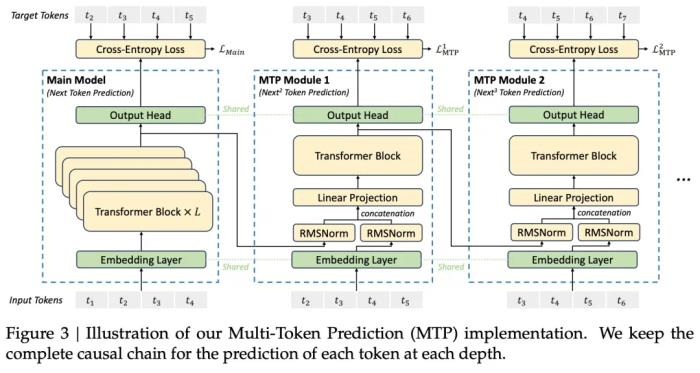
預訓練數據構建與 DeepSeek-V2 相比,V3 通過提高數學和編程樣本的比例來優化預訓練語料庫,同時將多語言覆蓋范圍擴大到英語和中文之外。此外,新版本對數據處理流程也進行了改進,以最大限度地減少冗余,同時保持語料庫的多樣性。DeepSeek-V3 的訓練語料在 tokenizer 中包含 14.8T 個高質量且多樣化的 token。超參數模型超參數:本文將 Transformer 層數設置為 61,隱藏層維度設置為 7168。所有可學習參數均以標準差 0.006 隨機初始化。在 MLA 中,本文將注意力頭
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
