

 新火種
2024-12-26
新火種
2024-12-26 

基于集成網絡的離線到在線強化學習
01 前言
強化學習(Reinforcement Learning, RL)有兩種基礎的訓練范式:在線強化學習(Online RL)和離線強化學習(Offline RL)。在線強化學習需要讓智能體和環境進行交互,利用收集到的數據同步進行訓練,但在環境中進行探索的開銷很大;離線強化學習不需要和環境交互,直接利用已有的離線數據進行訓練,但這種范式訓練的智能體會受限于離線數據的質量和覆蓋范圍。
基于此,研究者提出了離線到在線強化學習(Offline-to-online RL)訓練范式,先利用已有的離線數量訓練得到離線策略,然后將其應用到在線環境進行少量步數的微調。這種范式相比于前兩者,一方面通過收集少量的在線數據,能夠突破離線數據的限制,更貼近實際場景;另一方面在線階段的微調是以離線策略為起點,相比于從零開始的在線強化學習,只需要非常少量的交互就能快速收斂。這一研究領域主要研究兩個問題,一個是分布偏移引起的性能下降,就是如果直接將離線策略應用到在線環境進行微調,會在微調初期出現性能的急劇下降;另一個是在線優化效率,由于在線交互的開銷很大,需要用盡可能少的交互次數實現盡可能大的性能提升,這兩者可以歸結于穩定性和高效性。
在IJCAI 2024上,嗶哩嗶哩人工智能平臺部聯合天津大學將集成Q網絡(Q-ensembles)引入到離線到在線強化學習訓練范式中,提出了基于集成網絡的離線到在線強化學習訓練框架(ENsemble-based Offline-To-Online RL, ENOTO)。ENOTO以集成Q網絡為基礎,充分利用其衡量的不確定性來穩定兩個階段的過渡和鼓勵在線探索,可以結合多種強化學習算法作為基線算法,在離線到在線強化學習設定下提升穩定性和學習效率,具有較好的泛用性。團隊在強化學習的經典環境MuJoCo、AntMaze任務和多種質量的數據集上對ENOTO進行了廣泛的實驗驗證,和以往的離線到在線強化學習算法相比,很大程度地提升了穩定性和學習效率,在大部分數據集上的累積收益提升約有10% - 25%。
02 動機
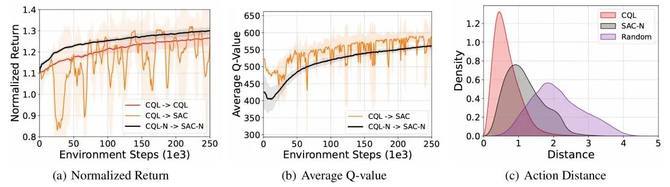
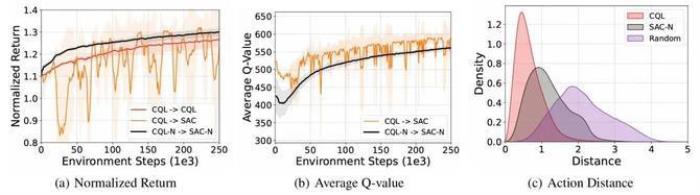
對于早期的離線強化學習算法,如Conservative Q-Learning(CQL)[1],會顯式懲罰分布外樣本的Q值,鼓勵策略選擇數據集內的動作,而這種思想在Double DQN中就有提到。因此我們可以將這里的Q網絡從2個增加到N個,這就是集成Q網絡。令人驚訝的是,這種簡單的改變對于離線到在線強化學習的提升卻是非常明顯的。我們首先進行了一項驗證性實驗,使用CQL這個被廣泛認可的代表性離線強化學習算法作為基線算法,在經典的強化學習環境MuJoCo上進行實驗,實驗結果如圖1所示。離線到在線強化學習訓練有兩種很簡單的方法,一個是在線階段繼續復用離線強化學習算法,也就是這里的CQL→CQL,但由于離線強化學習算法的保守性,在線優化效率會很低,即圖1(a)中的紅線;另一個是切換到在線強化學習算法,也就是CQL→SAC[2],但是這種目標函數的切換會導致性能波動,即圖1(a)中的橙線。而引入集成Q網絡后,CQL-N→SAC-N算法可以在確保穩定性的同時,提升一定的學習效率,即圖1(a)中的黑線。
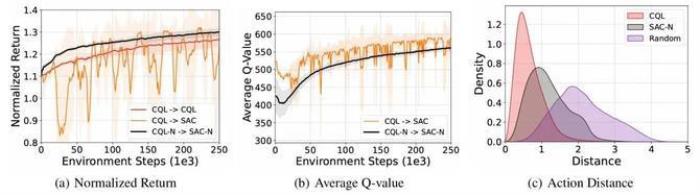
圖1 集成Q網絡在離線到在線強化學習訓練框架中的驗證性實驗
我們還可以通過可視化的方式來分析集成Q網絡的優勢。首先我們將CQL→SAC和CQL-N→SAC-N在在線微調階段的Q值變化過程進行可視化,如圖1(b)所示,CQL→SAC這樣直接切換優化目標的方式確實會導致Q值的高估并且非常不穩定,而引入集成Q網絡之后,由于SAC-N仍然具有保守低估Q值的能力,其相比于SAC算法的Q值也就會偏小并且保持相對穩定的變化。
值得注意的是,CQL-N→SAC-N不僅能夠相比于CQL→SAC提升穩定性,實現穩定的離線到在線強化學習訓練,而且相比于CQL→CQL還能提升一定的學習效率。針對這一現象,我們通過分析SAC-N和CQL在在線微調階段的動作選擇區間來進行解釋說明。具體來說,我們比較了SAC-N、CQL和隨機策略在在線微調過程中采取的動作相比于離線數據集內動作的距離。結果如圖1(c)所示,SAC-N能夠比CQL選擇更廣范圍的動作,這意味著CQL-N→SAC-N能夠在在線微調過程中進行更充分的探索,也就有著更高的學習效率。
03 方法
ENOTO框架可以細化為三步漸進式的優化,仍然在經典的強化學習環境MuJoCo上進行實驗,但這里展示的是在所有任務和數據集上的綜合結果,如圖2所示。

圖2 ENOTO的三步漸進式優化
第一步,在已有離線強化學習算法的基礎上,我們使用集成Q網絡連接離線訓練階段和在線微調階段,將離線階段算法和在線階段算法中使用的Q網絡拓展為N個,然后選擇所有Q網絡中的最小值作為最終的目標Q值進行更新。這一步的主要目的是利用集成Q網絡提升過渡階段的穩定性,當然也提升了一定的學習效率。
第二步,在確保穩定性的基礎上,我們考慮提升在線優化效率。第一步的目標Q值計算方法使用的MinQ,也就是N個Q網絡選最小值作為目標Q值,但是這種方法對于在線強化學習來說還是太過保守,因此我們又研究了另外幾種目標值計算方法,經過實驗比較最終選擇WeightedMinPair作為ENOTO的目標Q值計算方式。
第三步,我們還可以利用集成Q網絡的不確定性來鼓勵在線階段的探索,進一步提升學習效率。具體來說,我們使用集成Q網絡的標準差來衡量不確定性,在選擇動作時不僅會考慮Q值的大小,還會考慮不確定性的大小,通過超參數調整權重來選擇出最終的動作。因為見得少的動作的Q值估計不準,不確定性也會更大,這就是ENOTO中基于不確定性的在線探索方法。

圖3 ENOTO框架
如圖3所示,ENOTO框架和經典離線到在線強化學習訓練范式的框架相同,也分為離線訓練和在線微調兩個階段。首先在離線訓練階段,以離線強化學習算法為基礎,通過引入集成Q網絡,利用已有的離線數據集訓練得到1個策略網絡和N個Q網絡;然后在線階段遷移離線階段的策略網絡和Q網絡作為在線微調的起始狀態,在確保穩定性的同時,仍然基于集成Q網絡進行設計,通過使用新的目標Q值計算方法和基于不確定性的在線探索方法來提升在線微調階段的學習效率。整個ENOTO框架以集成Q網絡貫穿始終,通過多種訓練機制的設計實現了穩定高效的離線到在線強化學習訓練。
04 實驗
我們首先選擇強化學習領域廣泛使用的MuJoCo(Multi-Jointdynamics with Contact)[3]作為驗證算法的實驗環境,在其中的三種運動控制任務HalfCheetah、Walker2d、Hopper進行實驗驗證。作為離線到在線強化學習訓練范式的第一階段,離線訓練需要有離線數據,我們使用離線強化學習領域廣泛使用的D4RL(DatasetsforDeepData-Driven Reinforcement Learning)[4]數據集用于離線訓練,并且為了證明方法的泛用性,我們選擇了不同質量的離線數據集進行實驗驗證,包括medium、medium-replay、medium-expert 這三類離線數據集。對于baseline,我們選擇了離線到在線強化學習研究領域中的經典算法、性能優異算法以及一些在線強化學習算法進行比較。

圖4 MuJoCo實驗結果
圖4展示了ENOTO-CQL方法(ENOTO在CQL上的實例化)和基線方法在在線微調階段的性能表現。與在線強化學習方法如SAC和Scratch相比,ENOTO-CQL從一開始就擁有一個表現良好的策略,并且學習速度快且穩定,證明了離線預訓練的優勢。對于離線強化學習方法,IQL[5]在在線微調階段的改進有限,因為完全悲觀的訓練不再適合在線微調,而ENOTO-CQL則表現出快速的微調能力。在其他離線到在線強化學習方法中,AWAC[6]的性能受到數據集質量的限制,因為其策略的訓練是為了模仿具有高優勢估計的動作,導致在線階段的改進緩慢。盡管BR[7]在某些數據集上可以獲得僅次于ENOTO-CQL的性能,但其訓練過程也不穩定。PEX[8]在在線微調初期階段的性能在各種數據集上顯著下降,這歸因于新訓練策略在早期階段的隨機性,影響了訓練的穩定性。關于Cal-QL[9]算法,盡管其在復雜任務如Antmaze、Adroit和Kitchen中的有效性顯著,但在傳統的MuJoCo任務中表現較為平淡。在線階段的提升相對有限。然而,其最顯著的特點在于其出色的穩定性,有效避免了性能下降的問題。值得注意的是,Hopper-medium-expert-v2數據集是一個特殊案例,大多數離線到在線RL方法在該數據集上表現出不同程度的性能下降,而Cal-QL則保持了其離線階段的性能并且非常穩定。
然后,我們在難度更高的導航任務AntMaze上進行實驗驗證。具體來說,我們使用AntMaze任務中三種不同難度的迷宮進行實驗,包括umaze、medium、large,三種迷宮從易到難,能夠從不同層面檢驗算法的各項指標。而作為用于離線訓練的離線數據集,我們同樣使用D4RL數據集。在D4RL數據集中收集了兩類的AntMaze數據:play和diverse。因此,我們在AntMaze任務的large-diverse、large-play、medium-diverse、medium-play、umaze-diverse 和umaze這6個數據集上進行實驗驗證。同時,為了驗證ENOTO對于多種基線算法的適配性,我們在這里使用ENOTO-LAPO(ENOTO在LAPO[10]上的實例化)進行實驗。由于Antmaze是一個更具挑戰性的任務,大多數離線強化學習方法在離線階段難以取得令人滿意的結果,因此我們僅將我們的ENOTO-LAPO方法與三個有效的基線方法(IQL、PEX和Cal-QL)在此任務上進行比較。

圖5 AntMaze實驗結果
圖5展示了ENOTO-LAPO和基線方法在在線微調階段的性能表現。首先,LAPO在離線階段表現優于IQL,為在線階段提供了更高的起點,特別是在umaze和medium maze環境中,它幾乎達到了性能上限。而在線微調階段由于離線策略的約束,IQL表現出較慢的漸近性能。基于IQL,PEX通過引入從頭訓練的新策略增強了探索程度,但這些策略在早期在線階段的強隨機性導致了性能下降。需要注意的是,盡管IQL和PEX具有相同的起點,PEX在大多數任務中表現出更嚴重的性能下降。關于Cal-QL算法,類似于原始論文中描述的結果,它在Antmaze環境中表現出強勁的性能,顯著優于其在MuJoCo環境中的表現。值得注意的是,與基線方法IQL和PEX相比,Cal-QL展示了更好的穩定性和學習效率。對于我們提出的ENOTO框架,我們證明了ENOTO-LAPO不僅可以提升離線性能,還能在保持離線性能不下降的情況下,實現穩定且快速的性能提升。
05 總結
本項工作在離線到在線強化學習中引入了集成Q網絡作為訓練機制,通過構建多個Q值估計網絡來捕捉不同數據分布偏移情況下的多樣性,提出了ENOTO訓練框架。在離線訓練階段,ENOTO讓集成Q網絡從離線數據中學習多個Q值估計,以適應不同數據分布偏移情況,然后在在線微調階段整合多個Q值估計,生成穩健的在線策略。在確保穩定性的基礎上,我們重新設計了目標Q值計算方法,以在保持穩定性的同時提升學習效率。此外,我們利用Q值的不確定性信息,鼓勵智能體探索不確定性較高的動作,從而更快地發現高性能策略。實驗結果表明,ENOTO在強化學習經典環境MuJoCo和AntMaze上不僅可以提升離線性能,還能在保持離線性能不下降的情況下,實現穩定且快速的性能提升。這種方法使得離線智能體能夠快速適應現實環境,提供高效且有效的在線微調。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
