

 新火種
2024-12-25
新火種
2024-12-25 


超三萬種材料,近百萬真實材料合成表征信息,LLM精準構建材料知識圖譜MKG,登NeurIPS2024

編輯 |ScienceAI
知識圖譜集成多源數據信息為結構化知識,以闡明復雜科學領域的數據結構并介導研究進展、創新和應用的結構化知識交流。
為了統籌和分析分散在數以百萬計的文獻中的材料學知識,新南威爾士大學(UNSW)、同濟大學、香港城市大學以及 GreenDynamics 律動造物,構建了材料知識圖譜(MKG)。
該團隊依托于大型語言模型獨立設計的本體論,并自動化地提取及清洗了大量的材料學文獻中的知識,構建出了豐富的知識圖譜。
利用基于網絡的圖算法,MKG 對圖中的材料、應用和描述進行評分和預測,探索潛在的缺失關系。該圖包含超過十余種材料科學重要屬性,十五萬個節點和近百萬個關系。
具體來說,該團隊通過少量數據對大語言模型進行了微調,自主設計圖的本體,并從數十萬篇文章摘要中提取了材料學相關信息,并保留了所有信息的可追溯性。
結合自然語言處理技術,對知識進行了高質量清洗,并應用圖算法和模型完成了圖的完善和增強,揭示了材料學知識之間的潛在聯系和機理。
通過MKG,團隊預測了在電池、太陽能電池、催化劑等能源領域,未來幾年可能出現的潛在材料,并為這些預測提供了強有力的解釋性支持。
該研究以「Construction and Application of Materials Knowledge Graph in Multidisciplinary Materials Science via Large Language Model」為題,被機器學習頂級會議 NeurIPS 2024 接收。

論文鏈接:https://neurips.cc/virtual/2024/poster/95920
研究背景
材料科學的研究對現代工業的發展至關重要,尤其是在能源轉換、電子設備創新、汽車制造和生物醫藥應用等領域。
傳統上,材料研究依賴于實驗室實驗和長時間的經驗積累,這不僅耗時而且成本高昂。此外,盡管有無數的科研文獻提供豐富的理論和實驗數據,但這些知識常常散落在不同的出版物和數據庫中,難以迅速準確地獲取和應用。
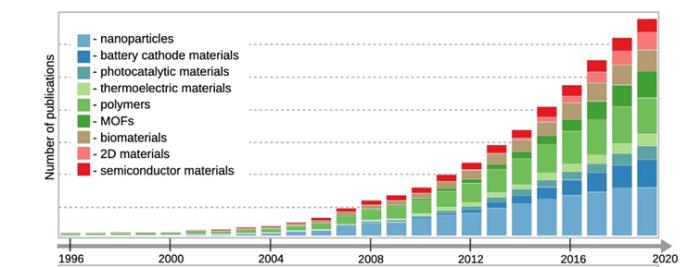
圖 1:爆發式增長的材料學文獻。(來源:網絡)
在這種背景下,自動化的知識集成和加速研究的需求日益迫切。借助人工智能技術,研究人員開始探索如何利用這些先進工具來改善材料科學的研究方法。
知識圖譜作為一種信息組織形式,能夠將散落在各處的非結構化數據轉換為結構化的知識庫,從而提供一個全面、互聯的數據網絡,加快知識的檢索和應用。
盡管知識圖譜的潛力巨大,但其構建過程面臨多重挑戰。
首先,材料科學領域的復雜性要求圖譜不僅要精確地反映出材料的化學和物理性質,還需要捕捉到這些性質在不同應用中的表現。
此外,材料學的快速發展也意味著知識圖譜需要持續更新和擴展,這不僅依賴于領域專家的深入參與,還需要借助自動化工具以適應知識的動態變化
MKG - 材料科學知識圖譜
為了解決這些問題,團隊將大型語言模型引入知識圖譜的構建流程,不僅可以通過自動化構建本體論,提取和分析巨量文獻中的數據來構建初步的知識圖譜,還可以通過持續學習來適應新的研究成果和理論發展,從而保持知識圖譜的前沿性和準確性。
通過這些技術的應用,MKG 的構建和維護成為可能,極大地促進了材料科學研究的深度和廣度,為科研人員提供了一個強大的工具,幫助他們更快地發現和應用新材料,推動科技創新和工業應用。
對于 MKG 的構建和應用,整個過程可以分為四個關鍵步驟:(1)本體論的自動構建,(2)知識的抽取,(3)知識清洗,(4)材料發現。
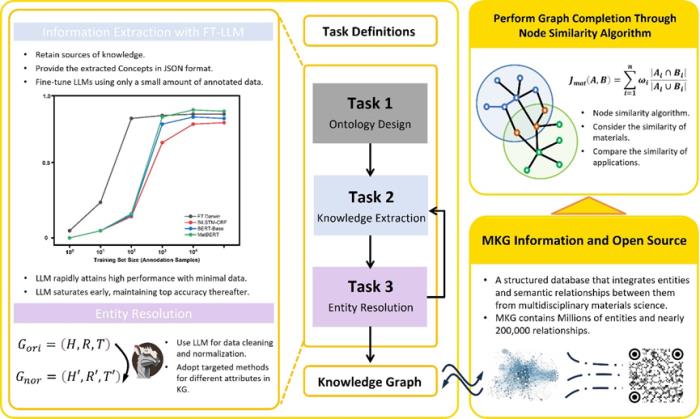
圖 2:MKG 概覽。(來源:論文)
(1)構建知識圖譜的首要步驟是創建一個本體論,它定義了將被包含在圖譜中的各種概念及其相互關系。在材料科學領域,這涉及到從基本的化學成分到復雜的物理性質和應用過程的全面覆蓋。
借助大型語言模型,如 LLaMA 或Darwin,研究團隊能夠自動識別和分類大量文獻中的關鍵概念和關系,從而自動化構建本體論。這一過程減少了人工干預的需要,加速了知識結構的創建,并確保了結構的一致性和可擴展性。
(2)從分散在各處的科研文獻中抽取具體的數據和信息。這包括但不限于材料的合成方法、物理和化學屬性、以及它們在實際應用中的表現。
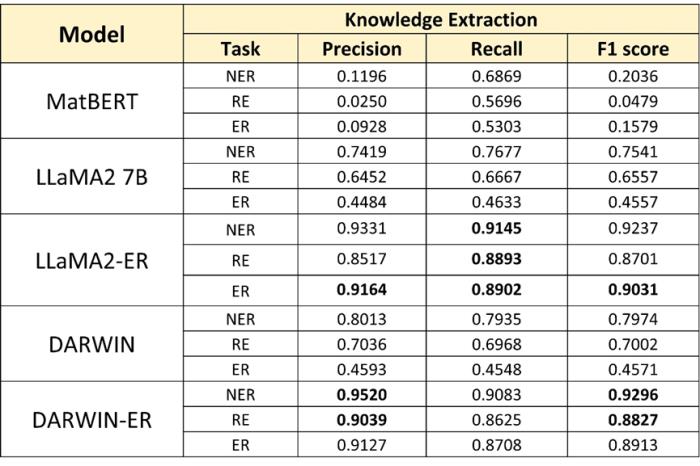
通過少量數據微調的大型語言模型能夠精確地從文本中提取出這些信息,轉化為結構化數據,并保留信息的出處。這一步是知識圖譜構建中至關重要的,因為它直接影響到圖譜的質量和后續應用的效果。
表 1:LLM 在知識抽取中 的效果。(來源:論文)
(3)抽取出的信息往往包含噪聲或不一致性,因此需要進行徹底的清洗和驗證。這一步驟確保了知識圖譜中的數據是準確和可靠的。
清洗過程中,可能會用到各種數據清洗技術,如數據去重、格式標準化、錯誤更正等。此外,還需要專家進行人工審核,以解決自動化工具難以處理的復雜問題。
(4)最后一步是利用抽取和清洗后的數據來完善和增強知識圖譜(圖完成)。用圖算法和神經網絡來分析和預測材料之間的新關系,這包括增加新的實體和關系,更新圖中的信息。
這不僅增強了圖譜的功能,也為研究人員提供了更深入的洞見,幫助他們發現新的材料特性和應用潛力。
材料發現
通過圖完成的步驟,該方法可以全局范圍內識別能源材料與應用之間的潛在聯系。在局部使用圖神經網絡,聚合特定的量化屬性到特定材料的特征實體,用于嵌入訓練圖神經網絡,并預測材料未知特征的數值。
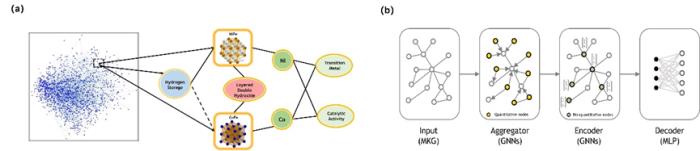
圖 3:基于(a)圖算法和(b)圖神經網絡的圖完成。(來源:論文)
全局范圍內的材料發現是通過基于修正后 Jaccard 相似度算法。修正后的算法不考慮不同屬性的鄰居實體具備不同的權重,還納入了實體的出現時間和重要程度,更仔細的考慮不同實體的優先級。
為了驗證算法的有效性,研究人員將 MKG 按照時間屬性分為兩個子圖,分別作為訓練集和驗證集。
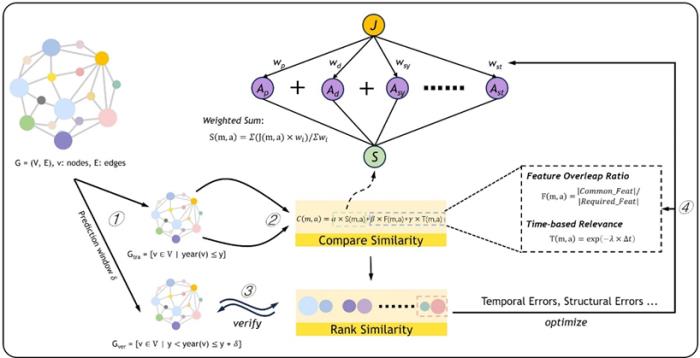
圖 4:全局范圍的材料發現。(來源:論文)
不難發現,隨著時間的增長,訓練集上的預測材料逐漸在驗證集中被發現。這不但證明了算法的有效性,也驗證了 MKG 的可信度。此外,團隊還統計了高排名的預測被驗證的概率。更多信息可以瀏覽全文進行了解。
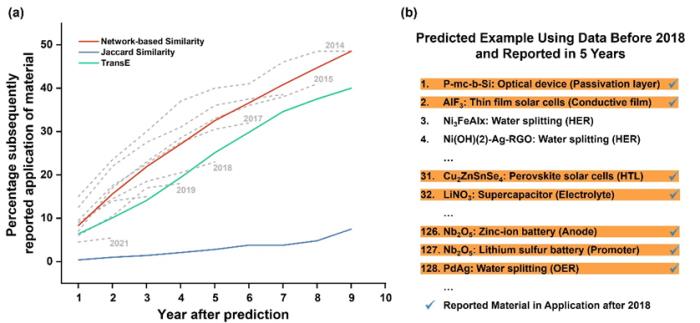
圖 5:材料發現的驗證結果。(來源:論文)
未來的研究方向
考慮到 MKG 在構建和應用過程中展現出的潛力,研究人員提出了幾個可能的發展方向,旨在進一步拓寬材料知識圖譜的應用領域并增強其實用性。
1、擴展 MKG 的覆蓋范圍至更多化學和材料科學的子領域,并且與其他現有的知識圖譜進行整合。
2、通過將作者身份、發表年份和機構歸屬等屬性納入知識圖譜,研究人員將分析材料再利用的歷史「社交」模式。
3、分析 MKG 中的簇形成,這些簇基于材料之間的鏈接。理解這些簇將幫助揭示材料是如何相互連接的,這可以幫助發現不同材料之間在孤立研究中未顯現的聯系。
4、團隊正將 AI Agent 技術集成入本體論的自動構建中,以增強知識管理與發現。本體論分為主本體和子本體:主本體覆蓋廣泛概念,子本體則針對特定子領域細化分類。這提高了構建的精確性,增強了適應性。
這些研究方向不僅能夠擴展 MKG 的功能和應用范圍,也有助于推動科學與人工智能技術的深度融合,開拓新的科研和工業應用前景。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
