

 新火種
2024-12-05
新火種
2024-12-05 


阿里多模態檢索智能體,自帶o1式思考過程!復雜問題逐步拆解
多模態檢索增強生成(mRAG)也有o1思考推理那味兒了!
阿里通義實驗室新研究推出自適應規劃的多模態檢索智能體。
名叫OmniSearch,它能模擬人類解決問題的思維方式,將復雜問題逐步拆解進行智能檢索規劃。
直接看效果:
隨便上傳一張圖,詢問任何問題,OmniSearch都會進行一段“思考過程”,不僅會將復雜問題拆解檢索,而且會根據當前檢索結果和問題情境動態調整下一步檢索策略。
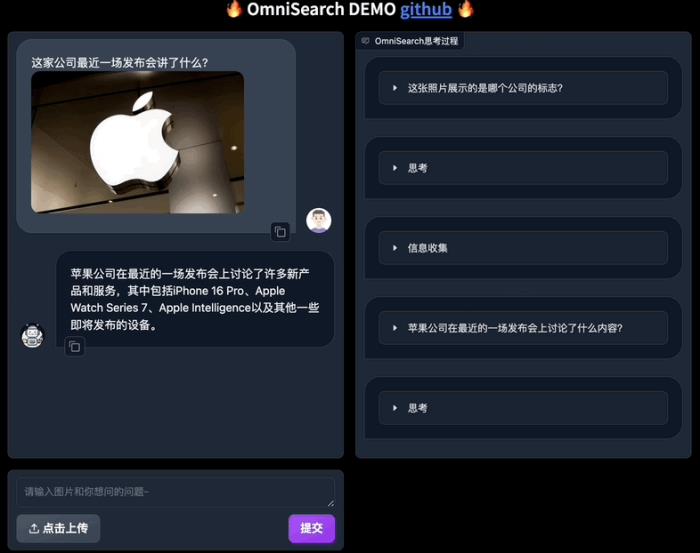
相比傳統mRAG受制于其靜態的檢索策略,這種設計不僅提高了檢索效率,也顯著增強了模型生成內容的準確性。
為評估OmniSearch,研究團隊構建了全新Dyn-VQA數據集。
在一系列基準數據集上的實驗中,OmniSearch展現了顯著的性能優勢。特別是在處理需要多步推理、多模態知識和快速變化答案的問題時,OmniSearch相較于現有的mRAG方法表現更為優異。
目前OmniSearch在魔搭社區還有demo可玩。
動態檢索規劃框架,打破傳統mRAG局限傳統mRAG方法遵循固定的檢索流程,典型的步驟如下:
輸入轉化:接收多模態輸入(例如圖像+文本問題),將圖像轉化為描述性文本(例如通過image caption模型)。單一模態檢索:將問題或描述性文本作為檢索查詢,向知識庫發送單一模態檢索請求(通常是文本檢索)。固定生成流程:將檢索到的信息與原始問題結合,交由MLLM生成答案。OmniSearch旨在解決傳統mRAG方法的以下痛點:
靜態檢索策略的局限:傳統方法采用固定的兩步檢索流程,無法根據問題和檢索內容動態調整檢索路徑,導致信息獲取效率低下。檢索查詢過載:單一檢索查詢往往包含了多個查詢意圖,反而會引入大量無關信息,干擾模型的推理過程。為克服上述局限,OmniSearch引入了一種動態檢索規劃框架。

OmniSearch的核心架構包括:
規劃智能體(Planning Agent):負責對原始問題進行逐步拆解,根據每個檢索步驟的反饋決定下一步的子問題及檢索策略。檢索器(Retriever):執行實際的檢索任務,支持圖像檢索、文本檢索以及跨模態檢索。子問題求解器(Sub-question Solver):對檢索到的信息進行總結和解答,具備高度的可擴展性,可以與不同大小的多模態大語言模型集成。迭代推理與檢索(Iterative Reasoning and Retrieval):通過遞歸式的檢索與推理流程,逐步接近問題的最終答案。多模態特征的交互:有效處理文本、圖像等多模態信息,靈活調整檢索策略。反饋循環機制(Feedback Loop):在每一步檢索和推理后,反思當前的檢索結果并決定下一步行動,以提高檢索的精確度和有效性。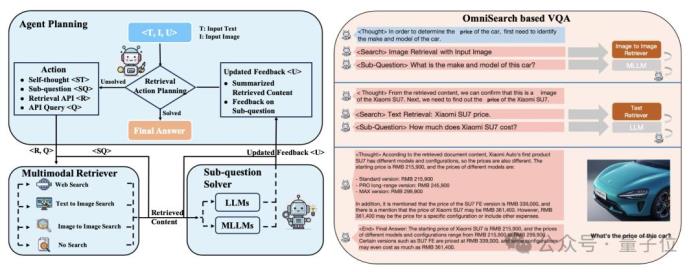 構建新數據集進行實驗評估
構建新數據集進行實驗評估為了更好地評估OmniSearch和其它mRAG方法的性能,研究團隊構建了全新的Dyn-VQA數據集。Dyn-VQA包含1452個動態問題,涵蓋了以下三種類型:
答案快速變化的問題:這類問題的背景知識不斷更新,需要模型具備動態的再檢索能力。例如,詢問某位明星的最新電影票房,答案會隨著時間的推移而發生變化。多模態知識需求的問題:問題需要同時從多模態信息(如圖像、文本等)中獲取知識。例如,識別一張圖片中的球員,并回答他的球隊圖標是什么。多跳問題:問題需要多個推理步驟,要求模型在檢索后進行多步推理。這些類型的問題相比傳統的VQA數據集需要更復雜的檢索流程,更考驗多模態檢索方法對復雜檢索的規劃能力。
 在Dyn-VQA數據集上的表現答案更新頻率:對于答案快速變化的問題,OmniSearch的表現顯著優于GPT-4V結合啟發式mRAG方法,準確率提升了近88%。多模態知識需求:OmniSearch能夠有效地結合圖像和文本進行檢索,其在需要額外視覺知識的復雜問題上的表現遠超現有模型,準確率提高了35%以上。多跳推理問題:OmniSearch通過多次檢索和動態規劃,能夠精確解決需要多步推理的問題,實驗結果表明其在這類問題上的表現優于當前最先進的多模態模型,準確率提升了約35%。
在Dyn-VQA數據集上的表現答案更新頻率:對于答案快速變化的問題,OmniSearch的表現顯著優于GPT-4V結合啟發式mRAG方法,準確率提升了近88%。多模態知識需求:OmniSearch能夠有效地結合圖像和文本進行檢索,其在需要額外視覺知識的復雜問題上的表現遠超現有模型,準確率提高了35%以上。多跳推理問題:OmniSearch通過多次檢索和動態規劃,能夠精確解決需要多步推理的問題,實驗結果表明其在這類問題上的表現優于當前最先進的多模態模型,準確率提升了約35%。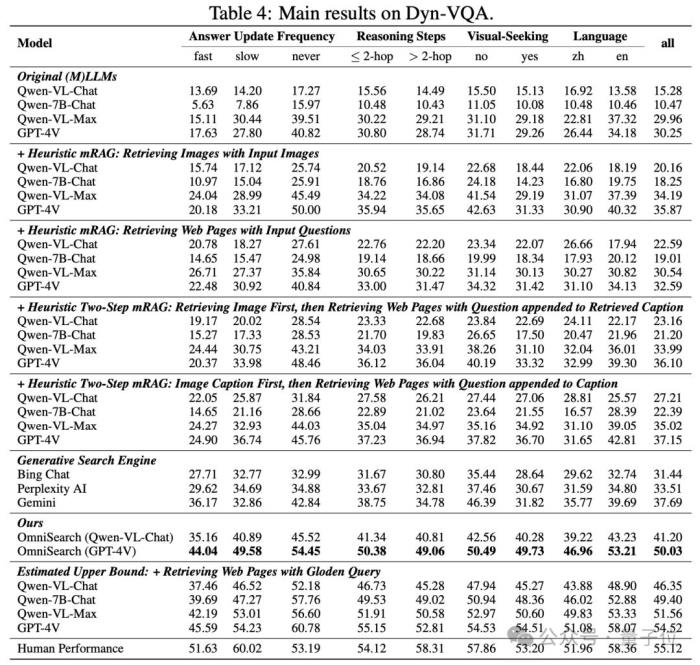 在其它數據集上的表現
在其它數據集上的表現接近人類級別表現:
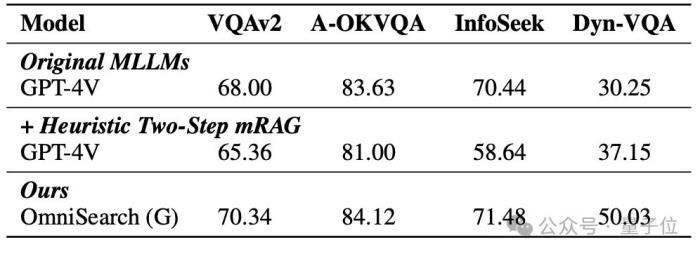
OmniSearch在大多數VQA任務上達到了接近人類水平的表現。例如,在VQAv2和A-OKVQA數據集中,OmniSearch的準確率分別達到了70.34和84.12,顯著超越了傳統mRAG方法。
復雜問題處理能力:
在更具挑戰性的Dyn-VQA數據集上,OmniSearch通過多步檢索策略顯著提升了模型的表現,達到了50.03的F1-Recall評分,相比基于GPT-4V的傳統兩步檢索方法提升了近14分。
 模塊化能力與可擴展性
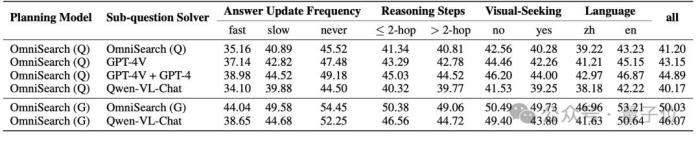
模塊化能力與可擴展性OmniSearch可以靈活集成不同規模和類型的多模態大語言模型(MLLM)作為子問題求解器。
無論是開源模型(如Qwen-VL-Chat)還是閉源模型(如GPT-4V),OmniSearch都能通過動態規劃與這些模型協作完成復雜問題的解決。
它的模塊化設計允許根據任務需求選擇最合適的模型,甚至在不同階段調用不同大小的MLLM,以在性能和計算成本之間實現靈活平衡。
下面是OmniSearch和不同模型配合的實驗結果:
Paper:
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
