推理模型其實無需「思考」?伯克利發現有時跳過思考過程會更快、更準確
當 DeepSeek-R1、OpenAI o1 這樣的大型推理模型還在通過增加推理時的計算量提升性能時,加州大學伯克利分校與艾倫人工智能研究所突然扔出了一顆深水炸彈:別再卷 token 了,無需顯式思維鏈,推理模型也能實現高效且準確的推理。
當 DeepSeek-R1、OpenAI o1 這樣的大型推理模型還在通過增加推理時的計算量提升性能時,加州大學伯克利分校與艾倫人工智能研究所突然扔出了一顆深水炸彈:別再卷 token 了,無需顯式思維鏈,推理模型也能實現高效且準確的推理。
其實……不用大段大段思考,推理模型也能有效推理!是不是有點反常識?因為大家的一貫印象里,推理模型之所以能力強大、能給出準確的有效答案,靠的就是長篇累牘的推理過程。這個過程往往用時很長,等同于需要消耗大量算力。

在零一萬物初次開源過程中,我們發現用和開源社區普遍使用的LLaMA 架構會對開發者更為友好,對于沿用LLaMA部分推理代碼經實驗更名后的疏忽,原始出發點是為了充分測試模型,并非刻意隱瞞來源。零一萬物對

金融界2023年11月24日消息,據國家知識產權局公告,榮耀終端有限公司申請一項名為“一種語音識別方法、電子設備以及介質“,公開號CN117116264A,申請日期為2023年2月。專利摘要顯示,本申請實施例提供一種語音識別方法、電子設備以及介質,可應用于語音識別的技術領域,

圖上的線條代表大腦皮層中與語言處理相關的各個區域之間的連接。當閱讀時,這些區域的神經元會以精確同步的方式激發,這種現象被稱為共同漣漪。圖片來源:加州大學圣迭戈分校大腦各區域是如何交流、整合信息,最終形
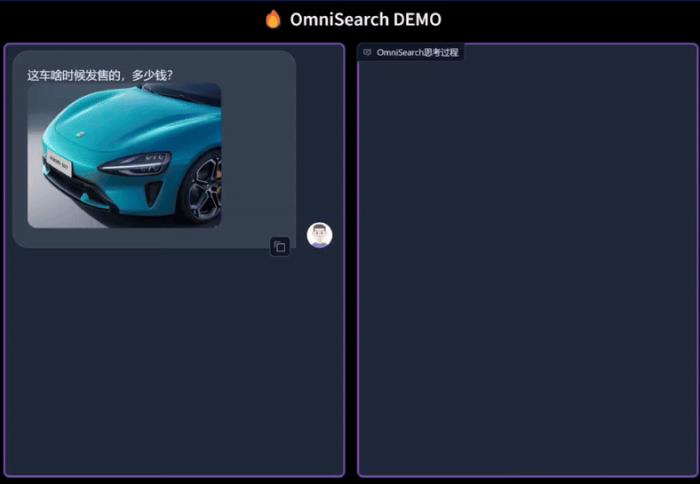
多模態檢索增強生成(mRAG)也有o1思考推理那味兒了!阿里通義實驗室新研究推出自適應規劃的多模態檢索智能體。名叫OmniSearch,它能模擬人類解決問題的思維方式,將復雜問題逐步拆解進行智能檢索規劃。直接看效果:隨便上傳一張圖,詢問任何問題,OmniSearch都會進行一段“思考過程”,不僅會將