

 新火種
2024-11-16
新火種
2024-11-16 


聚焦「視聽觸感官」協同配合的具身精細操縱,人大胡迪團隊領銜探索機器人模態時變性挑戰
本文作者來自于中國人民大學,深圳朝聞道科技有限公司以及中國電信人工智能研究院。其中第一作者馮若軒為中國人民大學二年級碩士生,主要研究方向為多模態具身智能,師從胡迪教授。
引言:在機器人操縱物體的過程中,不同傳感器數據攜帶的噪聲會對預測控制造成怎樣的影響?中國人民大學高瓴人工智能學院 GeWu 實驗室、朝聞道機器人和 TeleAI 最近的合作研究揭示并指出了 “模態時變性”(Modality Temporality)現象,通過捕捉并刻畫各個模態質量隨物體操縱過程的變化,提升不同信息在具身多模態交互的感知質量,可顯著改善精細物體操縱的表現。論文已被 CoRL2024 接收并選為 Oral Presentation。
人類在與環境互動時展現出了令人驚嘆的感官協調能力。以一位廚師為例,他不僅能夠憑借直覺掌握食材添加的最佳時機,還能通過觀察食物的顏色變化、傾聽烹飪過程中的聲音以及嗅聞食物的香氣來精準調控火候,從而無縫地完成烹飪過程中的每一個復雜階段。這種能力,即在執行復雜且長時間的操作任務時,靈活運用不同的感官,是建立在對任務各個階段全面而深刻理解的基礎之上的。然而,對于機器人而言,如何協調這些感官模態以更高效地完成指定的操作任務,以及如何充分利用多模態感知能力來實現可泛化的任務執行,仍是當前尚未解決的問題。我們不僅需要使模型理解任務階段本身,還需要從任務階段的新角度重新審視多傳感器融合。在一個復雜的操縱任務中完成將任務劃分為不同階段的一系列子目標的過程中,各個模態的數據質量很可能隨任務階段而不斷變化。因此,階段轉換很可能導致模態重要性的變化。除此之外,每個階段內部也可能存在相對較小的模態質量變化。我們將這種現象總結為多傳感器模仿學習的一大挑戰:模態時變性(Modality Temporality)。然而,過去的方法很少關注這一點,忽視了階段理解在多傳感器融合中的重要性。本文借鑒人類的基于階段理解的多感官感知過程,提出了一個由階段引導的動態多傳感器融合框架 MS-Bot,旨在基于由粗到細粒度的任務階段理解動態地關注具有更高質量的模態數據,從而更好地應對模態時變性的挑戰,完成需要多種傳感器的精細操縱任務。
論文鏈接:https://arxiv.org/abs/2408.01366v2項目主頁:https://gewu-lab.github.io/MS-Bot/模態時變性在復雜的操作任務中,各傳感器數據的質量可能會隨著階段的變化而變化。在不同的任務階段中,一個特定模態的數據可能對動作的預測具有重大貢獻,也可能作為主要模態的補充,甚至可能幾乎不提供任何有用的信息。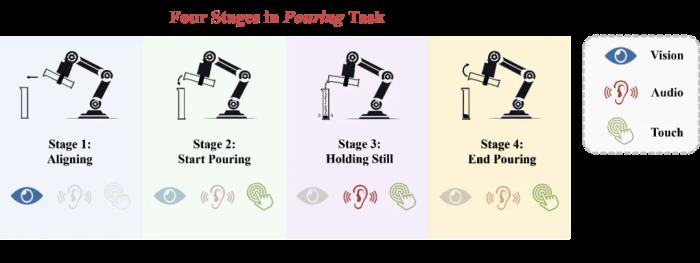
圖 1 傾倒任務的模態時變性以上圖中的傾倒任務為例,在初始的對齊階段中,視覺模態對動作的預測起決定性作用。進入開始傾倒階段后,模型需要開始利用音頻和觸覺的反饋來確定合適的傾倒角度(倒出速度)。在保持靜止階段,模型主要依賴音頻和觸覺信息來判斷已經倒出的小鋼珠質量是否已經接近目標值,而視覺幾乎不提供有用的信息。最后,在結束傾倒階段,模型需要利用觸覺模態的信息判斷傾倒任務是否已經完成,與開始傾倒階段進行區分。除階段間的模態質量變化,各個階段內部也可能存在較小的質量變化,例如音頻模態在開始傾倒和結束傾倒的前期和后期具有不同的重要性。我們將這兩種變化區分為粗粒度和細粒度的模態質量變化,并將這種現象總結為多傳感器模仿學習中的一個重要挑戰:模態時變性。方法:階段引導的動態多傳感器融合為了應對模態時變性的挑戰,我們認為在機器人操縱任務中,多傳感器數據的融合應該建立在充分的任務階段理解之上。因此,我們提出了 MS-Bot 框架,這是一個由階段引導的動態多傳感器融合方法,旨在基于顯式的由粗到細的任務階段理解動態地關注具有更高質量的模態數據。為了將顯式的階段理解整合到模仿學習過程中,我們首先為每個數據集中的樣本添加了一個階段標簽,并將動作標簽和階段標簽共同作為監督信號訓練包含四個模塊的 MS-Bot 框架(如圖 2 所示):特征提取模塊:該模塊包含一系列單模態編碼器,每個編碼器都接受一段簡短的單模態觀測歷史作為輸入,并將它們編碼為特征。狀態編碼器:該模塊旨在將各模態特征和動作歷史序列編碼為表示當前任務狀態的 token。動作歷史與人類記憶相似,可以幫助指示當前所處的任務狀態。我們將動作歷史輸入到一個 LSTM 中,并通過一個 MLP 將它們與模態特征編碼為狀態 token。階段理解模塊:該模塊旨在通過將階段信息注入狀態 token 中,從而實現顯式的由粗到細粒度的任務階段理解。我們用一組可學習的階段 token 來表示每個任務階段,并通過一個門控網絡(MLP)來預測當前所處的階段,利用 Softmax 歸一化后的階段預測分數對階段 token 進行加權融合,得到當前階段 token。門控網絡的訓練以階段標簽作為監督信號,對非當前階段的預測分數進行懲罰。我們還放松了對階段邊界附近的樣本上的相鄰階段分數懲罰,從而實現軟約束效果,得到更平滑的階段預測。新的注入階段信息后的狀態 token 由原狀態 token 和階段 token 加權融合得到,可以表示任務階段內的細粒度狀態,從而對多傳感器動態融合進行引導。動態融合模塊:該模塊根據當前任務階段的細粒度狀態動態地選擇關注的模態特征。我們以注入了階段信息的狀態 token 作為 Query,將模態特征作為 Key 和 Value 進行交叉注意力(Cross Attention)。該方法根據當前任務階段的需求,將各模態的特征動態地整合到一個融合 token 中。最后,該融合 token 輸入到策略網絡(MLP)中預測下一個動作。我們還引入了隨機注意力模糊機制,以一定概率將各單模態特征 token 上的注意力分數替換為相同的平均值,防止模型簡單地記憶與注意力分數模式對應的動作。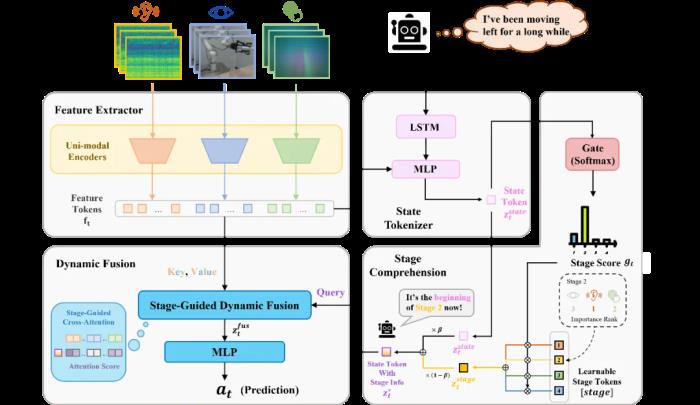
圖 2 由階段引導的動態多傳感器融合框架 MS-Bot實驗結果為了驗證基于由粗到細的任務階段理解的 MS-Bot 的優越性,我們在兩個十分有挑戰性的精細機器人操縱任務:傾倒和帶有鍵槽的樁插入中進行了詳細的對比。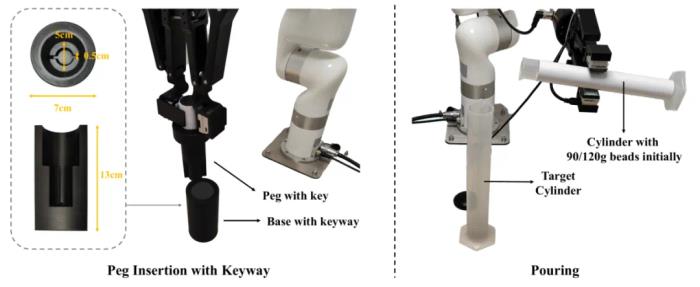
圖 3 傾倒與帶有鍵槽的樁插入任務設置如表 1 所示,MS-Bot 在兩個任務的所有設置上均優于所有基線方法。MS-Bot 在兩個任務中的性能超過了使用自注意力(Self Attention)進行動態融合的 MULSA 基線,這表明 MS-Bot 通過在融合過程中基于對當前階段的細粒度狀態的理解更好地分配模態權重,而沒有顯示階段理解的 MULSA 基線無法充分利用動態融合的優勢。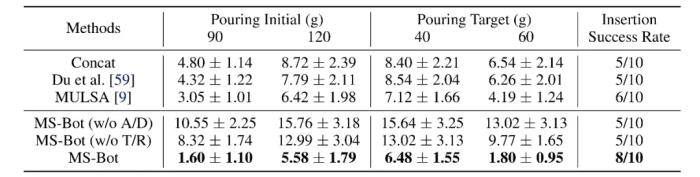
表 1 傾倒和帶有鍵槽的樁插入任務上的性能比較我們還對任務完成中各個模態的注意力分數和各階段的預測分數進行了可視化。在每個時間步,我們分別對每種模態的所有特征 token 的注意力分數進行平均,而階段預測分數是 Softmax 歸一化后的門控網絡輸出。如圖 4 所示,MS-Bot 準確地預測了任務階段的變化,并且得益于模型中由粗到細粒度的任務階段理解,三個模態的注意力分數保持相對穩定,表現出明顯的階段間變化和較小的階段內調整。
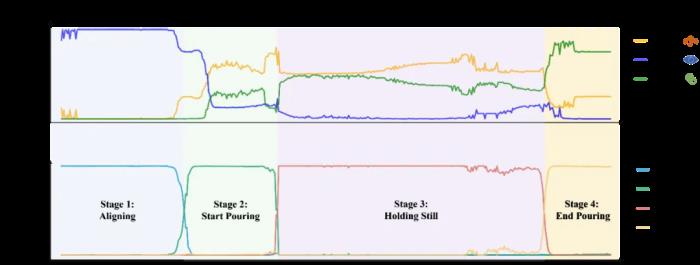
圖 4 各模態注意力分數和階段預測分數可視化為了驗證 MS-Bot 對干擾物的泛化能力,我們在兩個任務中都加入了視覺干擾物。在傾倒任務中,我們將量筒的顏色從白色更改為紅色。對于樁插入任務,我們將底座顏色從黑色更改為綠色(“Color”),并在底座周圍放置雜物(“Mess”)。如表 2 所示,MS-Bot 在各種有干擾物的場景中始終保持性能優勢,這是因為 MS-Bot 根據對當前任務階段的理解動態地分配模態權重,從而減少視覺噪聲對融合特征的影響,而基線方法缺乏理解任務階段并動態調整模態權重的能力。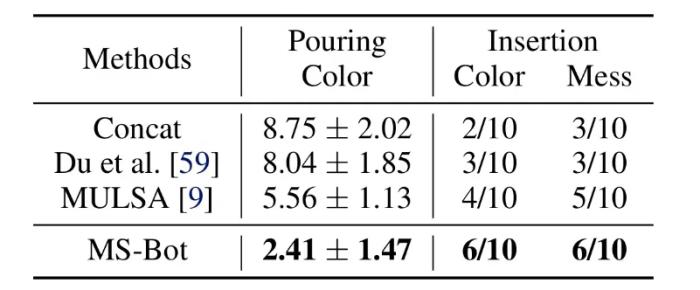
表 2 含視覺干擾物場景中的性能比較總述本文從任務階段的視角重新審視了機器人操縱任務中的多傳感器融合,引入模態時變性的挑戰,并將由子目標劃分的任務階段融入到模仿學習過程中。該研究提出了 MS-Bot,一種由階段引導的多傳感器融合方法,基于由粗到細粒度的階段理解動態地關注質量更高的模態。我們相信由顯式階段理解引導的多傳感器融合會成為一種有效的多傳感器機器人感知范式,并借此希望能夠激勵更多的多傳感器機器人操縱的相關研究。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
