

 新火種
2024-10-06
新火種
2024-10-06 

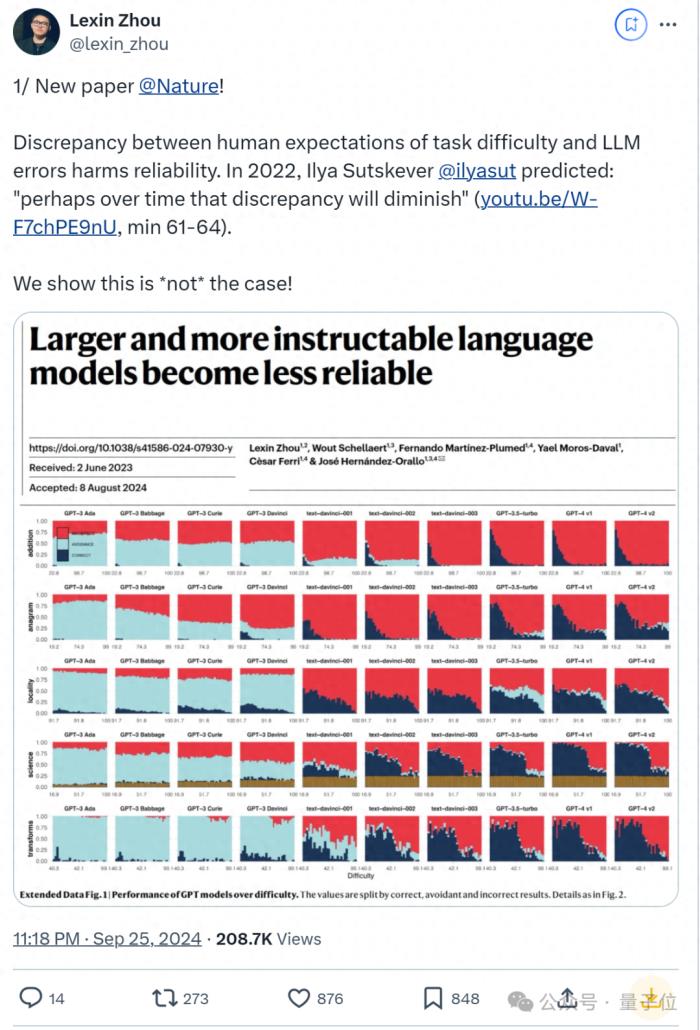
00后國人論文登Nature,大模型對人類可靠性降低
00后國人一作登上Nature,這篇大模型論文引起熱議。
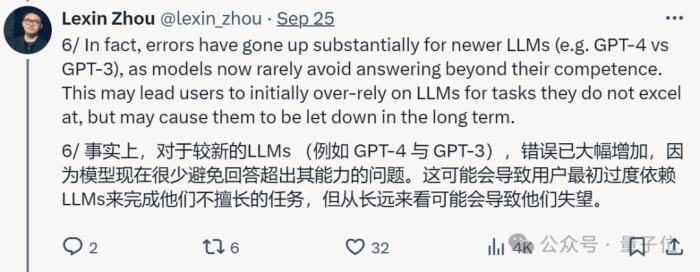
簡單來說,論文發(fā)現(xiàn):更大且更遵循指令的大模型也變得更不可靠了,某些情況下GPT-4在回答可靠性上還不如GPT-3。
結(jié)論一出,立即引來20多萬網(wǎng)友圍觀:
在Reddit論壇也引發(fā)圍觀議論。
這讓人不禁想起,一大堆專家/博士級別的模型還不會“9.9和9.11”哪個大這樣的簡單問題。
關(guān)于這個現(xiàn)象,論文提到這也反映出,模型的表現(xiàn)與人類對難度的預期不符。
換句話說,“LLMs在用戶預料不到的地方既成功又(更危險地)失敗”。
Ilya Sutskever2022年曾預測:
然而這篇論文發(fā)現(xiàn)情況并非如此。不止GPT,LLaMA和BLOOM系列,甚至OpenAI新的o1模型和Claude-3.5-Sonnet也在可靠性方面令人擔憂。
更重要的是,論文還發(fā)現(xiàn)依靠人類監(jiān)督來糾正錯誤的做法也不管用。

有網(wǎng)友認為,雖然較大的模型可能會帶來可靠性問題,但它們也提供了前所未有的功能。

還有人認為,這項研究凸顯了人工智能所面臨的微妙挑戰(zhàn)(平衡模型擴展與可靠性)。
 更大的模型更不可靠,依靠人類反饋也不管用了
更大的模型更不可靠,依靠人類反饋也不管用了為了說明結(jié)論,論文研究了從人類角度影響LLMs可靠性的三個關(guān)鍵方面:
1、難度不一致:LLMs是否在人類預期它們會失敗的地方失敗?2、任務回避:LLMs是否避免回答超出其能力范圍的問題?3、對提示語表述的敏感性:問題表述的有效性是否受到問題難度的影響?
更重要的是,作者也分析了歷史趨勢以及這三個方面如何隨著任務難度而演變。
下面一一展開。
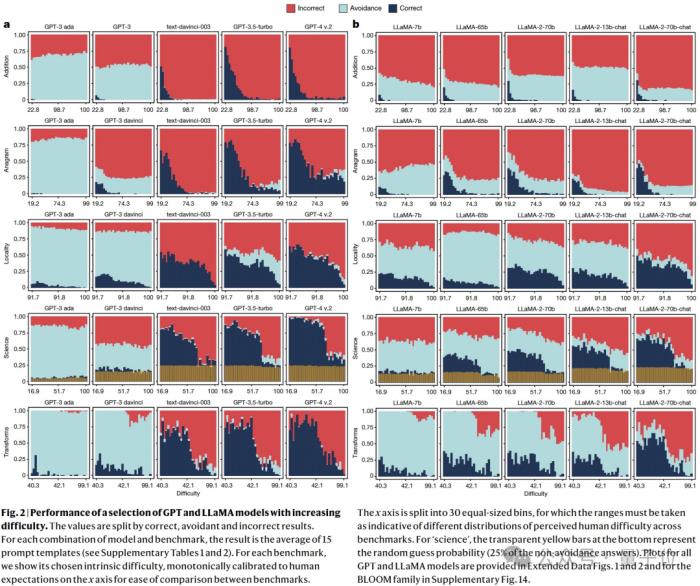
對于第1個問題,論文主要關(guān)注正確性相對于難度的演變。
從GPT和LLaMA的演進來看,隨著難度的增加,所有模型的正確性都會明顯下降。(與人類預期一致)
然而,這些模型仍然無法解決許多非常簡單的任務。
這意味著,人類用戶無法發(fā)現(xiàn)LLMs的安全操作空間,利用其確保模型的部署表現(xiàn)可以完美無瑕。
令人驚訝的是,新的LLMs主要提高了高難度任務上的性能,而對于更簡單任務沒有明顯的改進。比如,GPT-4與前身GPT-3.5-turbo相比。
以上證明了人類難度預期與模型表現(xiàn)存在不一致的現(xiàn)象,并且此不一致性在新的模型上加劇了。

這也意味著:
其次,關(guān)于第2點論文發(fā)現(xiàn)(回避通常指模型偏離問題回答,或者直接挑明“我不知道”):
一般來說,人類面對越難的任務,越有可能含糊其辭。
但LLMs的實際表現(xiàn)卻截然不同,研究顯示,它們的規(guī)避行為與困難度并無明顯關(guān)聯(lián)。
這容易導致用戶最初過度依賴LLMs來完成他們不擅長的任務,但讓他們從長遠來看感到失望。
后果就是,人類還需要驗證模型輸出的準確性,以及發(fā)現(xiàn)錯誤。(想用LLMs偷懶大打折扣)

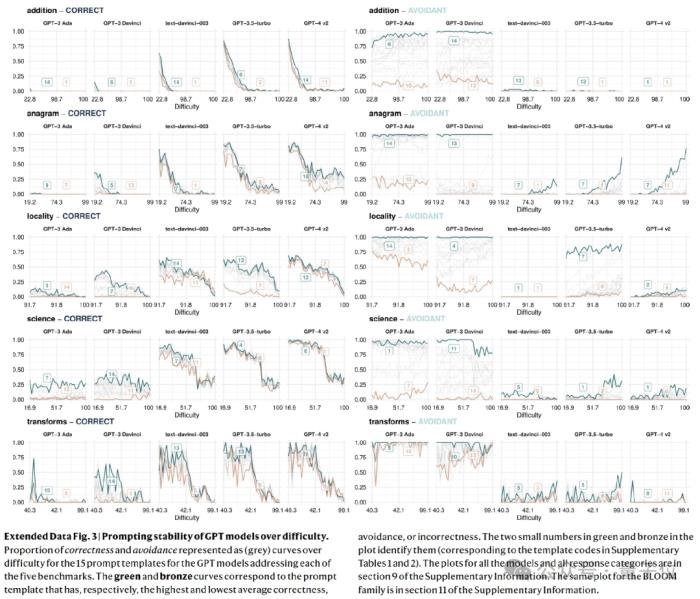
最后論文發(fā)現(xiàn),即使一些可靠性指標有所改善,模型仍然對同一問題的微小表述變化敏感。
舉個栗子,問“你能回答……嗎?”而不是“請回答以下問題……”會導致不同程度的準確性。
分析發(fā)現(xiàn):僅僅依靠現(xiàn)存的scaling-up和shaping-up不太可能完全解決指示敏感度的問題,因為最新模型和它們的前身相比優(yōu)化并不顯著。
而且即使選擇平均表現(xiàn)上最佳的表述格式,其也可能主要對高難度任務有效,但同時對低難度任務無效(錯誤率更高)。
這表明,人類仍然受制于提示工程。
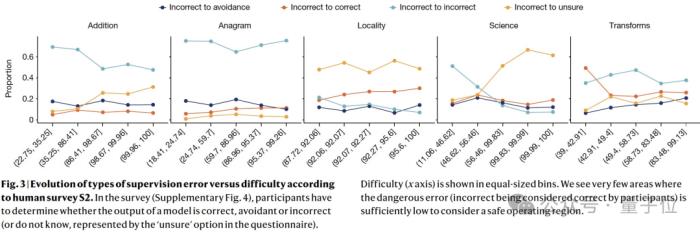
更可怕的是,論文發(fā)現(xiàn),人類監(jiān)督無法緩解模型的不可靠性。
論文根據(jù)人類調(diào)查來分析,人類對難度的感知是否與實際表現(xiàn)一致,以及人類是否能夠準確評估模型的輸出。
結(jié)果顯示,在用戶認為困難的操作區(qū)域中,他們經(jīng)常將錯誤的輸出視為正確;即使對于簡單的任務,也不存在同時具有低模型誤差和低監(jiān)督誤差的安全操作區(qū)域。
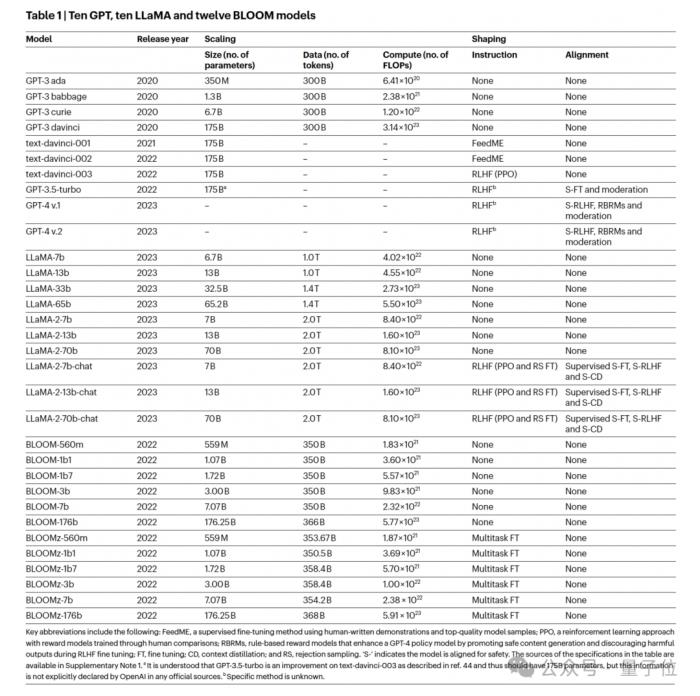
以上不可靠性問題在多個LLMs系列中存在,包括GPT、LLaMA和BLOOM,研究列出來的有32個模型。
這些模型表現(xiàn)出不同的Scaling-up(增加計算、模型大小和數(shù)據(jù))以及shaping-up(例如指令FT、RLHF)。
除了上面這些,作者們后來還發(fā)現(xiàn)一些最新、最強的模型也存在本文提到的不可靠性問題:
并有一篇文檔分別舉出了例子(具體可查閱原文檔):

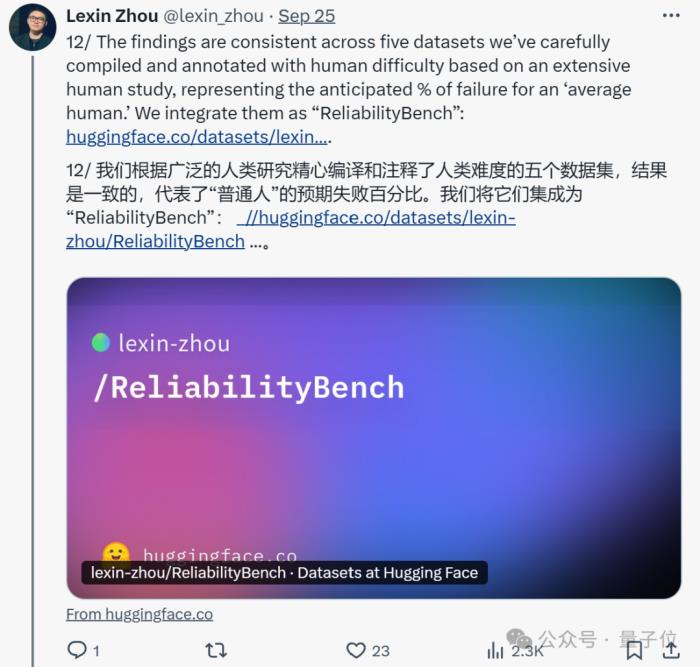
此外,為了驗證其他模型是否存在可靠性問題,作者將論文用到的測試基準ReliabilityBench也開源了。
這是一個包含五個領(lǐng)域的數(shù)據(jù)集,有簡單算術(shù)(“加法”)、詞匯重組(“字謎”)、地理知識(“位置”)、基礎(chǔ)和高級科學問題(“科學”)以及以信息為中心的轉(zhuǎn)換(“轉(zhuǎn)換”)。
 作者介紹
作者介紹論文一作Lexin Zhou(周樂鑫),目前剛從劍橋大學CS碩士畢業(yè)(24歲),研究興趣為大語言模型評測。
在此之前,他在瓦倫西亞理工大學獲得了數(shù)據(jù)科學學士學位,指導老師是Jose Hernandez-Orallo教授。

個人主頁顯示,他曾有多段工作實習經(jīng)歷。在OpenAI和Meta都參與了紅隊測試。(Red Teaming Consultancy )

關(guān)于這篇論文,他重點談到:
論文也具體提到了導致這些不可靠性的一些可能原因,以及解決方案:
對此,你有何看法?
相關(guān)推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務必進行充分的盡職調(diào)查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
