

 新火種
2023-09-28
新火種
2023-09-28 


PyTorch 2.0現已發布:編譯器性能大幅提升,100% 向后兼容
3 月 19 日消息,PyTorch 2.0 穩定版現已發布。跟先前 1.0 版本相比,2.0 有了顛覆式的變化。在 PyTorch 2.0 中,最大的改進主要是 API 的 torch.compile,新編譯器比先前「eager mode」所提供的即時生成代碼的速度快得多,性能得以進一步提升。
附官網地址:https://pytorch.org/
GitHub 地址:https://github.com/pytorch/pytorch/releases

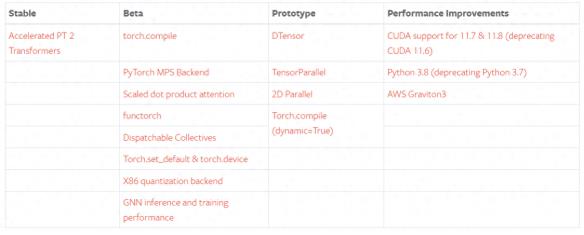
新版本更新之處包括穩定版的 Accelerated Transformers(以前稱為 Better Transformers);Beta 版包括作為 PyTorch 2.0 主要 API 的 torch.compile、作為 torch.nn.functional 一部分的 scaled_dot_product_attention 函數、MPS 后端、torch.func 模塊中的 functorch API;以及其他跨越各種推理、性能和訓練優化功能的 GPU 和 CPU 的 Beta / Prototype 改進。
關于 torch.compile 的全面介紹和技術概況請見 2.0 入門頁面。
除了 PyTorch 2.0,研發團隊還發布了 PyTorch 域庫的一系列 Beta 更新,包括 in-tree 的庫和 TorchAudio、TorchVision、TorchText 等獨立庫。此外,TorchX 轉向社區支持模式。
概括:
torch.compile 是 PyTorch 2.0 的主要 API,它能包裝并返回編譯后的模型。這個是一個完全附加(和可選)的功能,因此 PyTorch 2.0 根據定義是 100% 向后兼容的。
作為 torch.compile 的基礎技術,TorchInductor 與 Nvidia / AMD GPU 將依賴于 OpenAI Triton 深度學習編譯器來生成性能代碼并隱藏低級硬件細節。OpenAI triton 生成的內核則實現了與手寫內核和專用 cuda 庫 (如 cublas) 相當的性能。
Accelerated Transformers 引入了對訓練和推理的高性能支持,使用自定義內核架構實現縮放點積注意力 (SPDA)。API 與 torch.compile () 集成,模型開發人員也可以通過調用新的 scaled_dot_product_attention () 運算符直接使用縮放點積注意力內核。
Metal Performance Shaders (MPS) 后端能在 Mac 平臺上提供 GPU 加速的 PyTorch 訓練,并增加了對前 60 個最常用運算符的支持,覆蓋 300 多個運算符。
Amazon AWS 優化了 AWS Graviton3 上的 PyTorch CPU 推理。與之前的版本相比,PyTorch 2.0 提高了 Graviton 的推理性能,包括針對 ResNet-50 和 BERT 的改進。
其他一些跨 TensorParallel、DTensor、2D parallel、TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor 的新 prototype 功能和方法。
要查看公開的 2.0、1.13 和 1.12 功能完整列表,請點擊此處。
穩定功能
PyTorch 2.0 版本包括 PyTorch Transformer API 新的高性能實現,以前稱為「Better Transformer API」,現在更名為 「Accelerated PyTorch 2 Transformers」。
研發團隊表示他們希望整個行業都能負擔得起訓練和部署 SOTA Transformer 模型的成本。新版本引入了對訓練和推理的高性能支持,使用自定義內核架構實現縮放點積注意力 (SPDA)。
與「快速路徑(fastpath)」架構類似,自定義內核完全集成到 PyTorch Transformer API 中 —— 因此,使用 Transformer 和 MultiHeadAttention API 將使用戶能夠:
明顯地看到顯著的速度提升;
支持更多用例,包括使用交叉注意力模型、Transformer 解碼器,并且可以用于訓練模型;
繼續對固定和可變的序列長度 Transformer 編碼器和自注意力用例使用 fastpath 推理。
為了充分利用不同的硬件模型和 Transformer 用例,PyTorch 2.0 支持多個 SDPA 自定義內核,自定義內核選擇邏輯是為給定模型和硬件類型選擇最高性能的內核。除了現有的 Transformer API 之外,模型開發人員還可以通過調用新的 scaled_dot_product_attention () 運算來直接使用縮放點積注意力內核。
要使用您的模型,同時受益于 pt2 編譯的額外加速 (用于推斷或訓練),請使用 model = torch.compile (model) 對模型進行預處理。
我們通過使用自定義內核和 torch.compile () 的組合,使用 Accelerated PyTorch 2 transformer 實現了訓練 transformer 模型的大幅加速,特別是大語言模型。
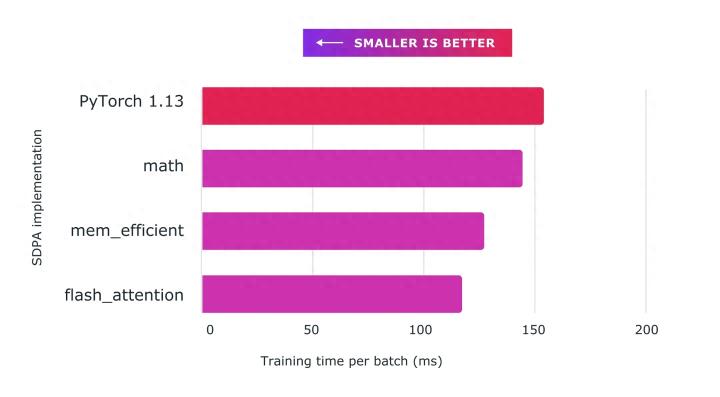
從官方數據可以看到,PyTorch 2.0 的編譯效率比 1.0 實現了大幅提高。
這個數據來自 PyTorch 基金會在 Nvidia A100 GPU 上使用 PyTorch 2.0 對 163 個開源模型進行的基準測試,其中包括圖像分類、目標檢測、圖像生成等任務,以及各種 NLP 任務。
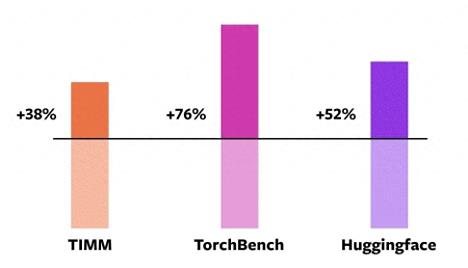
這些 Benchmark 分為三類:TIMM、TorchBench、HuggingFace Tranformers。
據 PyTorch 基金會稱,新編譯器在使用 Float32 精度模式時運行速度提高了 21%,在使用自動混合精度(AMP)模式時運行速度提高了 51%。在這 163 個模型中,torch.compile 可以在 93% 模型上正常運行。
值得一提的是,官方在桌面級 GPU(如 NVIDIA 3090)上測量到的加速能力低于服務器級 GPU(如 A100)。到目前為止,PyTorch 2.0 默認后端 TorchInductor 已經支持 CPU 和 NVIDIA Volta 和 Ampere GP,暫不支持其他 GPU、XPU 或舊的 NVIDIA GPU。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
