

 新火種
2024-09-08
新火種
2024-09-08 


太火了!我在外灘大會玩Deepfake,想騙過機器人結(jié)果……
我在外灘大會上生成Deepfake,結(jié)果沒騙過機器人……
反倒啪的一下,秒秒鐘就被找出?!

而機器人手中的神兵利器,僅僅只是我們?nèi)粘6荚谑褂玫氖謾C攝像頭。

Deepfake攻防,成為整個外灘大會現(xiàn)場最受關(guān)注的展區(qū)之一;相關(guān)討論也成為整個外灘大會最火熱的論壇,現(xiàn)場可以說是人山人海人擠人。


之所以如此受關(guān)注,也有大眾已知的原因。
這不最近DeepFake可以說是來勢洶洶,用這項AI技術(shù)犯罪的嚴重程度被網(wǎng)友直呼是「韓國N號房再現(xiàn)」。
剛提到的這場“全球Deepfake攻防挑戰(zhàn)賽”,吸引了全球26個國家和地區(qū),2200+技術(shù)研究者對抗Deepfake威脅。在這期間,大賽隊伍中科院自動化所表示,將開源AI模型供大家免費使用,一時間引發(fā)全網(wǎng)朋友共鳴。
如今在外灘大會,終于有機會親自體驗這個Deepfake從生成到對抗的流程是什么樣,看AI如何幫助普通人識別偽造風(fēng)險。
這背后究竟還有哪些細節(jié)?除此之外還有哪些亮點,我們一起來看看。
探展螞蟻數(shù)科那么首先就來看螞蟻數(shù)科里這個超火的展區(qū):Deepfake攻防。
整個過程你唯一需要做的,就是站在一個定點,由iPad拍攝人臉。
然后,就由現(xiàn)有AI模型來生成的換臉圖or視頻。

Deepfake就由機械臂來從三組圖+一個視頻中找出真照片。可以看到視頻還是很逼真的,這下誰能證明“我不是我”。

由于是現(xiàn)場實時物理采集,機械臂手持智能手機打開相機拍照來收集數(shù)據(jù),然后再進行一個識別的操作。
短短幾秒鐘的時間,bingo~機器人就識別出來了正確答案。

據(jù)現(xiàn)場工作人員介紹,在他們?nèi)粘9ぷ髦校羁烊刖涂梢宰R別出來。
這背后是由天璣實驗室以及安全品牌ZOLOZ提供技術(shù)支持。
前者主要專注在可信數(shù)字身份這塊,自研了一套自動化生物識別測評體系。當(dāng)前市面上70%的安卓手機,都要來到天璣實驗室經(jīng)歷一番“毒打”。它也是谷歌全球唯一官方合作”安卓生物識別安全”檢測實驗室。
而后者,則是螞蟻數(shù)科旗下安全科技品牌ZOLOZ,現(xiàn)在在為中國、印尼、馬來西亞、菲律賓等14個國家和地區(qū)的70余家合作伙伴提供技術(shù)服務(wù),包括像端到端身份驗證、在線欺詐檢測以及持續(xù)風(fēng)險監(jiān)控服務(wù)等。
今年4月,他們推出了反Deepfake產(chǎn)品ZOLOZ Deeper。外灘大會展示的,正好是他們?nèi)粘5恼鎸崢I(yè)務(wù)場景——
幾十萬測試樣本,每月超20000次的攻防測評,模擬上百種偽造攻擊情況·····
同樣以直觀可感的方式展示出來的,還有他們的AI標注場景。
AI大模型生產(chǎn)流程通常包括三個步驟:采集-標注-合成。
首先是采集過程。
現(xiàn)場準備了一個模擬真實環(huán)境的沙盤,我們通過控制機械臂來對沙盤中任意位置or場景,進行實時拍照。

這時候圖像數(shù)據(jù)也就被傳輸?shù)较到y(tǒng)當(dāng)中去,這也就完成了數(shù)據(jù)生產(chǎn)的起點。
隨后就是標注這一步驟,不再是傳統(tǒng)依靠純?nèi)斯さ姆绞剑且揽孔匝械亩嗄B(tài)大模型來AIGD(AI生成數(shù)據(jù))。
模型會自動完成目標檢測并標注、語義分割、文本描述、深度檢測、3D建模等任務(wù)。

人類主打一個協(xié)助審核的作用,比如在文本描述階段,需要靠人工來審核識別目標的細節(jié),比如物體的顏色、形狀等等。
最后就來到數(shù)據(jù)合成。核心特點就是可控。既可以對單個物體編輯,也可以對整體場景把關(guān)。

這樣一來無需采集,打破原有真實條件限制,可持續(xù)地生產(chǎn)全新的數(shù)據(jù)。
而除了實景標注,旁邊還有個視頻標注的模塊,只需對任意視頻中的任意一幀進行采集,同樣也可以完成接下來的標注和合成操作。
這樣一套全鏈路生產(chǎn)體系,實測顯示,在同類結(jié)構(gòu)和同類規(guī)模數(shù)據(jù)量的情況下,會讓標注效率提升40%以上。
除了智能化標注產(chǎn)品,螞蟻數(shù)科還配備了萬人的人工標注團隊,垂直專業(yè)領(lǐng)域同高階標注人才超過90%。

提到數(shù)據(jù)標注,當(dāng)前市面上最具代表的莫過于Scale AI,科技圈當(dāng)紅獨角獸,他最新完成近 10 億美元融資,估值升至 138 億美元。
不過同Scale AI不同的是,此次可以看到螞蟻數(shù)科還提供數(shù)據(jù)加工、合成服務(wù)。
比如在一些企業(yè)私域或者垂直領(lǐng)域,大量數(shù)據(jù)尚未公開沒有被充分挖掘。
結(jié)合螞蟻數(shù)科多年來場景和技術(shù)優(yōu)勢,這時候除了幫助企業(yè)實現(xiàn)數(shù)據(jù)服務(wù)的“就地取材”,還可以針對性地數(shù)據(jù)泛化,比如像交通、政務(wù)、金融等垂直場景,合成更多高質(zhì)量數(shù)據(jù)。
好了,以上Deepfake攻防與智能標注是此次螞蟻數(shù)科最具代表性的展區(qū)內(nèi)容。
值得注意的是,這正好是當(dāng)前業(yè)界正在熱議也是最受關(guān)注的兩個問題:
當(dāng)AI應(yīng)用泛濫,如何應(yīng)對造假問題;大模型加速落地,高質(zhì)量數(shù)據(jù)缺失又應(yīng)該如何解決?
如今大模型時代來到應(yīng)用時期,更多風(fēng)險和問題由此暴露出來,給企業(yè)帶來了不少挑戰(zhàn)。
對于本身在產(chǎn)業(yè)深耕多年的螞蟻數(shù)科,其實這次也帶來了他們的解決方案。
這藏在外灘大會上,藏在這兩個最受關(guān)注的產(chǎn)品之中。
他們整個業(yè)務(wù)布局,可以這樣總結(jié):從AI For Data到Data for AI。
從AI For Data到Data for AI什么是從AI For Data到Data for AI?要回答這個問題,需要從整個產(chǎn)業(yè)現(xiàn)狀開始看。
AI發(fā)展到現(xiàn)在,從模型驅(qū)動來到了數(shù)據(jù)驅(qū)動,而隨著數(shù)字化轉(zhuǎn)型的深入,企業(yè)生產(chǎn)經(jīng)營實際上是數(shù)據(jù)的流通。技術(shù)與場景,AI與Data,從未像今天這樣如此契合。業(yè)務(wù)場景需要AI來提效,而高質(zhì)量數(shù)據(jù)需要充分利用為給AI。
一邊是AI for data,利用AI來充分挖掘數(shù)據(jù)的價值,進行數(shù)據(jù)分析、判別等。
以風(fēng)控場景為例,這是每個企業(yè)經(jīng)營生產(chǎn)時都會面對的場景。
螞蟻數(shù)科搭建了一套決策式AI驅(qū)動的風(fēng)控算法模型。引入像工商司法數(shù)據(jù)、財報數(shù)據(jù)、產(chǎn)業(yè)鏈數(shù)據(jù)、發(fā)票稅務(wù)數(shù)據(jù)、輿情數(shù)據(jù)等,來幫助企業(yè)做出高效準確的決策。
以往需要大量人力進行人肉風(fēng)控,對于他們來說,理解管理訴求和快速決策布控非常具有挑戰(zhàn)性。而現(xiàn)在只需要AI這個決策輔助在手,運營新手面對再復(fù)雜的場景也能hold住了。
比如螞蟻數(shù)科與中鐵建的合作中,他們共建了一套“產(chǎn)業(yè)數(shù)據(jù)+AI模型”的產(chǎn)業(yè)風(fēng)控平臺,讓產(chǎn)業(yè)鏈的客商準入效率提升了至少50%。
一邊data for AI,高質(zhì)量數(shù)據(jù)是訓(xùn)練AI模型的基礎(chǔ)。AI驅(qū)動的數(shù)據(jù)服務(wù)-數(shù)據(jù)加工-數(shù)據(jù)標注于一體的方案,加速企業(yè)大量原始非結(jié)構(gòu)化數(shù)據(jù)朝著高質(zhì)量結(jié)構(gòu)化數(shù)據(jù)的轉(zhuǎn)化。
除此之外,還有像蟻天鑒這樣的大模型安全產(chǎn)品,來保障大模型在訓(xùn)練生產(chǎn)和使用過程中的安全可控可靠。
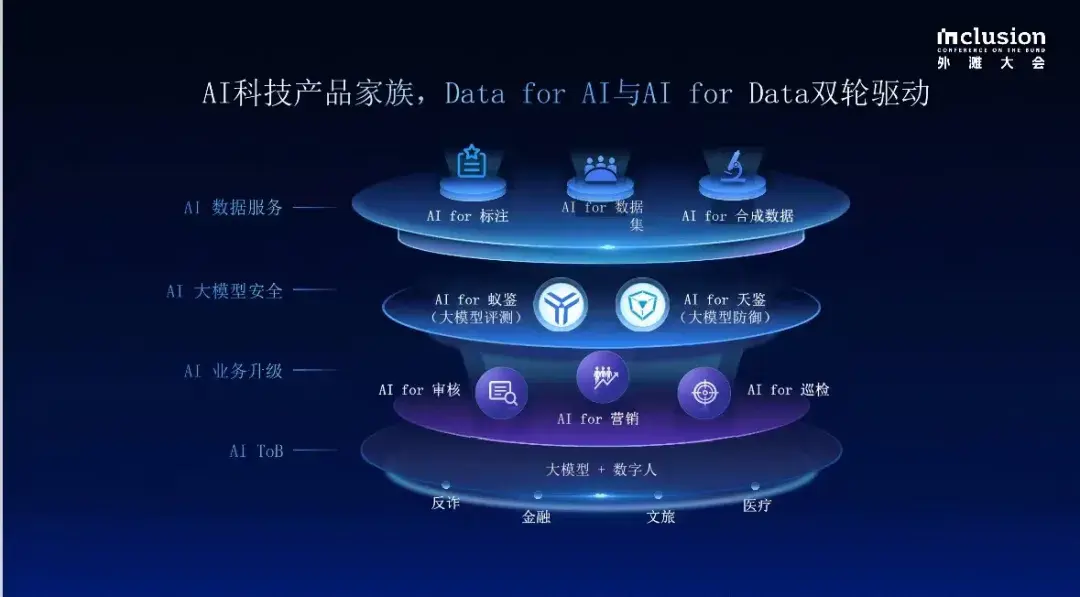
我們注意到,螞蟻數(shù)科已經(jīng)形成ABC三大業(yè)務(wù)板塊:
首先是云服務(wù)(Cloud+),幫助企業(yè)邁入數(shù)字化「上云」階段,打造更強大的科技引擎;
第二塊是AI服務(wù)(AI+),以AI技術(shù)重構(gòu)升級風(fēng)控、營銷等場景效率,助力企業(yè)在大模型時代建立競爭優(yōu)勢。
第三塊是區(qū)塊鏈服務(wù)(Blockchain+),通過科技構(gòu)建產(chǎn)業(yè)信任,提升數(shù)字化協(xié)作效率,加速數(shù)據(jù)資產(chǎn)流通。
對于螞蟻數(shù)科來說,ABC中的“A”很重要,很明顯的指向是,此次螞蟻數(shù)科呈現(xiàn)出來的業(yè)務(wù)布局“從AI For Data到Data for AI”,有三個特點:
產(chǎn)業(yè)、產(chǎn)業(yè)還是產(chǎn)業(yè)。用AI真實創(chuàng)造產(chǎn)業(yè)價值,解決實際問題。這同樣也是大模型應(yīng)用最緊要的命題。
產(chǎn)業(yè)需要什么樣的AI?大模型發(fā)展到現(xiàn)在,人們對大模型的看法已經(jīng)變了。
比如就從最近諸多行業(yè)問題與思考開始,圖像視頻生成模型頻頻開卷,人們的目光不再聚焦于效果多么驚艷,而是因為效果過于逼真,開始擔(dān)心背后的潛在隱憂;被「緩解高質(zhì)量數(shù)據(jù)荒」的數(shù)據(jù)合成,結(jié)果Nature封面一個:Garbage in Garbage out,數(shù)據(jù)合成越多會導(dǎo)致語言模型崩潰,給這個新興行業(yè)趨勢澆了冷水……
以及關(guān)于ScallingLaws的討論,在行業(yè)應(yīng)用的大模型,參數(shù)量到底在多少合適?真的是越來愈多,模型性能就會好嗎?
種種問題,甚至還導(dǎo)向了另一種傾向:大模型,是不是真的存在泡沫?
之所以能引起這樣的思考,其實也不難理解。
隨著大模型技術(shù)的發(fā)展和應(yīng)用的深入,一方面人們逐漸意識到了大模型能力的邊界。模型的參數(shù)量不再作為模型能力的核心指標,高質(zhì)量的數(shù)據(jù)流入才能保證模型高性能。
另一方面,大模型進入應(yīng)用深水區(qū)。產(chǎn)業(yè)界對AI的需求,已經(jīng)不僅僅是單純的技術(shù)追求,解決實際問題才是衡量大模型的唯一標準。

隨之而來的,就是場景中的諸多挑戰(zhàn)。
以數(shù)據(jù)問題為例,當(dāng)前市面上通用大模型都是基于互聯(lián)網(wǎng)公開的數(shù)據(jù)集。他們雖然數(shù)量眾多、類別廣泛,但是無法保質(zhì)保量,甚至大部分都是“臟”數(shù)據(jù)。
對于專業(yè)嚴肅的應(yīng)用場景來說,一來更多高質(zhì)量的行業(yè)數(shù)據(jù)是非公開的,又或者是企業(yè)內(nèi)部自身的,這需要系統(tǒng)來統(tǒng)一調(diào)度和管理,還有一些非結(jié)構(gòu)數(shù)據(jù)需要轉(zhuǎn)化;二來,對于大量公開的數(shù)據(jù)需要工程級別的清洗、標注,才能達到能使用訓(xùn)練的水平。
因此看大模型落地千行百業(yè),不能簡單看大模型的性能展示,而是說怎么同產(chǎn)業(yè)的深度融合。
而本身就在產(chǎn)業(yè)有著長期投入的企業(yè),他們有著天然的場景優(yōu)勢,也最有可能將AI能力和影響力才能滲透進行業(yè)之中。
螞蟻數(shù)科,就是一個。
— 完 —
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責(zé)任。
