

 新火種
2024-06-07
新火種
2024-06-07 


斯坦福讓“GPU高速運(yùn)轉(zhuǎn)”的新工具火了,比FlashAttention2更快
AI算力資源越發(fā)緊張的當(dāng)下,斯坦福新研究將GPU運(yùn)行效率再提升一波——
內(nèi)核只有100行代碼,讓H100比使用FlashAttention-2,性能還要提升30%。
怎么做到的?
研究人員從“硬件實(shí)際需要什么?如何滿足這些需求?”這兩個(gè)問(wèn)題出發(fā),設(shè)計(jì)了 一個(gè)嵌入式CUDA DSL工具,名為ThunderKittens(暫且譯為雷貓)。
雷貓可簡(jiǎn)化AI內(nèi)核的編寫,同時(shí)充分利用底層硬件能力。

具體來(lái)說(shuō),雷貓的主要抽象是寄存器和共享內(nèi)存中的小型張量塊(tile),和目前GPU中對(duì)小矩陣乘法的優(yōu)化相匹配。
通過(guò)操作這些tile,開(kāi)發(fā)者可相對(duì)簡(jiǎn)單地編寫代碼,充分利用張量核心、異步數(shù)據(jù)傳輸和共享內(nèi)存等硬件特性。
使用雷貓實(shí)現(xiàn)的注意力機(jī)制內(nèi)核,代碼量少且能實(shí)現(xiàn)很高的硬件利用率,性能超過(guò)直接使用底層庫(kù)(如Cutlass)。
詳細(xì)討論過(guò)程以及雷貓是怎么設(shè)計(jì)出的,研究人員以“GPUs Go Brrr”為題,發(fā)在了斯坦福Hazy Research的Blog網(wǎng)站上。

網(wǎng)友們對(duì)此討論也十分熱烈。
有網(wǎng)友表示讀這篇Blog時(shí),讓他想起了初次了解超標(biāo)量CPU架構(gòu)時(shí)的驚訝感受:
還有網(wǎng)友表示:
 H100里有什么?
H100里有什么?斯坦福研究人員以H100為例,探討了優(yōu)化GPU的方法。
首先,回顧一下H100的硬件細(xì)節(jié),這對(duì)于接下來(lái)的討論非常重要。

一個(gè)H100 SXM GPU包含:
(1)80GB的HBM3內(nèi)存,帶寬為3TB/s(實(shí)際帶寬略低)。
(2)50MB的L2緩存,帶寬為12TB/s,在GPU上分為兩個(gè)25MB的部分,通過(guò)交叉開(kāi)關(guān)連接(這個(gè)交叉開(kāi)關(guān)表現(xiàn)不佳)。
(3)132個(gè)流式多處理器(SM),每個(gè)包含:
高達(dá)227KB的共享內(nèi)存位于256KB的L1緩存中(這些加起來(lái)的帶寬大約33TB/s)。一個(gè)張量?jī)?nèi)存加速器(TMA)——這是英偉達(dá)Hopper架構(gòu)中的一種新硬件組件,可進(jìn)行異步地址生成和內(nèi)存獲取,還能促進(jìn)片上內(nèi)存網(wǎng)絡(luò)。4個(gè)子單元,每個(gè)含:一個(gè)warp scheduler;512個(gè)向量寄存器(每個(gè)包含32個(gè)4字節(jié)的詞);一個(gè)用于執(zhí)行矩陣乘法的張量核心;一組內(nèi)置指令,如求和、乘法等,這些指令能夠并行操作這些向量寄存器。
除了這些,一個(gè)GPU還包括內(nèi)存控制器、指令緩存……但對(duì)于這項(xiàng)研究而言不重要。
重要的是,所有的計(jì)算都發(fā)生在流式多處理器中,大部分計(jì)算是在寄存器中。
H100 GPU擁有989 TFLOPs的半精度矩陣乘法計(jì)算能力,以及約60 TFLOPs的“其他”計(jì)算能力。因此,每個(gè)周期內(nèi)張量核心被使用時(shí),至少能達(dá)到94%的硬件利用率。而張量核心不被使用時(shí),硬件的利用率不會(huì)超過(guò)6%。
換句話說(shuō):
H100的利用率=張量核心活躍周期的百分比+/- 6%。

所以要充分發(fā)揮H100的能力,關(guān)鍵是保持張量核心持續(xù)運(yùn)算。
榨干H100,要注意什么?
然鵝,要保持張量核心持續(xù)運(yùn)行并不容易。
研究人員發(fā)現(xiàn)GPU硬件具有一些特性,對(duì)于保持矩陣乘法的運(yùn)行非常重要:
WGMMA指令雖然是必要的,但使用起來(lái)頗為麻煩。共享內(nèi)存的速度并不如預(yù)期的快,使用時(shí)還需格外注意。生成地址的成本較高。保持高占用率對(duì)于提升性能是有益的,寄存器至關(guān)重要。
這些特性在非H100 GPU上也有所適用,在H100上更加典型,就拿RTX 4090來(lái)說(shuō),相比H100處理起來(lái)簡(jiǎn)單得多。

所以接下來(lái)還是以H100為例,展開(kāi)探討這幾點(diǎn)特性。
WGMMA指令
H100引入了一套新的指令集,名為“warp group matrix multiply accumulate”(在PTX中為wgmma.mma_async,在SASS中為HGMMA/IGMMA/QGMMA/BGMMA)。
要理解這些指令的特點(diǎn),需回顧以往張量核心的使用方式。
早期GPU中的張量核心指令如wmma.mma.sync和mma.sync,要求SM一個(gè)子單元內(nèi)的32個(gè)線程的一個(gè)warp同步傳輸數(shù)據(jù)塊至張量核心并等待結(jié)果。
wgmma.mma_async指令則不同。它允許128個(gè)連續(xù)線程跨SM所有子單元協(xié)作同步,并從共享內(nèi)存及寄存器(可選)異步啟動(dòng)矩陣乘法。這使得這些warp在等待矩陣乘法結(jié)果時(shí)可以處理其他任務(wù)。
研究人員通過(guò)微觀基準(zhǔn)測(cè)試,發(fā)現(xiàn)這些指令是充分發(fā)揮H100計(jì)算能力所必需的。沒(méi)有這些指令,GPU的峰值利用率大約只有63%。
他們推測(cè),這是由于張量核心需要從本地資源維持一個(gè)深度硬件pipeline。
然而,這些指令的內(nèi)存布局極其復(fù)雜。未重排的共享內(nèi)存布局合并性差,需要額外的L2帶寬。重排的內(nèi)存布局記錄不準(zhǔn)確,研究人員花費(fèi)了大量時(shí)間才弄明白。

最終發(fā)現(xiàn),這些布局只適用于特定矩陣形狀,并與wgmma.mma_async指令的其他部分不兼容,例如硬件僅在未重排的布局下轉(zhuǎn)置子矩陣。
此外,未重排的wgmma布局內(nèi)存合并性差且有bank conflicts。盡管TMA和L2緩存在如flash attention這類內(nèi)核上能較好地掩蓋這些問(wèn)題,但要充分利用硬件,必須精心控制內(nèi)存請(qǐng)求的合并和避免bank conflicts。
盡管有這些問(wèn)題,但這些指令對(duì)于充分利用H100是必不可少的。沒(méi)有它們,GPU的潛在性能就損失了37%。
共享內(nèi)存
共享內(nèi)存的單次訪問(wèn)延遲約為30個(gè)周期(這也與研究人員觀察的相符),這看似不多,但在這段時(shí)間內(nèi),SM的張量核心幾乎能完成兩次完整的32×32方陣乘法。
以前的研究,如Flash Attention,研究人員更多關(guān)注的是HBM-SRAM的瓶頸。但隨著HBM速度的提升和張量核心的快速發(fā)展,即使是共享內(nèi)存的相對(duì)較小延遲也變得尤為關(guān)鍵。
由于共享內(nèi)存被分為32個(gè)獨(dú)立的存儲(chǔ)單元,處理不當(dāng)可能會(huì)引發(fā)bank conflicts,即同一個(gè)內(nèi)存bank同時(shí)被多個(gè)請(qǐng)求訪問(wèn),這種情況會(huì)導(dǎo)致請(qǐng)求被序列化。研究人員實(shí)驗(yàn)后認(rèn)為,這會(huì)顯著拖慢內(nèi)核速度,且wgmma與mma指令需要的寄存器布局容易受到bank conflicts的影響。
解決方法是通過(guò)各種“重排”模式調(diào)整共享內(nèi)存的配置,避免bank conflicts,但細(xì)節(jié)要處理得當(dāng)。
此外研究人員發(fā)現(xiàn),盡可能避免在寄存器和共享內(nèi)存之間的移動(dòng)數(shù)據(jù)非常重要。可能的話,可使用內(nèi)置硬件(如wgmma和TMA指令)進(jìn)行異步數(shù)據(jù)傳輸。實(shí)在沒(méi)法子了,再使用warp進(jìn)行同步數(shù)據(jù)傳輸。
地址生成
H100還有一個(gè)有趣的特性,其張量核心和內(nèi)存都足夠快,以至于僅生成用于獲取數(shù)據(jù)的內(nèi)存地址就占用了芯片的大量資源,特別是加入復(fù)雜的交錯(cuò)或重排模式時(shí),這種情況更為明顯。
研究人員表示,英偉達(dá)提供了張量?jī)?nèi)存加速器(TMA),似乎就是已經(jīng)意識(shí)到了這個(gè)問(wèn)題。
TMA允許用戶在全局和共享內(nèi)存中指定多維張量布局,命令其異步提取張量的一部分,并在完成后觸發(fā)一個(gè)屏障。這大大節(jié)省了地址生成的開(kāi)銷,并簡(jiǎn)化了pipelines的構(gòu)建。
研究人員認(rèn)為,TMA對(duì)于充分發(fā)揮H100的潛力至關(guān)重要,可能比wgmma.mma_async更為關(guān)鍵。
它不僅節(jié)省了寄存器資源和指令派發(fā),還提供了如異步在全局內(nèi)存上執(zhí)行歸約等實(shí)用功能——這在處理復(fù)雜的反向內(nèi)核時(shí)尤其有用。
雖然TMA的重排模式解讀有一定難度,需要進(jìn)行一些逆向工程,但研究人員表示,相比之下,他們?cè)谶@上面遇到的問(wèn)題要少得多。
占用率
占用率指的是在GPU的相同執(zhí)行硬件上同時(shí)調(diào)度的線程數(shù)。每個(gè)周期,SM的某一子單元的warp scheduler會(huì)嘗試向準(zhǔn)備就緒的warp線程發(fā)出指令。
研究人員認(rèn)為,英偉達(dá)采用這種模型可以更容易地保持硬件的滿負(fù)荷運(yùn)行。例如,當(dāng)一個(gè)線程warp等待執(zhí)行矩陣乘法時(shí),另一個(gè)可以被指派執(zhí)行使用快速指數(shù)運(yùn)算的指令。
在某些方面,H100對(duì)占用率的依賴程度低于前幾代硬件。
它的異步特性使得即使單一指令流也能使多個(gè)硬件部分同時(shí)持續(xù)運(yùn)行,包括讀取內(nèi)存、執(zhí)行矩陣乘法、進(jìn)行共享內(nèi)存的歸約,同時(shí)還能在寄存器上進(jìn)行計(jì)算。
但高占用率容易隱藏缺陷或同步問(wèn)題,一個(gè)設(shè)計(jì)良好的pipeline即使在占用率不高的情況下也能運(yùn)行得相當(dāng)快。
據(jù)研究人員觀察,英偉達(dá)在設(shè)計(jì)GPU時(shí)確實(shí)考慮到了占用率。且由于存在足夠多的同步操作和足夠多的錯(cuò)誤可能性,根據(jù)他們的經(jīng)驗(yàn),提高占用率通常能顯著增加硬件的實(shí)際利用率。
此外,相比H100,A100和RTX 4090更依賴同步指令調(diào)度,占用率更重要。
用雷貓優(yōu)化GPU
鑒于以上情況,如何才能更輕松地編寫所需的內(nèi)核類型,同時(shí)充分發(fā)揮硬件的全部潛力?
雷貓(ThunderKittens)登場(chǎng)了。
這是一個(gè)嵌入在CUDA中的DSL,本是斯坦福研究人員設(shè)計(jì)出來(lái)給自己內(nèi)部使用的,后來(lái)發(fā)現(xiàn)還真挺好使。
Ps:起這么個(gè)名,一是他們覺(jué)得小貓很可愛(ài),二來(lái)他們覺(jué)得大伙兒在代碼中輸入kittens::會(huì)很有趣。
具體來(lái)說(shuō),雷貓包含四種模板類型:
寄存器tiles:在寄存器文件上表示二維張量。寄存器向量:在寄存器文件上表示一維張量。共享tiles:在共享內(nèi)存中表示二維張量。共享向量:在共享內(nèi)存中表示一維張量。
tiles通過(guò)高度、寬度和布局進(jìn)行參數(shù)化;寄存器向量通過(guò)長(zhǎng)度和布局進(jìn)行參數(shù)化;而共享向量?jī)H通過(guò)長(zhǎng)度進(jìn)行參數(shù)化,通常不會(huì)遇到bank conflicts問(wèn)題。
此外,研究人員提供了一系列操作來(lái)處理這些張量,既可在warp級(jí)別使用,也可用于多個(gè)warp協(xié)作,包含初始化器,如將共享向量清零;一元操作,如exp;二元操作,如mul;行/列操作,例如行求和。
雷貓作為一個(gè)嵌入到CUDA中的庫(kù),其提供的抽象層在遇到不支持的功能時(shí)能夠很好地處理。如果雷貓缺少某些功能,可以直接擴(kuò)展它來(lái)實(shí)現(xiàn)你想要的效果。
以Tri的flash attention算法為例,在實(shí)際應(yīng)用中,即使是使用英偉達(dá)的Cutlass庫(kù),實(shí)現(xiàn)起來(lái)也是相當(dāng)復(fù)雜。
在RTX 4090上使用雷貓編寫的簡(jiǎn)單flash attention內(nèi)核。總共約60行CUDA代碼,硬件利用率達(dá)到了75%。代碼復(fù)雜性主要在于算法本身,而非交織模式或寄存器布局。
那么,它的表現(xiàn)如何?
這個(gè)內(nèi)核只有100行代碼,實(shí)際上它在H100上的性能比FlashAttention-2高出約30%。雷貓負(fù)責(zé)包裝布局和指令,提供了一個(gè)可以在GPU上使用的迷你pytorch環(huán)境。
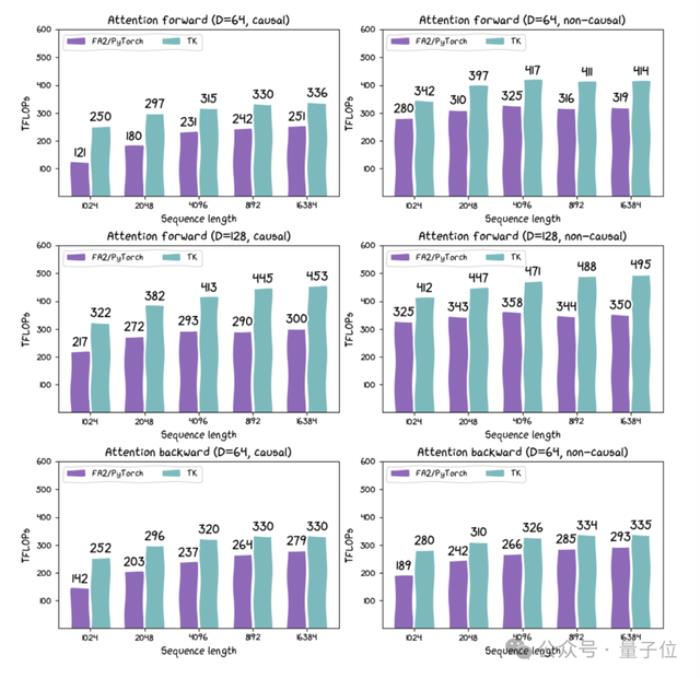
△FA2(通過(guò)Pytorch實(shí)現(xiàn))與TK在H100 SXM上的多種配置比較
此外,研究人員還發(fā)布了基于線性注意力和其他新架構(gòu)的內(nèi)核。其中基于線性注意力的內(nèi)核的運(yùn)行速度可達(dá)215 TFLOPs,如果考慮到算法中固有的重計(jì)算,速度可超過(guò)300 TFLOPs。
盡管線性注意力在理論上效率更高,但此前在實(shí)際硬件上表現(xiàn)并不佳。因此,研究人員認(rèn)為這可能促進(jìn)一系列高吞吐量應(yīng)用的發(fā)展。
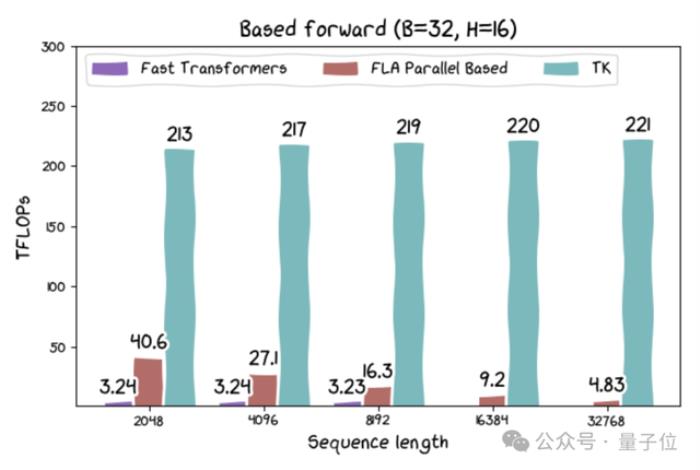
small tile符合AI和硬件發(fā)展趨勢(shì)
最后,雷貓研究團(tuán)隊(duì)總結(jié)了開(kāi)發(fā)雷貓的一些思考。在他們看來(lái),雷貓之所以有效,是因?yàn)樗哪繕?biāo)并不是試圖做所有事:
CUDA的確比雷貓表達(dá)能力更廣,雷貓小而簡(jiǎn)單,功能有限。但雷貓的small tiles抽象設(shè)計(jì)符合AI和硬件的發(fā)展趨勢(shì)。
雖然雷貓不支持小于16的維度,但研究人員認(rèn)為這并不重要,因?yàn)橛布膊粌A向于支持過(guò)小的維度。
從理論出發(fā),研究人員認(rèn)為需要進(jìn)行一種框架轉(zhuǎn)變。
“寄存器當(dāng)然不應(yīng)該像舊CPU那樣32位字。CUDA使用的1024位寬向量寄存器確實(shí)是朝著正確方向邁出的一步。但對(duì)我們來(lái)說(shuō),寄存器是16×16的數(shù)據(jù)tile。我們認(rèn)為AI需要這樣的設(shè)計(jì),畢竟,它仍然只是矩陣乘法、歸約和重塑。我們認(rèn)為硬件也需要這樣的設(shè)計(jì),小型矩陣乘法迫切需要超出系統(tǒng)級(jí)MMA的硬件支持。”
研究人員認(rèn)為,應(yīng)該根據(jù)硬件特性來(lái)重新定義AI的設(shè)計(jì)理念。例如,循環(huán)狀態(tài)應(yīng)該有多大?應(yīng)該足夠大以適應(yīng)一個(gè)SM。計(jì)算的密度應(yīng)該有多高?不應(yīng)低于硬件的需求。
Tags:
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
