

 新火種
2024-02-21
新火種
2024-02-21 

7B開源數學模型干翻千億GPT-4,中國團隊出品
7B開源模型,數學能力超過了千億規模的GPT-4!
它的表現可謂是突破了開源模型的極限,連阿里通義的研究員也感嘆縮放定律是不是失效了。

無需借助任何外部工具,它就能在競賽水平的MATH數據集上達到51.7%的準確率。
在開源模型中,它第一個在該數據集上達到一半的準確率,甚至超過了早期和API版本的GPT-4。
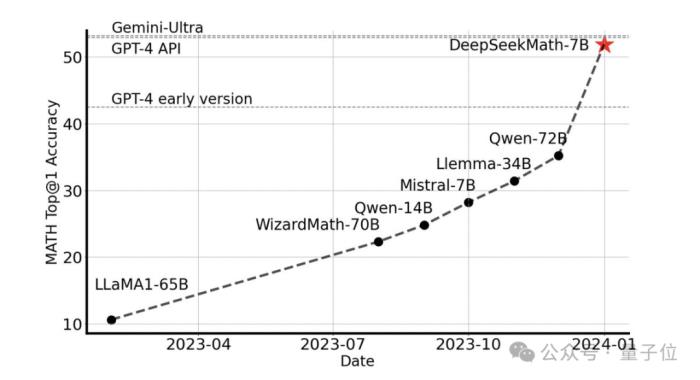
這一表現讓整個開源社區為之震撼,Stability AI的創始人Emad Mostaque也表示研發團隊屬實讓人印象深刻,而且潛力被低估了。
它,就是深度求索團隊最新開源的7B數學大模型DeepSeekMath。
7B模型力壓群雄
為了評估DeepSeekMath的數學能力,研究團隊使用了中(MGSM-zh、CMATH)英(GSM8K、MATH)雙語的數據集進行了測試。
在未使用輔助工具、僅靠思維鏈(CoT)提示的情況下,DeepSeekMath的表現均超越了其他開源模型,其中包括70B的數學大模型MetaMATH。
和自家推出的67B通用大模型相比,DeepSeekMath的成績也有大幅提升。
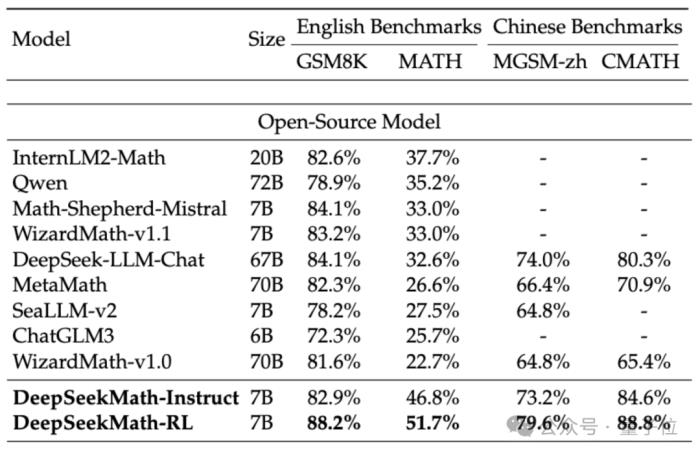
如果考慮閉源模型,DeepSeekMath也是在幾個數據集上都超越了Gemini Pro和GPT-3.5,在中文的CMATH上超越了GPT-4,MATH上的表現也與之接近。
但要注意的是,GPT-4按泄露規格是一個千億參數的龐然大物,而DeepSeekMath參數量只有7B。
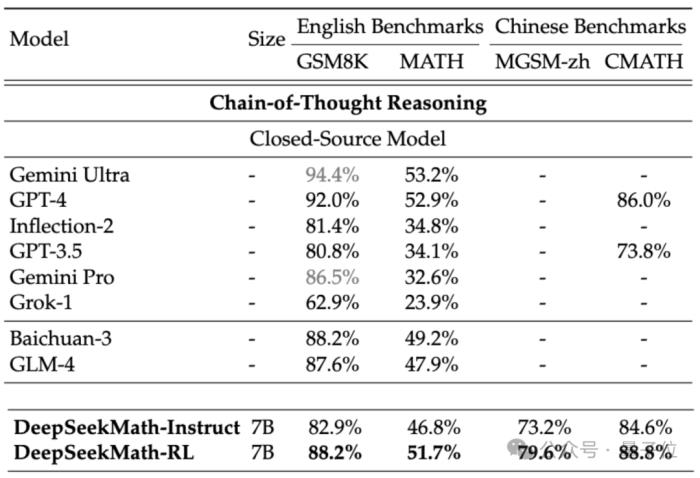
如果允許使用工具(Python)進行輔助,DeepSeekMath在競賽難度(MATH)數據集上的表現還能再提高7個百分點。
那么,DeepSeekMath優異表現的背后,都應用了哪些技術呢?
基于代碼模型打造
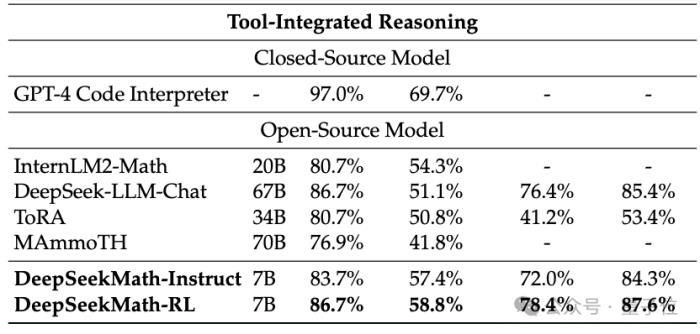
為了獲得比從通用模型更好的數學能力,研究團隊使用了代碼模型DeepSeek-Coder-v1.5對其進行初始化。
因為團隊發現,無論是在兩階段訓練還是一階段訓練設置下,代碼訓練相比于通用數據訓練都可以提升模型的數學能力。
在Coder的基礎上,研究團隊繼續訓練了5000億token,數據分布如下圖:
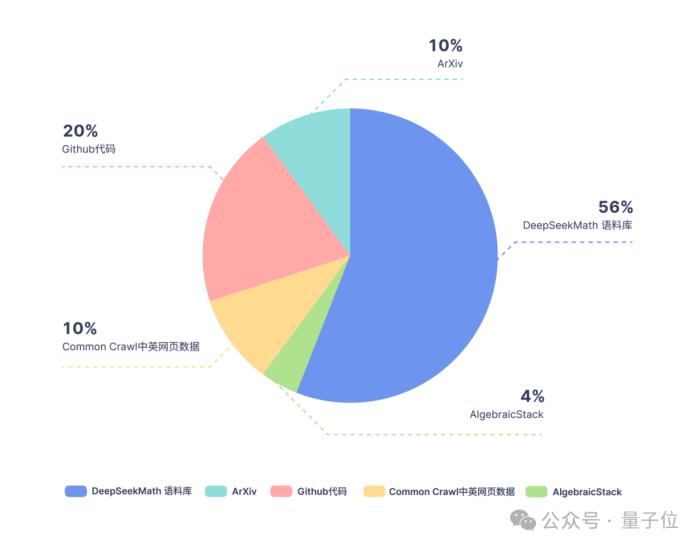
訓練數據方面,DeepSeekMath使用的是從Common Crawl提取的120B高質量數學網頁數據,得到了DeepSeekMath Corpus,總數據量是開源數據集OpenWebMath的9倍。
數據采集過程是迭代式進行的,經過四次迭代,研究團隊收集了3500多萬個數學網頁,Token數量達到了1200億。
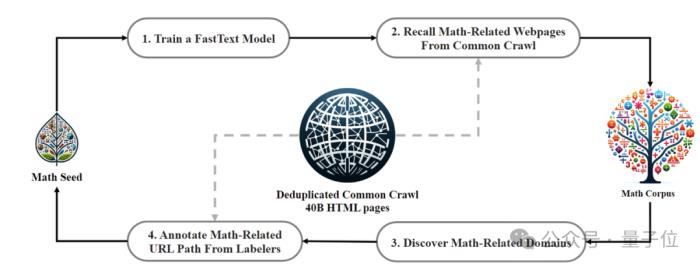
為了確保訓練數據中不包含測試集的內容(因為GSM8K、MATH中的內容在互聯網上大量存在),研究團隊還專門進行了過濾。
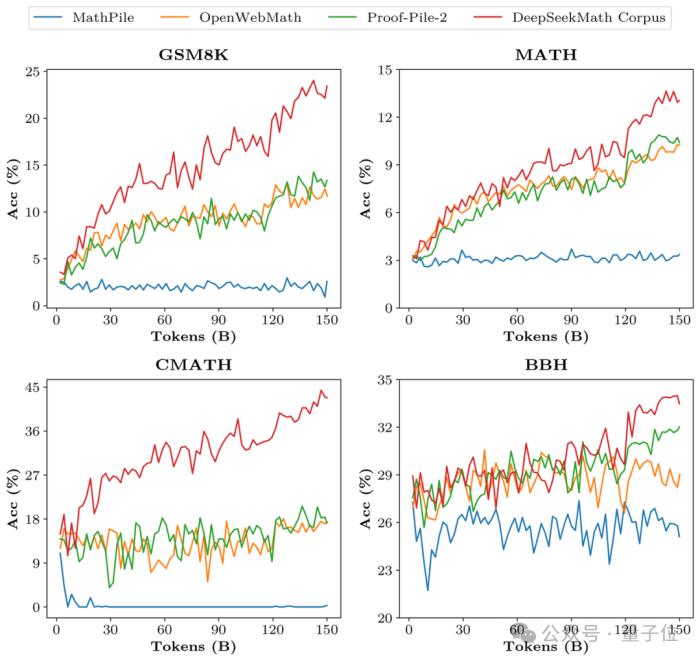
為了驗證DeepSeekMath Corpus的數據質量,研究團隊分別用MathPile等多個數據集訓練了1500億token,結果Corpus在多個數學基準上效果明顯領先。
對齊階段,研究團隊首先構建了一個776K樣本的中英文數學指導監督微調(SFT)數據集,其中包括CoT、PoT和工具集成推理等三種格式。
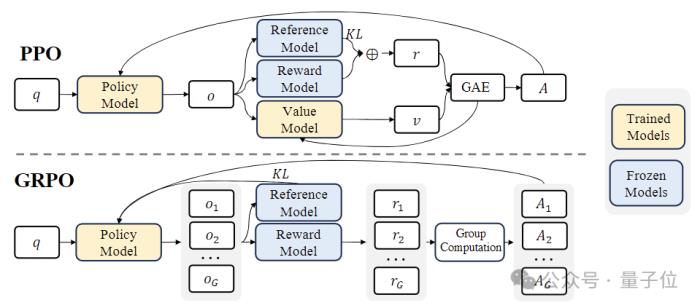
而在強化學習(RL)階段,研究團隊使用了一種名為“基于組的相對策略優化”(Group Relative Policy Optimization ,GRPO)的高效算法。
GRPO是近端策略優化(PPO)的一種變體,過程中傳統的價值函數被替換為一個基于組的相對獎勵估計,可以減少訓練過程中的計算和內存需求。
同時,GRPO通過迭代過程進行訓練,獎勵模型會根據策略模型的輸出不斷更新,以確保策略的持續改進。
曾推出首個國產開源MoE模型
推出DeepSeekMath的深度求索團隊,是國內開源模型領域的一名“頭部選手”。
此前,該團隊就曾推出過首個國產開源MoE模型DeepSeek MoE,它的7B版本以40%的計算量擊敗了相同規模的密集模型Llama 2。
作為通用模型,DeepSeek MoE在代碼和數學任務上的表現就已十分亮眼,而且資源消耗非常低。

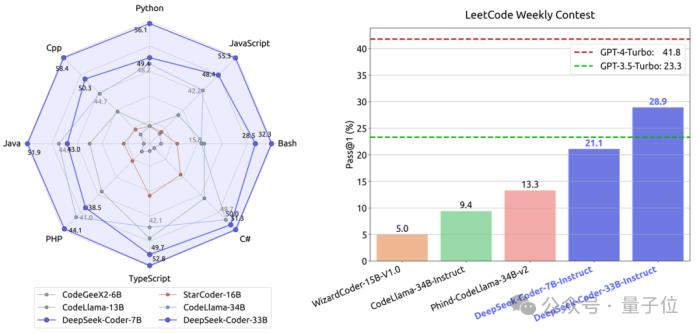
代碼方面,該團隊推出的DeepSeek-Coder的編程能力在代碼生成、跨文件代碼補全、以及程序解數學題等多個任務上均超過了同等規模的開源標桿CodeLllama。
同時,它也擊敗了GPT-3.5-Turbo,成為最接近GPT-4-Turbo的開源代碼模型。
如前文所說,此次推出的DeepSeekMath,也正是在Coder的基礎之上打造的。
而在X上,已經有人開始在期待Coder和Math的MoE版本了。

相關推薦


- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
