

 新火種
2024-06-12
新火種
2024-06-12 


斯坦福團隊抄襲國產AI開源模型
01
近日,斯坦福大學AI團隊主導的Llama3-V開源模型被證實套殼抄襲國內清華與面壁智能的開源模型“小鋼炮”MiniCPM-Llama3-V 2.5一事,在網絡上引發熱議。
巧合的是,最先發現抄襲的,是星空君一起玩AI的朋友,大家先是在群里義憤填膺的批判,然后朋友把相關資料發到推特發酵,最終引起了斯坦福團隊在hugging face刪庫跑路。
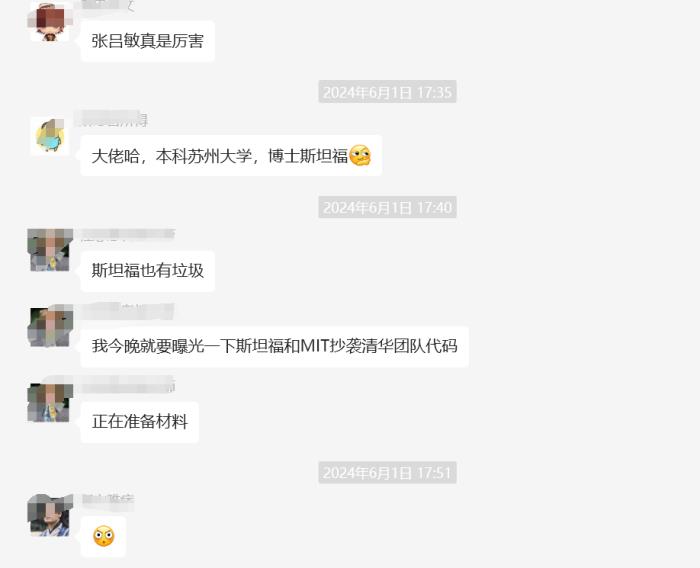
在最新進展中,斯坦福Llama3-V團隊的兩位作者Siddharth Sharma和 Aksh Garg在社交平臺上就這一學術不端行為向面壁MiniCPM團隊正式道歉,并表示會將Llama3-V模型悉數撤下。
6月3日,面壁智能CEO李大海與聯合創始人劉知遠先后發文,回應開源模型被斯坦福大學AI團隊抄襲一事,稱“深表遺憾”:一方面感慨這是一種受到國際團隊認可的方式,另一方面呼吁大家共建開放、合作、有信任的社區環境。“我們希望團隊的好工作被更多人關注與認可,但不是以這種方式。”
其實這從側面反映出中國AI團隊的影響力。
很長一段時間,因為圈外人難以理解的原因,中國的AI團隊背負著“抄襲”、“套殼”的惡名,甚至很多人說“國外一開源,國內就自研”。
ChatGPT剛剛發布的時候,國產的AI因為采用了較多的國外訓練集,使用的時候存在著把用戶的中文翻譯成英文再和大模型交互的情況,被惡毒的攻擊為套殼。
后來,當谷歌的大模型發布的時候,人們發現幾乎存在著一模一樣的問題,才有一部分人明白問題的根源。
在生成式AI方面,美國的團隊走的確實比較快,但并不代表中國一無是處。
如果你研究近年來AI相關的論文,會發現大量的中國團隊和華人散落其中。
如果把世界AI形容成十斗,美國占八斗,中國占一斗,世界其他國家分一斗。
實事求是的講,這樣的實力并不算差。中國在這次AI革命中,沒有落伍,不僅跟上了,還斷崖式領先第三名。
在ChatGPT推出不到一年的時候,中國的生成式AI迅速普及,除了百度的文心一言外,像Kimi、通義千問、ChatGLM都取得了不錯的效果,用戶反饋比較積極。
通義千問和ChatGLM都將最新進行了開源,深受廣大AI愛好者的喜歡。
MiniCPM-Llama3-V 2.5 不是一個很知名的模型,被斯坦福的大學生拿去套殼。這件事有點無厘頭,但也證明了用開源模型套殼這種行為實際上是行不通的,有無數種方式可以驗證大模型是否自研。
當然了,也沒必要把這件事扣到斯坦福大學頭上,這只是一個團隊部分成員的學術不端行為,不用上綱上線。
結論是給中國的AI大模型開發者們一個遲到的正名:他們沒有靠套殼開源來實現自研。
02
斯坦福的團隊抄襲中國團隊的AI開源大模型事件后不久,快手放出了文生視頻大模型:可靈。
從前期內測用戶的體驗來看,可靈幾乎和Sora是同一級別,某些細節還優于Sora。

難能可貴的是,可靈已經開始大規模內測,而發布了小半年的Sora依然還只是PPT狀態。
我一直說,中國的AI的確比美國落后,但并沒有代差,且穩居第二名,遙遙領先第三名。
當可以落地的商業模式跑通的時候,中國的AI場景不會比美國少,甚至可能還更多一些。
因為中國的自媒體行業高度發達,使用AI工具創作圖文、視頻素材,已經開始普及。
有拿到內測賬號的朋友,用之前Sora發布的提示詞交給可靈生成視頻,發現效果非常驚人。

從技術路線講,現在AI技術沒有太高深的技術壁壘。
OpenAI固然niubility,但他們的先發優勢非常小。ChatGPT的3.5版本領先了接近一年,4.0頂多領先了半年,現在已經被各開源大模型追趕了上來。
像中國的Kimi、通義千問、ChatGLM等大模型,近期的實測效果已經不比ChatGPT4.0差。
一方面,大模型(哪怕閉源)的主體技術路線是公開的,一些獨特的訓練技巧,通過高強度大范圍的使用,也是可以推測出來的,在此基礎上進行優化,大模型就可以“奮起直追”;另一方面,大模型行業的人才流動非常頻繁,也促進了技術的傳播。
OpenAI共有770名員工,ChatGPT團隊不足百人,博士、碩士、本科各占三分之一。
隨著追趕的加速,也許一個不留神,就有大模型實現對ChatGPT的“彎道超車”。
像傳統工業時代動輒領先十數年、數十年的技術,在AI時代是不存在的。
由于字節、小紅書之前過于招搖,大家幾乎忘記了快手的存在。
這類短視頻企業最大的優勢就是有海量的音視頻素材,可以方便的進行訓練,而我堅持認為AI大模型本身沒有什么高深的科技,無非就是大力出奇跡。
事實證明也是如此。ChatGPT3.5一炮走紅的時候,人們發現原來居然可以搞一萬張顯卡來訓練,放在其他公司這只能是想想。但模式一旦跑通,各大佬紛紛下場搶購顯卡。
比較搞笑的是,可靈迅速在推特火了起來,但快手相關的APP并沒有純英文版,很多老外在推特上咨詢如何注冊、申請內測資格。
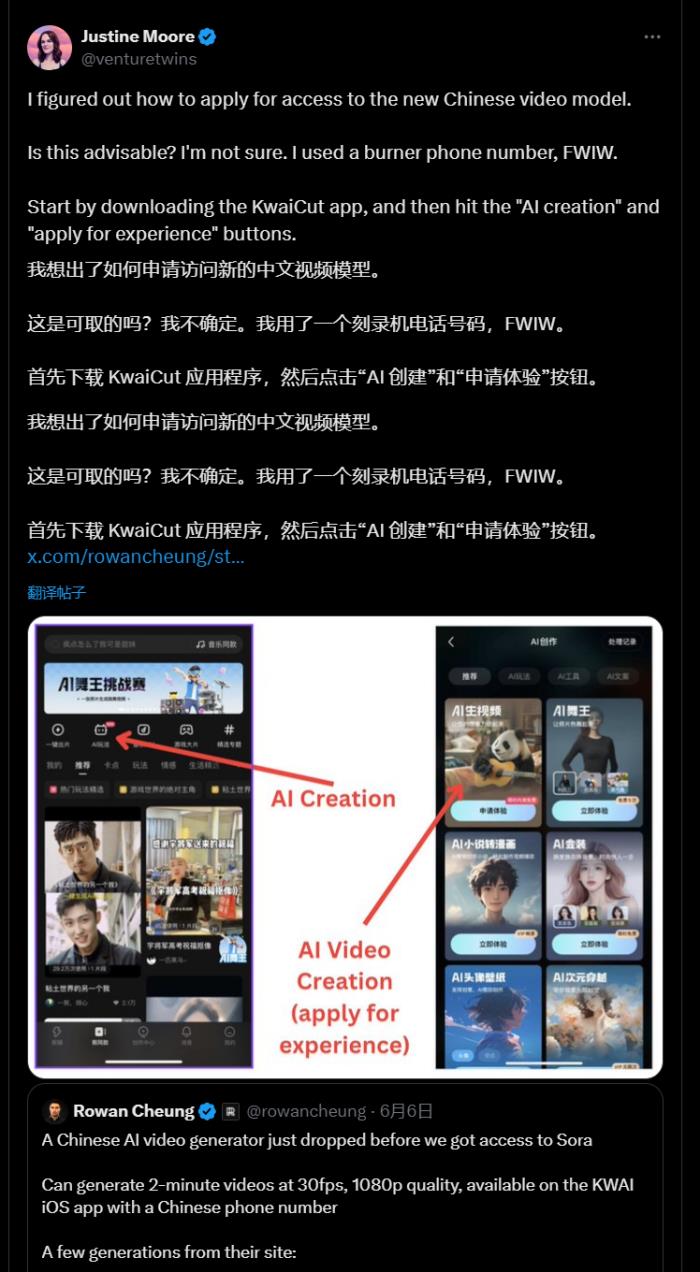
這也讓中國的AI技術反向輸出了一把。
星空君的申請只等待了一天就順利通過,請欣賞星空君用可靈制作的視頻:
提示詞:一艘巨大的火箭從山谷里緩緩起飛,漫山遍野的桃花。
提示詞:一個披肩發女孩站在閃耀的銀河下。
提示詞:宇航員走出太空船,面臨一個冰天雪地的星球。
提示詞:一直正在大海邊彈吉他的大熊貓。
03
6月7日凌晨0點,阿里云通義千問深夜發布技術博文,推出全球性能最強的開源模型Qwen2-72B,性能超過美國最強的開源模型Llama3-70B。
兩小時后,全球最大開源社區Hugging Face的聯合創始人兼首席執行官克萊門特·德朗格宣布,Qwen2-72B沖上HuggingFace 開源大模型榜單Open LLM Leaderboard第一名,全球排名最高。
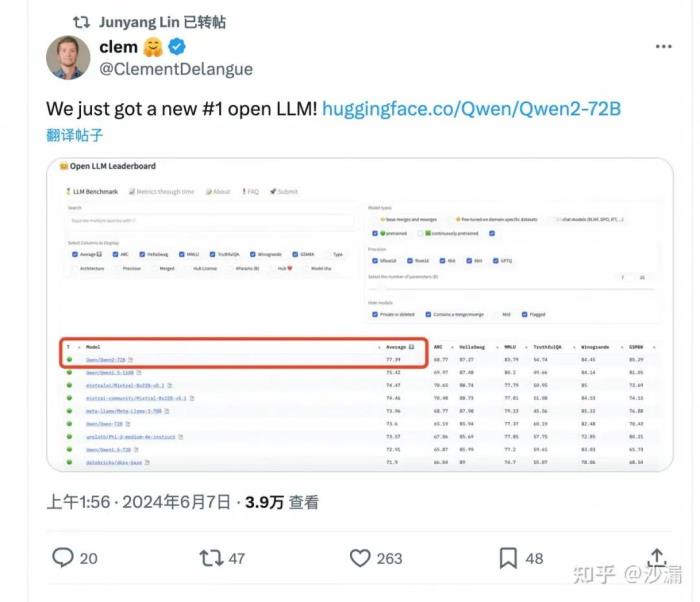
相比2月推出的通義千問Qwen1.5,Qwen2實現了整體性能的代際飛躍。通義千問Qwen2系列模型大幅提升了代碼、數學、推理、指令遵循、多語言理解等能力。
通義千問團隊在技術博客中披露,Qwen2系列包含5個尺寸的預訓練和指令微調模型,Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B,其中Qwen2-57B-A14B為混合專家模型(MoE)。
Qwen2所有尺寸模型都使用了GQA(分組查詢注意力)機制,以便讓用戶體驗到GQA帶來的推理加速和顯存占用降低的優勢。
阿里在AI方面布局非常廣闊,星空君甚至認為在AI創新領域,阿里要比OpenAI更有錢景:阿里的AI研發是直接對接商業模式的,OpenAI的核心技術,在阿里這里幾乎都是開源的!
就像導航軟件,未來極有可能出現OpenAI的核心技術想要拿來賣錢,卻發現阿里出的都是免費的。
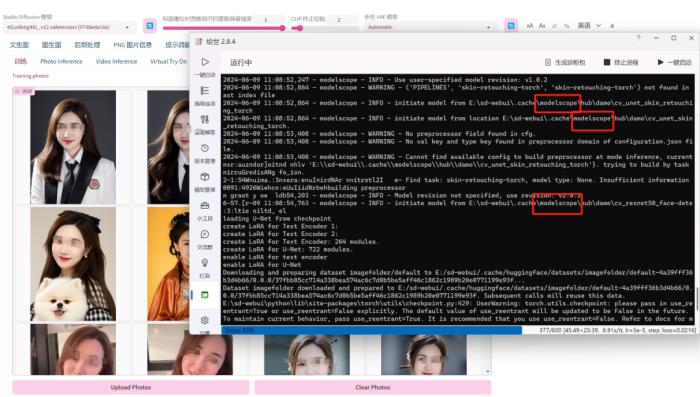
比如星空正在用EasyPhoto開源組件(EasyPhoto團隊也是阿里注資的)幫朋友訓練的AI繪畫模型,代碼里用到的modelscope是阿里的魔搭社區,阿里的很多AI領域的工作,已經成為開源界的標準之一。魔搭社區也是國內最活躍的AI開源社區,大部分開源模型都能在這里交流。
正在用ChatGLM開源模型做財經數據訓練的星空君表示,之前的工作白費了,后面切到Qwen2。
冷/熱知識,國內不能直接訪問HuggingFace.co,可以通過鏡像hf-mirror.com 訪問。
說起開源,感謝馬斯克,哦,不,馬云開源!
原文標題:斯坦福團隊抄襲國產AI開源模型
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
