

 新火種
2023-11-28
新火種
2023-11-28 


卷積神經網絡與Transformer結合,東南大學提出視頻幀合成新架構
研究者表示,這是卷積神經網絡與 Transformer 首度結合用于視頻幀合成。深度卷積神經網絡(CNN)是功能非常強大的模型,在一些困難的計算機視覺任務上性能也很卓越。盡管卷積神經網絡只要有大量已標記的訓練樣本就能夠執行,但是由于物體的變形與移動、場景照明變化以及視頻序列中攝像頭位置的變化,卷積神經網絡在視頻幀合成方面的表現并不出色。近日,來自東南大學的研究者提出了一種新型的端到端架構,稱為卷積 Transformer(ConvTransformer),用于視頻幀序列學習和視頻幀合成。ConvTransformer 的核心組件是文中所提出的注意力層,即學習視頻序列序列依賴性的多頭卷積自注意力。ConvTransformer 使用基于多頭卷積自注意力層的編碼器將輸入序列映射到特征圖序列,然后使用另一個包含多頭卷積自注意層的深度網絡從特征圖序列中對目標合成幀進行解碼。在實驗階段的未來幀推斷任務中,ConvTransformer 推斷出的未來幀質量媲美當前的 SOTA 算法。研究者稱這是 ConvTransformer 架構首次被提出,并應用于視頻幀合成。 論文地址:https://arxiv.org/abs/2011.10185卷積 Transformer 架構如圖 2 所示,ConvTransformer 的整體網絡 G_θG 有 5 個主要組件:特征嵌入模塊 F_θF、位置編碼模塊 P_θP、編碼器模塊 E_θE、查詢解碼器模塊 D_θD 和綜合前饋網絡 S_θS。
論文地址:https://arxiv.org/abs/2011.10185卷積 Transformer 架構如圖 2 所示,ConvTransformer 的整體網絡 G_θG 有 5 個主要組件:特征嵌入模塊 F_θF、位置編碼模塊 P_θP、編碼器模塊 E_θE、查詢解碼器模塊 D_θD 和綜合前饋網絡 S_θS。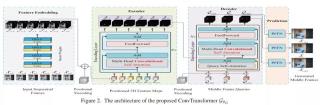 首先,特征嵌入模塊嵌入輸入的視頻幀,然后生成表示性特征圖。隨后,將每個幀提取出的特征圖與位置圖相加,用于位置識別。然后,將位置幀特征圖作為輸入傳遞給編碼器,以利用視頻序列中每一幀之間的長距離序列依賴性。得到編碼的高級特征圖之后,將高級特征圖和位置幀查詢同時傳遞到解碼器中,然后查詢幀和輸入視頻序列之間的序列依賴性將被解碼。最后,解碼的特征圖被饋入綜合前饋網絡(SFFN)以生成最終的中間插值幀或推斷幀。實驗在實驗部分,研究者通過與幾種 SOTA 方法進行比較來評估所提出的 ConvTransformer。最后該研究還進行了控制變量實驗,以驗證 ConvTransformer 中每個組件的優勢和有效性。為了創建視頻幀序列的訓練集,該研究利用來自 Vimeo90K 數據集的幀序列,該數據集是用于視頻幀合成的新建高質量數據集,另一方面,該研究還利用其他幾個廣泛使用的基準進行測試,包括 UCF101、Sintel、REDS、HMDB 和 Adobe240fps。與現有 SOTA 方法的對比研究者將經過訓練的 ConvTransformer 在幾個公共基準上與 SOTA 視頻插幀和視頻幀推斷算法進行比較,包括 DVF、MCNet、SepConv、CyclicGen、DAIN 和 BMBC。表 1 和表 2 分別說明了幾種算法在視頻插幀和未來幀推斷方面的定量比較結果。
首先,特征嵌入模塊嵌入輸入的視頻幀,然后生成表示性特征圖。隨后,將每個幀提取出的特征圖與位置圖相加,用于位置識別。然后,將位置幀特征圖作為輸入傳遞給編碼器,以利用視頻序列中每一幀之間的長距離序列依賴性。得到編碼的高級特征圖之后,將高級特征圖和位置幀查詢同時傳遞到解碼器中,然后查詢幀和輸入視頻序列之間的序列依賴性將被解碼。最后,解碼的特征圖被饋入綜合前饋網絡(SFFN)以生成最終的中間插值幀或推斷幀。實驗在實驗部分,研究者通過與幾種 SOTA 方法進行比較來評估所提出的 ConvTransformer。最后該研究還進行了控制變量實驗,以驗證 ConvTransformer 中每個組件的優勢和有效性。為了創建視頻幀序列的訓練集,該研究利用來自 Vimeo90K 數據集的幀序列,該數據集是用于視頻幀合成的新建高質量數據集,另一方面,該研究還利用其他幾個廣泛使用的基準進行測試,包括 UCF101、Sintel、REDS、HMDB 和 Adobe240fps。與現有 SOTA 方法的對比研究者將經過訓練的 ConvTransformer 在幾個公共基準上與 SOTA 視頻插幀和視頻幀推斷算法進行比較,包括 DVF、MCNet、SepConv、CyclicGen、DAIN 和 BMBC。表 1 和表 2 分別說明了幾種算法在視頻插幀和未來幀推斷方面的定量比較結果。
 此外,帶有縮放細節的合成圖像視覺比較結果如圖 1 和圖 3 所示。
此外,帶有縮放細節的合成圖像視覺比較結果如圖 1 和圖 3 所示。 圖 1:視頻幀推斷示例,上面是推斷結果,中間是放大的局部細節,底部是根據實際情況計算出的遮擋圖。
圖 1:視頻幀推斷示例,上面是推斷結果,中間是放大的局部細節,底部是根據實際情況計算出的遮擋圖。 圖 3:ConvTransformer 與其他視頻插幀 SOTA 方法(DVF、SepConv、DAIN、CyclicGen、BMBC)的可視化比較結果。
圖 3:ConvTransformer 與其他視頻插幀 SOTA 方法(DVF、SepConv、DAIN、CyclicGen、BMBC)的可視化比較結果。
選自arXiv作者:Zhouyong Liu 等機器之心編譯機器之心編輯部
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
