

 新火種
2023-10-28
新火種
2023-10-28 


大視覺(jué)語(yǔ)言模型基準(zhǔn)數(shù)據(jù)集ReForm-Eval:新瓶裝舊酒,給舊有的基準(zhǔn)數(shù)據(jù)集換個(gè)形式就能用來(lái)評(píng)估新的大視覺(jué)語(yǔ)言模型
概要
復(fù)旦DISC實(shí)驗(yàn)室推出了ReForm-Eval,一個(gè)用于綜合評(píng)估大視覺(jué)語(yǔ)言模型的基準(zhǔn)數(shù)據(jù)集。ReForm-Eval通過(guò)對(duì)已有的、不同任務(wù)形式的多模態(tài)基準(zhǔn)數(shù)據(jù)集進(jìn)行重構(gòu),構(gòu)建了一個(gè)具有統(tǒng)一且適用于大模型評(píng)測(cè)形式的基準(zhǔn)數(shù)據(jù)集。所構(gòu)建的ReForm-Eval具有如下特點(diǎn):
構(gòu)建了橫跨8個(gè)評(píng)估維度,并為每個(gè)維度提供足量的評(píng)測(cè)數(shù)據(jù)(平均每個(gè)維度4000余條);具有統(tǒng)一的評(píng)測(cè)問(wèn)題形式(包括單選題和文本生成問(wèn)題);方便易用,評(píng)測(cè)方法可靠高效,且無(wú)需依賴ChatGPT等外部服務(wù);高效地利用了現(xiàn)存的數(shù)據(jù)資源,無(wú)需額外的人工標(biāo)注,并且可以進(jìn)一步拓展到更多數(shù)據(jù)集上。我們的基準(zhǔn)數(shù)據(jù)集與評(píng)估框架已經(jīng)開(kāi)源,具體使用可以參考本推送第4節(jié)。第1節(jié)介紹了ReForm-Eval的構(gòu)建動(dòng)機(jī);第2節(jié)介紹了ReForm-Eval的構(gòu)建、評(píng)估方法;第3節(jié)介紹了我們基于ReForm-Eval進(jìn)行的定量分析得到的初步發(fā)現(xiàn);請(qǐng)感興趣的讀者閱讀,本文未盡之處請(qǐng)參閱我們的論文。
論文鏈接:https://arxiv.org/abs/2310.02569
作者信息:
 01引言
01引言
構(gòu)建開(kāi)源的類GPT-4的“大視覺(jué)語(yǔ)言模型”是最近多模態(tài)領(lǐng)域的熱潮。目前的大模型,包括BLIP-2,MiniGPT4,LLaVA,Lynx等等,已經(jīng)展現(xiàn)了令人驚喜的能力。這些模型可以回答圖片相關(guān)的問(wèn)題,做OCR,理解網(wǎng)上的梗圖,但是也會(huì)因?yàn)榛糜X(jué)(object hallucination)胡言亂語(yǔ)。
我們不禁好奇,那么這些模型究竟靠譜嗎,哪個(gè)模型更好呢?然而目前卻很少有定量的分析來(lái)評(píng)估和對(duì)比這些大模型,究其原因在于目前幾乎沒(méi)有適合評(píng)估大視覺(jué)語(yǔ)言模型的基準(zhǔn)數(shù)據(jù)集。
那為什么之前的多模態(tài)數(shù)據(jù)集無(wú)法拿來(lái)評(píng)估新一代的模型呢?可以跟著我們?cè)趫D1上半部分中一探究竟:
(1)首先看左上部分,目前多數(shù)的基準(zhǔn)數(shù)據(jù)集都是為特定任務(wù)設(shè)計(jì)的,進(jìn)一步就要求特定的輸入-輸出形式來(lái)輔助完成模型的評(píng)估,比如常用的問(wèn)答數(shù)據(jù)集VQA 2就要求詞/短語(yǔ)級(jí)別的簡(jiǎn)短輸出;視覺(jué)蘊(yùn)含任務(wù)則是“蘊(yùn)含、矛盾、中立”關(guān)系的三分類任務(wù);物體計(jì)數(shù)任務(wù)則只給出了數(shù)字形式的標(biāo)簽。
(2)然而以LLM為基座的大視覺(jué)語(yǔ)言模型非常靈活,傾向于輸出完整且詳細(xì)的句子(右上部分),對(duì)于第一個(gè)問(wèn)題,雖然輸出包括了正確答案,但是VQA v2要求答案完全一致(EM,exactly match);對(duì)于第二個(gè)問(wèn)題,模型的理解正確,卻沒(méi)有用特定的詞進(jìn)行表達(dá);對(duì)于第三個(gè)問(wèn)題,模型錯(cuò)誤輸出了信息,但是數(shù)字部分卻正好蒙對(duì)。
總的來(lái)說(shuō),舊有的基準(zhǔn)數(shù)據(jù)集里任務(wù)特定的形式,與新一代的大模型的自由形式的文本輸出存在著差異,但這是否意味著我們必須構(gòu)建新的基準(zhǔn)數(shù)據(jù)集來(lái)評(píng)估模型呢?
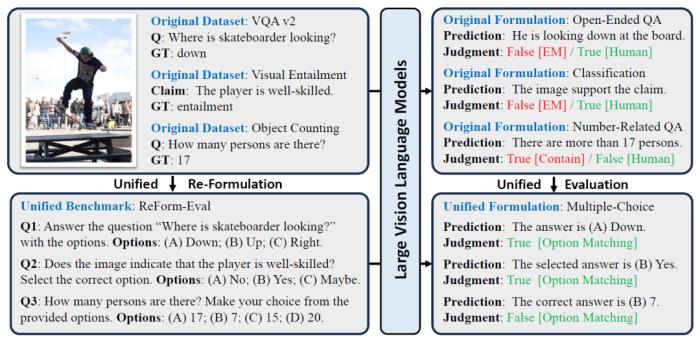
圖1:舊有基準(zhǔn)數(shù)據(jù)集和ReForm-Eval的區(qū)別。中括號(hào)內(nèi)表示評(píng)估方法,紅色、綠色分別代表錯(cuò)誤和正確的評(píng)估結(jié)果
我們的答案是否定的,既然現(xiàn)在的大模型無(wú)法適應(yīng)于舊的基準(zhǔn)數(shù)據(jù)集,那么為什么不把舊的數(shù)據(jù)集重構(gòu)成適合大模型評(píng)估的問(wèn)題形式呢。參考文本LLM的評(píng)估基準(zhǔn)中常用的問(wèn)題形式,我們主要考慮了兩種形式:文本生成問(wèn)題和單選題,前者則主要應(yīng)用于OCR、圖片描述這樣嚴(yán)格需求文本生成的場(chǎng)景,后者則適用于重構(gòu)其余的數(shù)據(jù)集。圖1下半部分展示了幾個(gè)重構(gòu)成單選題的例子,進(jìn)一步可以看出統(tǒng)一化的問(wèn)題形式也方便進(jìn)行統(tǒng)一、公平的評(píng)估。
基于重構(gòu)的方法下,我們推出了一個(gè)統(tǒng)一化的基準(zhǔn)數(shù)據(jù)集,ReForm-Eval。通過(guò)高效的利用現(xiàn)有的數(shù)據(jù)集資源,不需要額外的人工標(biāo)注,就能在多種能力維度都提供足量的評(píng)估數(shù)據(jù)。
02 ReForm-Eval介紹
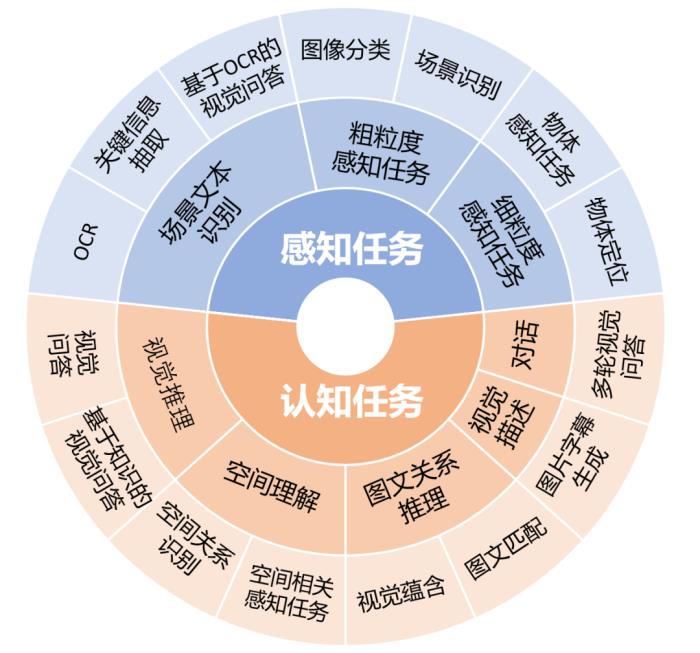
圖2:ReForm-Eval中的評(píng)估維度和對(duì)應(yīng)的任務(wù)
評(píng)估維度與構(gòu)建方法
為了能解決用戶提出的多樣化問(wèn)題,LVLM需要具有多樣化的能力。ReForm-Eval為了能對(duì)模型進(jìn)行綜合的評(píng)估,參考圖2,我們考慮了2大類,8小類的能力維度,每個(gè)能力維度下通過(guò)不同任務(wù)進(jìn)行評(píng)估,對(duì)于每個(gè)任務(wù),我們重構(gòu)了該任務(wù)下的多個(gè)數(shù)據(jù)集作為評(píng)測(cè)的數(shù)據(jù)。
雖然任務(wù)多樣,但是ReForm-Eval將對(duì)應(yīng)的數(shù)據(jù)重構(gòu)成了統(tǒng)一的問(wèn)題形式:
特定場(chǎng)景下文本生成任務(wù):a. OCR類任務(wù):用于評(píng)估場(chǎng)景文本識(shí)別能力,要求模型檢測(cè)出圖片中完全一致的目標(biāo)詞;b. 描述任務(wù):要求模型對(duì)視覺(jué)內(nèi)容進(jìn)行簡(jiǎn)短的描述單選題:利用樣本的正確答案標(biāo)簽作為正確選項(xiàng),我們采取不同方法來(lái)根據(jù)原有基準(zhǔn)數(shù)據(jù)集的形式來(lái)高效地構(gòu)建負(fù)選項(xiàng):
a. 分類任務(wù):如ImageNet,我們通過(guò)WordNet等方式構(gòu)建了候選類別間的關(guān)系,并基于此選擇與樣本標(biāo)簽相近的類別作為負(fù)選項(xiàng),若分類類別較少,則使用所有的類別作為選項(xiàng);
b. 開(kāi)放問(wèn)答任務(wù):如VQA 2.0,因?yàn)樵袛?shù)據(jù)集中常出現(xiàn)的答案可能與正確答案相關(guān)性較低,我們通過(guò)ChatGPT的幫助從問(wèn)題+正確答案里產(chǎn)生相關(guān)卻不等價(jià)的負(fù)選項(xiàng);
c. 其余特定形式的任務(wù):主要通過(guò)適合該任務(wù)需求的策略進(jìn)行負(fù)選項(xiàng)構(gòu)建,比如圖文匹配中的負(fù)選項(xiàng)來(lái)自數(shù)據(jù)集中用于描述其他圖片的文本,并根據(jù)與正確答案的相似度進(jìn)行排序選取困難的負(fù)選項(xiàng);
每個(gè)任務(wù)相關(guān)的數(shù)據(jù)集和具體構(gòu)建細(xì)節(jié)請(qǐng)參見(jiàn)我們的論文。
評(píng)估方法
ReForm-Eval中統(tǒng)一的問(wèn)題形式使得我們可以通過(guò)統(tǒng)一的評(píng)估方法,來(lái)對(duì)來(lái)自數(shù)據(jù)集的不同樣本上模型的輸出進(jìn)行一致的評(píng)估。
1. 對(duì)于文本生成任務(wù)的評(píng)估:我們根據(jù)具體的場(chǎng)景設(shè)計(jì)了不同的評(píng)估方法.
a. OCR任務(wù):
評(píng)估指標(biāo):詞級(jí)別的準(zhǔn)確率(圖片中的正確詞完整出現(xiàn)在模型輸出文本中的比例)評(píng)估方法:自由式文本生成,通過(guò)設(shè)計(jì)prompt引導(dǎo)模型檢測(cè)目標(biāo)文本;b. 視覺(jué)描述任務(wù):
評(píng)估指標(biāo):CIDEr評(píng)估方法:自由式文本生成,通過(guò)設(shè)計(jì)prompt要求簡(jiǎn)短的輸出,并額外基于對(duì)應(yīng)數(shù)據(jù)集的特點(diǎn)限制模型生成文本最大長(zhǎng)度2. 對(duì)于單選題的評(píng)估:
評(píng)估指標(biāo):準(zhǔn)確率,檢測(cè)模型輸出中的選項(xiàng)標(biāo)記,比如“(A)”來(lái)判斷模型的輸出類別評(píng)估方法:我們發(fā)現(xiàn)很多模型無(wú)法遵循單選題的指令,無(wú)法正確輸出特定格式的選項(xiàng),我們通過(guò)兩種方式進(jìn)行輔助評(píng)估:a. 黑盒方法(Generation Evaluation):通過(guò)僅文本的in-context sample來(lái)引導(dǎo)模型按期望的格式輸出,例子如下

其中紅色部分為提供的in-context sample,需要注意該樣本不提供圖片相關(guān)的信息,僅提供輸出結(jié)構(gòu)的引導(dǎo),實(shí)驗(yàn)過(guò)程中我們發(fā)現(xiàn)該策略非常有效,能引導(dǎo)模型在多數(shù)情況下輸出期望的格式
b. 白盒方法 (Likelihood Evaluation):直接計(jì)算模型在給定圖片、問(wèn) 題下對(duì)于不同選項(xiàng)的生成概率,選擇最高的作為模型的選擇
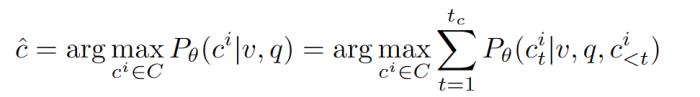
其中v,q,c分別為圖片,問(wèn)題和候選答案,P是目標(biāo)大模型預(yù)測(cè)的生成概率(自回歸式)。
3. 考慮穩(wěn)定性的評(píng)估方法:因?yàn)榇竽P蛯?duì)于輸入的文本非常敏感,所以ReForm-Eval考慮了評(píng)估中的不穩(wěn)定性,并進(jìn)行了穩(wěn)定性的度量
a. 重復(fù)測(cè)試:對(duì)于同一個(gè)任務(wù),ReForm-Eval提供了不同的問(wèn)題模板,對(duì)于每個(gè)樣本,將會(huì)進(jìn)行N次測(cè)試,每次使用不同的模板,如果是選擇題還會(huì)打亂選項(xiàng)的順序,使用不同的選項(xiàng)記號(hào),取多次測(cè)試的平均值作為正確率;
b. 不穩(wěn)定性度量:對(duì)于單選題,取N次實(shí)驗(yàn)中對(duì)于預(yù)測(cè)答案分布的熵作為不穩(wěn)定性的度量;對(duì)于文本生成任務(wù),因?yàn)闊o(wú)法度量輸出的分布,所以無(wú)法直接進(jìn)行度量。
03 定量分析與發(fā)現(xiàn)
我們?cè)u(píng)估了包括BLIP-2,LLaVA,MiniGPT-4,Lynx等等一系列13個(gè)方法訓(xùn)練得到的16個(gè)模型,并進(jìn)行了相關(guān)的分析,具體的表現(xiàn)與分析請(qǐng)參考我們的論文,以下為讀者總結(jié)了一些我們初步的發(fā)現(xiàn):

1. 對(duì)于基座模型的選擇(Figure 3):
a. 對(duì)于語(yǔ)言模型的選擇,需要考慮選擇本身具有一定指令遵循能力的基座,如FlanT5,Vicuna,LLaMA2-Chat
b. 對(duì)于視覺(jué)編碼器的選擇,基于CLIP,EVA-CLIP的ViT是普遍且較優(yōu)的選擇,越大的ViT也能為大視覺(jué)語(yǔ)言模型提供更好的視覺(jué)表示,進(jìn)一步需要根據(jù)不同的視覺(jué)模型選擇一個(gè)合適的連接模塊(如q-former,linear等);
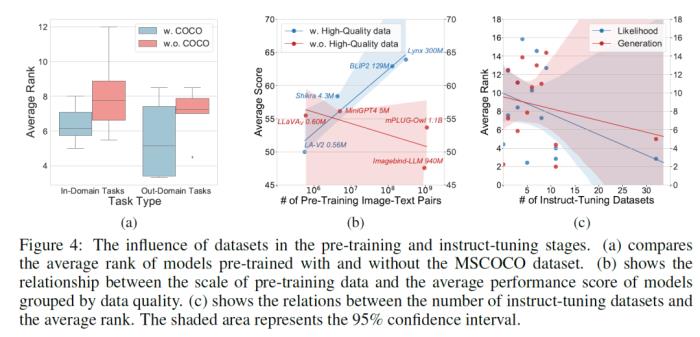
2. 訓(xùn)練數(shù)據(jù)方面(Figure 4):
a. 預(yù)訓(xùn)練數(shù)據(jù):質(zhì)量是非常重要的,表現(xiàn)好的LVLM普遍使用高質(zhì)量的人工標(biāo)注數(shù)據(jù)集COCO;如果需要在數(shù)據(jù)數(shù)量的進(jìn)一步擴(kuò)展,直接使用質(zhì)量較低的LAION效果并不好,使用BLIP中重新為圖片生成的字幕(BLIPCapFilt數(shù)據(jù)集)會(huì)是更有效率的選擇,這很可能是BLIP-2,Lynx,BLIVA成功的原因;
b. 指令微調(diào)數(shù)據(jù)集的豐富程度是最重要的,指令微調(diào)的數(shù)據(jù)集數(shù)量越多,模型的泛化能力和表現(xiàn)越強(qiáng),然而目前很多模型都只在有限的數(shù)據(jù)集上進(jìn)行了指令微調(diào)。
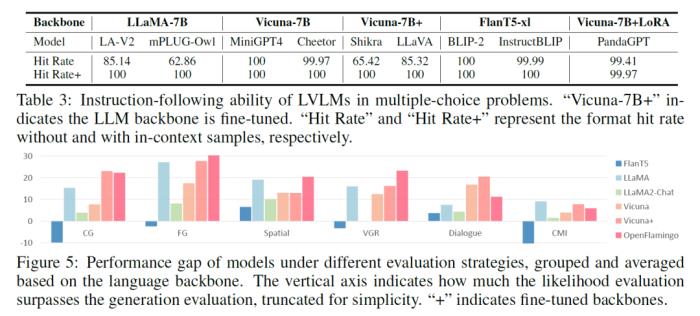
3. 指令遵循能力方面(Table 3 和 Figure 5):
a. 目前的LVLMs指令遵循能力有限,但通過(guò)黑盒方法里的in-context樣本能有效地提供結(jié)構(gòu)信息,引導(dǎo)模型以期望的形式進(jìn)行輸出,是當(dāng)下幫助完成LVLM評(píng)估的有效解決方案;
b. 指令遵循能力主要與模型使用的語(yǔ)言基座相關(guān),基于FlanT5,Vicuna,LLaMA2-Chat的模型遵循能力會(huì)比基于llama的模型較好;
c.與此同時(shí),全參微調(diào)語(yǔ)言基座反而會(huì)損害模型的這方面能力(LoRA微調(diào)則不會(huì));
d. 很多模型,比如BLIVA,Lynx只有在白盒測(cè)試方法下才體現(xiàn)出其有效性。說(shuō)明雖然黑盒方法下很多模型可以成功輸出選項(xiàng),但是模型因?yàn)閷?duì)與選擇題理解不夠,無(wú)法將內(nèi)部的知識(shí)輸出到文本中,需要白盒方法作為額外的輔助;
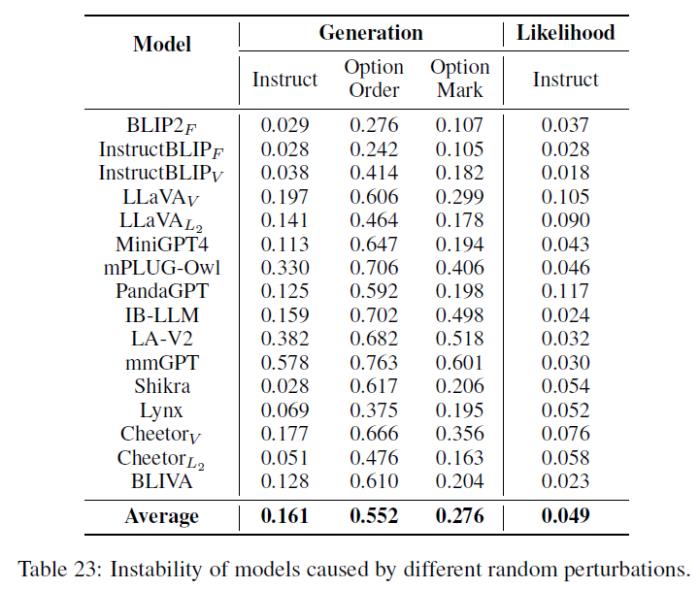
4. 模型都存在一定的不穩(wěn)定性(Table 23):
a. 對(duì)于輸入的prompt中較小的改變敏感,尤其是選項(xiàng)的順序,說(shuō)明整體上模型對(duì)于選擇題指令的理解有限;
b. 不同模型存在一定程度的對(duì)于選項(xiàng)的偏好(具體請(qǐng)參考論文中的Figure 10);
c. 基于白盒方法的度量的不穩(wěn)定性較小,因?yàn)槠渲苯釉u(píng)估了模型內(nèi)部的建模概率,且不需要生成時(shí)的采樣。
04使用ReForm-Eval
ReForm-Eval的數(shù)據(jù)以及評(píng)估框架已經(jīng)開(kāi)源,請(qǐng)參考https://github.com/FudanDISC/ReForm-Eval/。
這里我們給出關(guān)于具體使用方法的簡(jiǎn)單介紹,我們?yōu)橛脩籼峁┝藘煞N主要的使用方法:
1. 用戶將需要評(píng)測(cè)的模型遷移到ReForm-Eval適配的interface形式,基于ReFrom-Eval的框架進(jìn)行評(píng)測(cè):
a. 用戶可以參考GitHub中Create Your Own Model Interface一節(jié),通過(guò)將新的模型推理接口遷移到ReForm-Eval中的interface類形式,提供generation / likelihood evaluation的接口,并提供正確的讀取方式(用戶還需注意提供preprocessor方法,來(lái)將評(píng)測(cè)數(shù)據(jù)處理成模型需要的文本輸入形式);
b. 構(gòu)建完成后直接調(diào)用評(píng)估入口run_eval.py,修改其中的模型參數(shù)來(lái)調(diào)用新的模型接口即可完成對(duì)新模型的評(píng)估,ReForm-Eval支持多卡、半精度評(píng)測(cè),輸出的結(jié)果以及指標(biāo)會(huì)分別存儲(chǔ)在json,log文件中;
2. ReForm-Eval僅提供dataset和evaluate接口,用戶通過(guò)自己的模型接口進(jìn)行推理:
a. 通過(guò)ReForm-Eval提供的build.load_reform_dataset的接口獲取ReForm-Eval評(píng)測(cè)的數(shù)據(jù)集,讀取到的數(shù)據(jù)將以字典的形式提供給用戶(需要注意用戶需要自己實(shí)現(xiàn)或使用ReForm-Eval中的Preprocessor類功能來(lái)講字典里的結(jié)構(gòu)數(shù)據(jù)處理成模型需要的文本輸入形式);
b. 用戶使用自己的模型推理接口對(duì)讀取到的數(shù)據(jù)進(jìn)行推理,并將模型的預(yù)測(cè)寫(xiě)入“prediction”字段,將完整的結(jié)果輸出到j(luò)son文件中;
c. 使用ReForm-Eval中提供的評(píng)估接口run_loader_eval.py對(duì)上一步輸出的json文件進(jìn)行評(píng)估;
上述描述未盡之處,請(qǐng)參見(jiàn)GitHub中的Getting start部分的pipeline節(jié)。
用戶基于上述流程,通過(guò)修改data相關(guān)的參數(shù)就能完成對(duì)多個(gè)數(shù)據(jù)集的評(píng)估,所有61個(gè)數(shù)據(jù)集對(duì)應(yīng)的參數(shù)請(qǐng)參考GitHub中的Data Usage部分。
ReForm-Eval默認(rèn)通過(guò)huggingface來(lái)提供數(shù)據(jù)的自動(dòng)下載和讀取,不需要手動(dòng)進(jìn)行下載,如果在huggingface下載中遇到問(wèn)題,也可以通過(guò)手動(dòng)下載等方式來(lái)獲取數(shù)據(jù)。
如果您在使用過(guò)程中遇到困難,請(qǐng)務(wù)必通過(guò)Github Issue告知我們,或者郵件聯(lián)系yewang22@m.fudan.edu.cn。
*封面圖生成自DALL·E 3,提示詞“A tree grows from a withered seed in ice, in the new era, digital art”相關(guān)推薦



- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
