

 新火種
2023-10-28
新火種
2023-10-28 


第一批做「單細胞測序」的人,已經上云了

1980年,英國生物化學家Frederick Sanger與美國生物化學家Walter Gilbert建立了DNA測序技術并獲得諾貝爾化學獎。在此后的40年時間里,測序技術發生了多次革命。
北京大學的謝曉亮教授曾表示,2007年發生的新一代DNA測序儀的革命,使測序價格的下降速度比半導體工業的指數衰減還快。
“只要1000美元,一天之內就可以完成個人基因組測序,為治療和預防疾病提供個性化方案參考。”
2009年,單細胞測序技術首次問世。四年后,單細胞測序技術被Nature Methods評為年度技術。2015年,單細胞測序技術再度登上Science 轉化醫學封面。目前,單細胞測序的全球潛在科研市場體量已經達到130億美元。
單細胞測序到底有什么好?
簡單來說,世界上沒有兩片相同的葉子,對于多細胞生物來說,細胞與細胞之間是有差異的。傳統的研究方法在多細胞水平進行,因此,最終得到的信號值,其實是多個細胞的平均,丟失了異質性信息。
這就好比一場大合唱,比的是平均水平,其中有人渾水摸魚也不會被察覺。
從2018年起,單細胞基因測序技術就開始飛速發展。作為一項高效的醫療輔助手段,基因測序在預防出生缺陷、檢測遺傳性疾病、腫瘤用藥等領域提供了有效幫助。
但是,這項被寄予厚望的技術,如今卻撞在了一堵墻上。
沖破那堵"內存墻"
尋因生物做的,是單細胞基因測序。
這家成立于2018年、駐扎在北大醫療產業園的初創企業,在2022年1月獲得B輪融資,從去年開始商業化銷售。僅一年時間,已與100多家客戶建立科研合作關系,并在上海、廣州和成都同步設立地方實驗室。
來自尋因生物信息部門的張廣鑫說,“單細胞檢測技術沒有太大的客戶偏好性,只要是在單細胞水平上的需求對象,例如制藥公司、科研院所等都是我們的客戶。”
不過,客戶多也會帶來更多的挑戰。就像早些年雙11的高并發會讓淘寶app崩潰,同一時刻幾千萬人同時訪問,消費者可能就搶不到限時的優惠等。所以,尋因生物也面臨這個問題:超大數據量和分析復雜性,會導致任務并發度低、數據加載速率慢。
張廣鑫舉了一個例子,僅一個單細胞測序文件的大小可達100GB以上,而隨著一個單細胞項目包含的樣本量越來越多,細胞數據級別往往達數百GB甚至TB。
其次,單細胞數據的分析復雜,需要反復做數據讀取和參數調整,導致處理海量細胞樣本的分析任務,通常要數小時甚至數天才能完成。當樣品量上來,各個樣品之間又要做各種關聯或者是更復雜的計算,所以對算力的消耗量就會非常大。現在,逐漸又出了很多多組學的檢測,在普通單細胞的維度上又加了很多維度,對算力的需求會來到一個更高的水平。
如果說生信分析行業的本性如此,那么計算機系統架構本身的“阿喀琉斯之踵”才是問題的關鍵。
生物信息行業缺少一個覆蓋全程的開源軟件,通常一個生物計算項目需要多個軟件配合。因此,第一步的輸出往往是是第二步的輸入,中間存在大量的I/O(輸入/輸出)過程。
張廣鑫說到:“不夸張的說,12天中我們有10天都在I/O。而且,隨著單細胞檢測的成本逐漸降低,應用面越來越廣,生信數據將是指數級的增長。”
所以,生信分析的慣用操作是將樣本參數調低,或者僅運行一個比較大型的單細胞分析任務。但在測序任務多的情況下,多個單細胞分析項目只能排隊執行。
在張廣鑫看來,不考慮時間周期和算力投入的話,客戶需求都能滿足。但要考慮到單細胞的檢測和分析將會科研和藥物研發領域越來越普及,所需要分析的數據和維度都在增加的情況,生信行業不得不尋求更優化的計算架構。
他的顧慮,并不只是生信領域的問題,在AI行業也是如此。
此前,曾有AI行業的人士向坦言,“AI訓練未來的瓶頸不是算力,而是GPU內存。”做一個簡單的對比:2019年GPT-2所需的內存容量,已經是2012年的AlexNet的7倍以上。
隨著機器學習、計算機視覺、自然語言處理等AI應用的興起,處理器需要更加頻繁地對存儲器進行訪問與數據傳輸。傳統的馮諾依曼計算機體系架構依賴總線進行存儲器與處理器之間數據傳輸,在面對這類數據密集型應用時,往往難以兼顧低延時與高能效。
這一數據傳輸瓶頸現象常被描述為“內存墻”和“功耗墻”。以尋因生物為代表的單細胞領域就像是一個武林高手,需要一個更好的借力點,以施展輕功。
問題在三年前得到轉機。2019年,尋因生物與阿里云開展了合作,前者曾是阿里云ecs.g5、g6、g7三代產品的用戶。阿里云彈性計算產品總監王志坤對表示,"企業客戶最關心的永遠不是誰跑得最快、誰擁有最極致的產品,他們關心的是性能、成本、可靠性之間的平衡。"
在王志坤看來,如何判斷一家企業是否適合使用“大內存云”,有兩點可作為衡量標準:
一,企業的數據量是不是足夠大。由于數據量大,IO是否是主要瓶頸;
二,具體任務的計算量是不是大。由于計算量大,運行時間是否耗時。
同樣,客戶在選擇大內存云之前也要先有建立一個CPU、內存以及IO的預估模型。但企業在預估之前,阿里云平臺上涵蓋了類似的行業方案,并已經經過其他客戶POC驗證,使得企業方案互通,行業共建成為可能。
王志坤稱,這種能力是阿里云作為云廠商的獨特基因,“我們更擅長的是互聯網平臺打法,將海量的業務場景融合起來,從而加速整個行業的研發效率。”
談及上云的理由,張廣鑫表示, “將企業本地自建機房變為使用阿里云的計算池,不僅能夠保證整體算力,而且付費模式多元,用多少拿多少,不會浪費;二是阿里云多年深耕生物信息行業,已形成多種服務方案和客戶資源,能夠為上下游生物科技企業的互聯互通提供更多支持,這是很多生物公司所看重的。”
正是有過多代產品的使用,張廣鑫對“上云”的評價直接了當:算得快、成本低。
經過測算,尋因生物的單細胞基因測序,數據加載和導出性能從1000秒縮至2.5秒;單任務的樣本規模是原來的2倍。在運行時間和單任務的運行時間幾乎差不多的情況下,測序任務的并發運行數由原來的1個提升到了5個,任務處理效率提升了5倍之多。
從現在的結果來看,尋因生物找對人了。
一場合力締造的"大內存云"時代
沒有一次的變革不是從最直接的需求而來。
醫療健康產業由于其技術要求高、數字化水平低等特性,成為數字化最重要的應用落地場景之一。從面向藥企的藥品數字化全流程追溯,到面向醫院的以電子病歷三級醫院全覆蓋為首的醫療信息化改革,都折射出真實存在的行業痛點。
因此,尋因生物這樣的下游客戶對于“內存”的需求,也在一步步倒逼芯片商、ISV(獨立軟件開發商)以及在此之上的云服務提供商,不斷拿出新的解決之道。
對于沖破“內存墻”,各方如此心智統一,個中原因是它們對計算機基礎架構尋求“革命”的決心。事實上,發端于云主機時代的產品,在一定意義上是對傳統CPU和內存堆料所不滿的一次爆發。
數據分析對底層技術的需求是一個漫長的歷史演變過程。雖然近年來不少企業已有上云的趨勢,但過去的云主機,一直是缺啥補啥。舉個例子,過去所有云主機類的產品,比如2路服務器使用最多的是X86架構,但英特爾推出來的每一代內存插槽數是固定的,單條內存的容量也是固定的。
如果還會出現算力和存儲難題,解決辦法是繼續Scale up(垂直擴展),將2路服務器升級為4路、甚至8路,但是多CPU與內存之間的緩存一致性、主板復雜度等也會急劇上升。所以,各行業客戶要么選擇非常昂貴的大內存產品,要么是選擇小內存組成的集群型產品。
王志坤也坦言:“阿里云很早推出了超大內存的實例,但當時的成本確實很高。”長此以往,計算機基礎架構可謂是四個字:積重難返。直至,英特爾在2021年推出采用新介質的第二代英特爾傲騰持久內存200系列,一度迫于堆料的業內人士,開始求變。
英特爾相關負責人表示,2017年,隨著傲騰SSD(傲騰固態盤)的推出,我們知道這是真正的游戲改變者,具有DIMM接口的傲騰持久內存的誕生也為期不遠。但在當時,之所以能賦予大眾這種遠見,在于這款產品兌現了兩年前的承諾,正式推出了基于3D XPoint介質的的SSD產品。
2015年,英特爾打造了基于3D Xpoint存儲介質的傲騰技術,一舉改變了傳統的內存和存儲層級結構。通過縮小冷熱數據間的差距、減少IO瓶頸和解決數據延遲,使內存更靠近計算,為數據中心提供更高的靈活性和更多的價值。
而傲騰SSD的問世,無疑證實新介質做成了,而且極有可能是一個過渡型產品,將掀起內存產品的一次革命。
隨后的故事不斷描摹出新的劇本。
2019年4月,英特爾正式發布傲騰內存DIMM版本;2020年,英特爾發布傲騰持久內存100系列,成功完成大規模的商業化;2021年,英特爾發布第三代英特爾至強可擴展處理器(代號: Ice Lake) 及英特爾傲騰持久內存200系列, 生態系統更加壯大 。
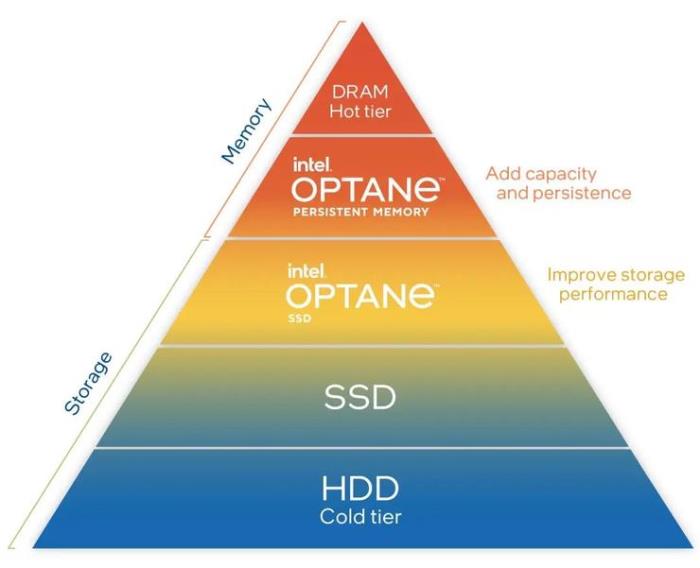
英特爾? 傲騰? 持久內存支持分層架構,從而實現高性能、大內存計算
2021年,阿里云基于第三代英特爾至強可擴展處理器和第二代英特爾傲騰持久內存200系列產品,開發了性能更加強大的不同規格實例:re7p、 r7p和 i4p,應用于更廣泛的場景。
尤其是i4p,它能夠提供性能極高的本地盤,相比于傳統NVMe SSD在十幾到二十微秒的延時水平,其延時可以縮短至170ns,非常適用于重IO型應用,能夠幫助此類應用突破性能上的瓶頸。
從目前的合作形式來看,尋因生物的單細胞測序分析任務,就部署在了基于第三代英特爾至強可擴展處理器 (代號: Ice Lake) 和第二代英特爾傲騰持久內存的阿里云i4p持久內存型實例上。
尋因生物的張廣鑫說到,“好的大內存云,是使用之后就感受不到它的存在,我只管專心做好我的業務。”
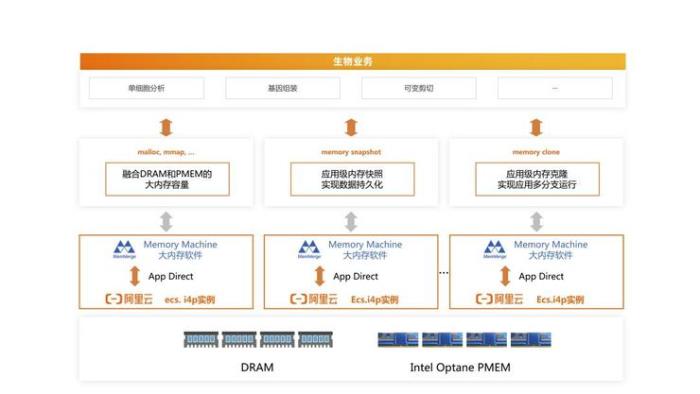
大內存云架構
其次,阿里云找到合作伙伴MemVerge。
MemVerge做什么?簡單來說,它推出的Memory Machine是內存虛擬化軟件,相當于存儲的“操作系統”。
MemVerge? 的Memory Machine? 軟件是業界第一款虛擬化內存硬件的軟件,用于對容量、性能、可用性和移動性進行精細化的資源調配。在透明內存服務的基礎上,Memory Machine還提供了另一個行業第一的技術——ZeroIO?內存快照,該技術可以在幾秒鐘內封裝數TB的應用程序狀態,并以內存速度實現數據管理。
MemVerge CEO范承工對表示,“從2017年3月,英特爾推出傲騰SSD。某種程度上,這是一個新的內存存儲架構。要做成‘大內存’架構的話,除了硬件,還需要有相應的軟件來產生。這就是我們成立的初衷。”
他認為,每次一種新硬件的使用,都必須開發一個新的軟件堆棧,使應用程序能夠充分利用新硬件的優點。
通過阿里云的計算巢模式(即云廠商開放給企業應用服務商和其客戶的服務管理PaaS平臺),阿里云讓后者的Memory Machine大內存虛擬化軟件與云平臺的標準化集成,加速軟件交付部署并標準化運維管理,大幅提升了業務效率。
范承工向表示,“基礎IT行業會逐漸意識到‘大內存’技術對于生產力、計算速度的重要性。同時,我們通過內存快照和應用膠囊的技術,可以使尋因生物不需要經歷太多的IO。三家合力,來給客戶的生物分析工作提供價值。”
對于MemVerge的作用,阿里云也給出了肯定的回答。
王志坤坦言,阿里云不太可能構建起一個端到端、無縫的全場景覆蓋能力,服務行業客戶需要MemVerge這樣ISV(獨立軟件開發商)進來。
“業界還存在鴻溝,而這種鴻溝需要像MemVerge這樣創新的技術服務提供商來填補。通過他們的技術創新,來使用好基于阿里云和英特爾傲騰持久內存的能力,同時又能滿足面向垂直行業、面向垂直擴展領域的大內存場景。”
最后,是聯動阿里云內部生態。
縱觀阿里云的架構,除了有自主研發“神龍”云服務器架構之外,還有“飛天”云操作系統、“盤古”存儲平臺、“洛神”網絡平臺、PolarDB云原生數據庫等等,構成了統一的云平臺,讓阿里云具備了從虛擬化層到操作系統內核層全鏈路的整合與調優能力。這些能力最終使得阿里云彈性計算團隊對持久內存的產品化研發變得更加敏捷。
對于基礎IT市場的演變趨勢,范承工坦言,“市場仍然屬于早期。但在未來2-3年里,尤其是隨著英特爾CXL(Compute EXpress Link)的完善,生態會變得更加完整。”
對于未來,范承工也非常期待,“阿里云是中國云計算的領頭羊。所以,我們之后會繼續和阿里云、英特爾合作,一方面共同培養‘大內存’市場里的客戶,包括生物信息、EDA仿真、金融等其他行業;另一方面,我們在技術上也會有更多的整合和合作,讓聯合方案有更好的用戶體驗。”
成為“東數西算”戰略的關鍵一環
21世紀是生命科學的世紀。不管是從經濟成本,還是業務開展的角度考量,更多的廠商越來越往云端去走,把數據處理的部分交給專業廠商去做。
2021年7月的新一輪疫情,湖南省將流調任務交給了長沙超算中心,通過強大的HPC把時間縮短至1.4秒。但是,如果用戶有大數據相關業務,那么部署到傳統超算中心上將帶來很大的難度,因為數據移動既耗時又耗力。這也是E-HPC誕生的初衷。
早在2017年,阿里云就發布了中國首個公共云上的彈性高性能計算平臺E-HPC。彼時的“云上超算中心”,一亮相吸引了公眾的目光,可一鍵部署彈性伸縮的高性能計算集群環境,幫助科研院所和企業處理大規模科學計算問題。
張廣鑫表示,面向生物產業,阿里云能提供一些調度資源的方案,例如E-HPC的解決方案可以幫我們去簡化編寫流程、監控任務投遞,以及任務運算的過程。
他談到了后續尋因生物對阿里云的一些使用規劃:
從算得快的層面來看,用一些更有彈性的東西,例如業務量來了之后,可以很快出來很多節點,并發去進行計算。尋因生物還要對集群或阿里云平臺進行一些精細化的管理。因此,在E-HPC層面上,尋因生物仍有比較足的需求。
從省錢的角度看,阿里云的服務有不同定價,要考慮數據保存的性能和周期,再進行精細化的調整。后面尋因也會基于阿里云開發出直接向用戶提供服務的單細胞分析平臺,賦予科研用戶和藥物研發用戶分析單細胞數據的能力。
從大的社會背景下看,數據和算力成為新一輪的新焦點,也給云計算廠商們帶來更多的時代命題。繼“南水北調”、“西電東送”、“西氣東輸”等工程之后,今年2月,“東數西算”工程啟動,其本質就是通過構建數據中心、云計算、大數據一體化,形成一種新型算力網絡體系。
國家發展改革委等部門聯合印發通知,同意在京津冀、長三角、粵港澳大灣區、成渝、內蒙古、貴州、甘肅、寧夏等8地啟動建設國家算力樞紐節點,并基于樞紐規劃了10個國家數據中心集群。
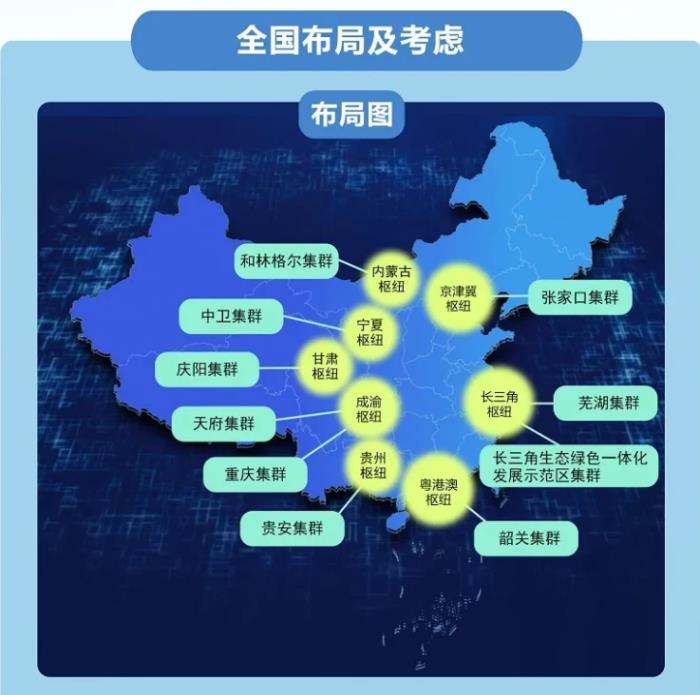
王志坤對表示,“阿里云早期的機房建設是租用的形式。從六年前起,阿里云開始規劃自建大規模的基地型數據中心,與東數西算里面幾大算力樞紐的方向是一致的。”
其中,服務京津冀地區的阿里云張北數據中心已于2016年9月投產,大力采用風電、光伏等綠色能源,宣化數據中心也在建設中;在內蒙古樞紐,烏蘭察布超級數據中于2020年6月開始提供云計算服務;在成渝樞紐,阿里云西部云計算中心及數據服務基地于2020年11月落戶成都。
更關鍵的是,東數西算的國家戰略工程,與云的模式十分吻合。因為,云計算的模式是據客戶的需求按量配比,計算和存儲更有彈性、安全。這與東數西算的跨區域數據調度和計算、數據中心適度聚集、集約發展,在性質上有天然的契合。
王志坤表示,“不管是我們底層的能力,還是云資源調度的能力,我們都有信心成為國家大戰略中的重要一環。”
Tags:
相關推薦


- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
