

 新火種
2023-09-15
新火種
2023-09-15 


深度學習也利用進化論!李飛飛談創建具身智能體,學動物進化法則
來源:twitter
編輯:LRS
【新智元導讀】今年早些時候斯坦福李飛飛教授等人的研究「深度進化強化學習」有了突破,首次證明了「鮑德溫效應」。最近李飛飛帶著研究團隊做客Bio Eats World訪談,AI智能體也可以很快學會動物的這種智能行為,但目前推動具身認知面臨很多挑戰。
新冠疫情的爆發讓我們感受到了生命是脆弱的,但也是強大的。如此神奇的生命究竟是怎么創造的,人類究竟能否再創造出具有智能的生命?
智能體/代理(Agents)是人工智能領域的一個主要研究課題,分為非具身智能和具身智能(embodied intelligence)。
今年2月,李飛飛和其他幾名學者提出了一個新的計算框架——深度進化強化學習——Deep Evolutionary Reinforcement Learning (DERL),基于該框架,具身智能體可以在多個復雜環境中執行多個任務。

6月,李飛飛的團隊受Bio Eats World邀請,介紹不斷發展的具身智能。
Bio eats world這個名字的意思是生物學正在吞噬世界。生物學正在脫離實驗室和診所,進入我們的日常生活。生物(我們對生命科學、醫療保健、技術和工業的交叉點的簡稱)如今正處于50年前計算機革命的邊緣: 即將以我們才剛剛開始認識的方式徹底改變我們的世界。通過與頂尖科學家、建筑商、企業家和領導者的對話,主持人 Lauren Richardson (以及安德森·霍羅威茨的團隊)探討了生物將如何從根本上改變我們的未來。簡而言之,生物正在吞噬世界。
本次演講人包括Vijay Pande,李飛飛,Surya Ganguli和Lauren Richardson。
在節目中,完整地介紹了從理論和邊緣哲學到應用哲學的全部內容。
具有具身智能的身體,或者說智能表現的物理形式,在塑造一個個體的思想和認知能力方面起著積極而重要的作用。例如,人類的智力不僅僅是我們大腦的功能,而是我們的大腦、我們的身體和我們生存的環境的組合。但是當涉及到人工智能(AI)的設計時,物理形式和環境通常不是等式的一部分。這是一種脫離實體的認知。
斯坦福大學人類中心人工智能研究所的李飛飛和Surya Ganguli,他們開發了一個被稱作“進化游樂場”的環境,探索人工智能中具身智能的發展及其與環境的關系,以及在計算機實驗中的學習應用。
他們與a16z 的普通合伙人 Vijay Pande 和主持人 Lauren Richardson 討論他們如何創建一套虛擬環境,在其中智能體通過模仿達爾文進化論的方方面面進化。
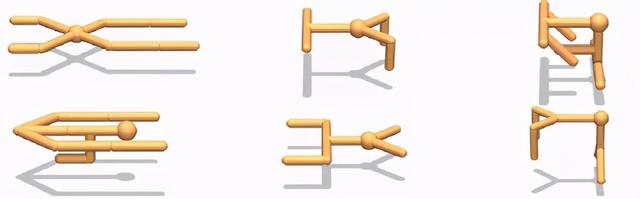
這些智能體,被稱為unimal,或者宇宙動物(universal animal),開始時是一個中心節點,每一代都可以增加或減少四肢并改變它們的物理形式的各種屬性,比如它們的關節有多靈活。就像在真實的進化中一樣,不同的形式是根據環境的特殊性而產生的,但真正令人興奮的是李飛飛、Surya 和同事們發現的關于智力編碼在其中一些形式中的東西,比如學習一項新奇任務的能力的增強。
下圖為環境中展示的unimal。

這就引出了節目中討論的應用部分。這些結果為我們如何設計能夠執行獨特任務的機器人提供了新的見解,也為我們理解像 GTP-3這樣的無實體人工智能模型可能存在的局限性提供了新的見解。
在李飛飛的論文中首次通過「形態學習」(morphological learning)證明了進化生物學中的「鮑德溫效應」。
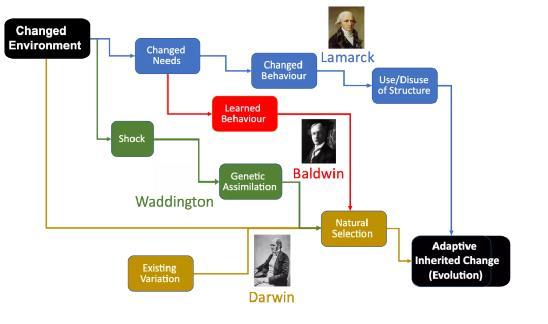
1953年,美國古生物學家George Gaylord Simpson創造了術語「鮑德溫效應」,其中提到了美國哲學家和心理學家JM Baldwin的1896年論文中進化的一個新的因素。
在進化生物學中,鮑德溫效應提出,在進化過程的早期世代一生中最初學會的行為將逐漸成為本能,甚至可能遺傳給后代。
在過去的6億年里,進化帶來了無數形態的美:從古老的兩側對稱的昆蟲到各種各樣的動物形態。

這些動物還表現出顯著的具身智能,利用進化學習復雜的任務。
具身認知的研究人員認為,AI智能體可以很快地學會這種智能行為,而且它們的形態也能很好地適應環境。
然而,人工智能領域更注重「非具身認知」,如語言、視覺或游戲。
當AI智能體能夠很好地適應環境時,它們就可以在各種復雜環境中學習控制性任務。然而,由于以下原因,創建這樣的智能體非常具有挑戰性。
這需要在大量潛在模式中進行搜索。通過終身學習評估一個智能體的適應性需要大量的計算時間。
因此,以往的研究要么是在極其有限的形態學搜索空間中使智能體實現進化,要么是在給定的人工設計形態學下尋找最優參數。
評估適應性的困難使得以前的研究避免了直接在原始感官觀察的基礎上學習自適應控制器;
學習使用少量參數(≤100)手動設計控制器; 學習預測一種形式的適應性;
模仿拉馬克進化而不是達爾文進化,直接跨代傳遞學習的信息。

深度進化強化學習框架(DERL)可以在環境,形態和控制這三種復雜維度同時擴展創建具身智能體的規模。
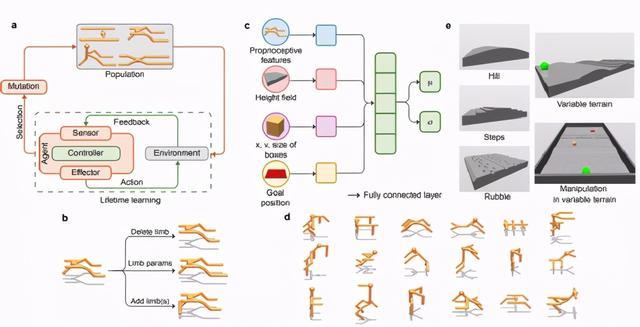
DERL為計算機模擬實驗中的大規模具身智能體創建活動打開了一扇門,這有助于獲得有關學習和進化如何協作以在環境復雜性,形態智能和控制的可學習性之間建立復雜關系的科學見解。
此外,DERL還減少了強化學習的樣本低效性的情況。智能體的創建不僅可以使用更少的數據,而且可以泛化和解決各種新任務。
DERL通過模仿達爾文進化論中錯綜復雜的代際進化過程來搜索形態空間,并通過終生神經學習的智能控制解決復雜任務來評估給定形態的速度和質量。

斯坦福大學教授,論文的作者李飛飛表示,「這項研究不僅提出了一種新的計算框架,即深度進化強化學習(DERL),而且通過形態學習首次證明了達爾文-鮑德溫效應。形態學習對于自然界中的動物進化至關重,現已在我們創建的 AI 智能體中展現」。
在這項研究中創建的具身智能體可以平地(FT),多變地形(VT)和多變地形的非抓握操作(MVT)中執行巡視(patrol)、點導航(point navigation)、避障(obstacle)、探索(exploration)、逃脫(escape)、爬坡(incline)、斜坡推箱子(push box incline)和控球(manipulate ball)等任務。
為了學習,每個智能體僅通過接收低級自我感知和外部感受觀察來感知世界,并通過由深度神經網絡的參數確定的隨機策略選擇其動作。
該隨機策略是通過近端的深度神經網絡的參數策略優化(PPO)學習得到。
通常,DERL允許研究人員在1152個CPU上進行大規模實驗,平均涉及10代進化,搜索和訓練4000種形態,每種形式有500萬智能體與環境的交互(即學習迭代)。
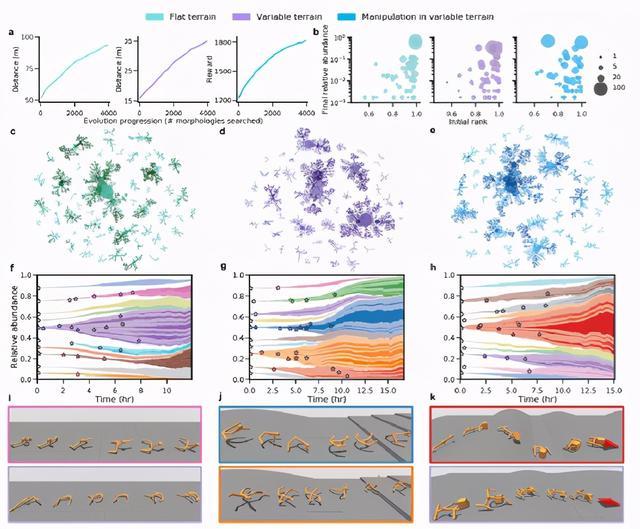
該研究可以在并行的異步競賽中訓練288種形態,因此在任何給定時刻,整個學習和演化過程都可以在16小時內完成。
可以理解為,這是迄今為止形態進化和RL的最大同時模擬。
為了克服過去形態學搜索空間表達能力的局限性,本研究引入了 Universal aniMAL(UNIMAL)設計空間。
本研究的基因型(genotype )是運動樹,它對應于通過電機驅動的鉸鏈連接的3D剛性零件的層次結構。
運動樹的節點由兩種類型的組件組成:代表智能體頭部的球體(樹的根)和代表肢體的圓柱體。
進化通過三種類型的變異算子無性繁殖:
1 通過增加或減少肢體來收縮或生長運動樹
2 改變現有肢體的物理特征,如長度和密度
3修改四肢之間關節的屬性,包括自由度、旋轉角度限制以及齒輪比
最重要的是,該研究只允許保持兩側對稱的成對變異,這是動物形體構型在進化過程中最古老的特征(起源于6億年前)。
一個關鍵的物理結果是,每個智能體的質心都位于矢狀面,從而減少了學習左右平衡所需要的控制程度。
盡管有這一限制,但該研究提出的形態設計空間極具表達力,包含大約1018種獨特的智能體形態,至少有10個肢體。
研究結果表明, 利用DERL證明了環境復雜性、形態智能和控制的可學習性之間的關系:
首先,環境復雜性促進了形態智能的進化,可用形態促進新任務學習的能力來量化。
其次,進化快速選擇學得更快的形態,從而使早期祖先一生中較晚學會的行為在其后代一生中較早表現出來
第三,實驗表明,通過物理上更穩定、能量效率更高的形態的進化,促進學習和控制,鮑德溫效應和形態智能的出現都有一個機理基礎。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
