城市、高速一體化,從車位到車位的全程自動(dòng)。
最近一段時(shí)間,隨著新車型和新技術(shù)的發(fā)布,智能駕駛再次成為人們熱議的話題。有的車企想要做減法,在發(fā)布活動(dòng)上表示「十個(gè)人有沒有一個(gè)人用輔助駕駛」,也有車企表示「新能源下半場(chǎng)一定是智能化與網(wǎng)聯(lián)化的,新形態(tài)的智能駕駛將會(huì)徹底改變?nèi)藗兂鲂械捏w驗(yàn)。」問題的核心在于「實(shí)用性」:全球范圍內(nèi),智能駕駛的架構(gòu)和形態(tài)經(jīng)歷了一輪又一輪迭代更新,從最早的高速領(lǐng)航輔助駕駛,到城市 NOA,再到覆蓋全域的智能駕駛。支撐智能駕駛的輸入端也經(jīng)歷了變革,從有圖到無圖,再到是否要做純視覺的方向之爭(zhēng)。新概念層出不窮,然而在很多人看來,智能駕駛這一路走來,似乎發(fā)展的速度在逐漸落后于我們的預(yù)期。2024 年 12 月底,這場(chǎng)大討論進(jìn)入了高潮。1 月 16 日,理想的 OTA7.0 正式版開啟了全量車主推送。隨著 OTA7.0 的全量推送,理想宣布,其 OneModel 端到端 + VLM 智駕系統(tǒng)已經(jīng)實(shí)現(xiàn)了「全場(chǎng)景端到端」能力。與之同時(shí)上線的還有行業(yè)首創(chuàng)的 AI 推理可視化能力,它首次將自動(dòng)駕駛過程中 AI 模型思考推理的過程可視化展現(xiàn)出來,讓我們第一次看到了 AI 的思考和執(zhí)行過程,因此也可以更加放心。同時(shí),理想也成為了國(guó)內(nèi)唯一、全球第二家將端到端技術(shù)應(yīng)用到城市、高速及環(huán)路 NOA 場(chǎng)景的車企。理想表示,自 OTA 5.0 采用 BEV 架構(gòu)并推出城市 NOA 后,理想內(nèi)部對(duì) AD Max 啟用獨(dú)立版本號(hào)進(jìn)行管理。過去的一年里,其共完成 12 次 AD Max 的重大更新。為了讓用戶更好地感知智能駕駛迭代,隨著 OTA7.0 升級(jí),AD Max 的內(nèi)部智能駕駛版本號(hào)將向用戶展示,智能駕駛版本升級(jí)為 AD Max V13.0。從車位到車位,覆蓋全場(chǎng)景AI 推理還能可視化理想的 OneModel 端到端智駕號(hào)稱擁有極強(qiáng)的覆蓋和適應(yīng)能力,風(fēng)格更加擬人化,駕駛習(xí)慣也更絲滑,它還支持全國(guó)的新開通高速、長(zhǎng)隧道、城市 / 高速切換點(diǎn)等道路的行駛,可以在大部分路段無降級(jí)不斷點(diǎn)地智駕通行。我們使用一輛理想 L7 Ultra 對(duì)最新的智駕版本進(jìn)行了測(cè)試。

據(jù)更新說明介紹,我們測(cè)試的智能駕駛 OTA 版本是在 800 萬 clips(視頻片段)基礎(chǔ)上迭代的,增加了導(dǎo)航變道的數(shù)據(jù)配比。首先吸引眼球的是中控屏上,理想在業(yè)內(nèi)首創(chuàng)的「AI 推理可視化」。它打開了 AI 模型的黑箱,對(duì)端到端 + VLM 模型系統(tǒng)的思考過程進(jìn)行了直接的展示,包括從物理世界輸入到?jīng)Q策結(jié)果輸出的整個(gè)過程,并在中控屏或副駕屏上實(shí)時(shí)顯示出來。

可以看到,這個(gè)可視化界面分為三個(gè)區(qū)域:

E2E(端到端模型)—— 其中顯示自車、其他車輛、道路車道線、軌跡線預(yù)測(cè)等信息。藍(lán)色軌跡線代表模型計(jì)算過程中判定的正確軌跡,灰色軌跡線則代表模型計(jì)算過程中判定的偏移軌跡。軌跡線計(jì)算共展示 10 個(gè)窗口,代表一種模型輸出結(jié)果,最終 AI 會(huì)選擇一條老司機(jī)認(rèn)為最正確的軌跡來執(zhí)行操作。第二個(gè)部分是 Attention(注意力系統(tǒng))—— 其中顯示系統(tǒng)對(duì)實(shí)時(shí)視頻流中的交通參與者行為和環(huán)境路況進(jìn)行評(píng)估,分析其類型、位置、速度、角度等屬性,并輔助端到端模型計(jì)算出最佳的行駛軌跡。其中會(huì)以熱力圖形式展示注意力系統(tǒng)的工作狀態(tài),其中顏色更暖(偏紅)的區(qū)域代表對(duì)智能駕駛決策影響更大的區(qū)域。第三個(gè)部分則是 VLM(視覺語言模型)—— 它展示了視覺語言模型的感知、推理和決策過程,像我們常見的大模型應(yīng)用一樣將車載攝像頭看到的交通情況用文字的形式加以解釋。當(dāng)識(shí)別到有對(duì)智能駕駛決策有影響的環(huán)境路況和交通規(guī)則變化時(shí),VLM 能夠及時(shí)感知信息,并做出合理的推理決策。據(jù)理想介紹說,對(duì)于端到端系統(tǒng)來說過于復(fù)雜的場(chǎng)景,會(huì)交由 VLM 進(jìn)行決策,比如丁字路口、公交車道限行、施工路段、避讓旁邊的大車等等。這樣的配置為智能駕駛加了一道保險(xiǎn)。通過 VLM 的識(shí)別,理想也實(shí)現(xiàn)了行業(yè)唯一的全國(guó)任意高速收費(fèi)站 ETC 閘機(jī)自主通行,再加上城市與高速一體化的架構(gòu),真正做到了全場(chǎng)景 100% 智能駕駛。更重要的是,現(xiàn)在你能看到 AI 是如何做出決策的。第一次打開智能駕駛還會(huì)有些緊張,過不了一會(huì)兒懸著的心就放了下來,人與車之間的疏離感也減少了。在北京城區(qū)內(nèi)行駛了一個(gè)上午,我們可以明顯地感受到,端到端智能駕駛系統(tǒng)與過去的智能駕駛相比體驗(yàn)截然不同。它的工作區(qū)域覆蓋面更廣,也更聰明。在通過匝道等大曲率彎道時(shí),AI 的操作已經(jīng)足夠穩(wěn)定。

智能駕駛系統(tǒng)在碰到前方慢車可以更早地變道,遇到大貨車也會(huì)向另一側(cè)稍微躲避,遇到加塞情況剎車也更加從容。

此前,理想的城市智能駕駛(6.0 版本及以前)是基于 BEV+OCC 和 Transformer 的業(yè)內(nèi)主流方案。在這樣的技術(shù)體系之上,很多車企開啟了部分城市的無圖 NOA,但這種智能駕駛的效果仍稱不上完美。新版本的端到端輔助駕駛則帶來了巨大的提升。它保留了激光雷達(dá)的數(shù)據(jù)輸入,保證了安全性的下限。另外,它不僅模型是端到端的,實(shí)現(xiàn)的駕駛體驗(yàn)也是「端到端」的 —— 解決了智能駕駛的最先和最后 100 米問題,能做到從家中車位到目的地車位的全程智能駕駛,順利通過停車場(chǎng)閘機(jī)、紅綠燈,合理避讓橫穿馬路的行人、電動(dòng)車,或是與其他車輛并線博弈。理想表示,未來兩年,當(dāng)訓(xùn)練數(shù)據(jù)量達(dá)到 2000 萬 Clips 時(shí),MPI(每次干預(yù)行駛的里程數(shù))有望達(dá)到 500 公里。當(dāng)然,目前的智能駕駛還是可能會(huì)碰到一些無法處理的情況,但在試了試端到端智能駕駛之后,我們至少可以肯定地說,真的不一樣。隨著這套技術(shù)的發(fā)展,或許用不了多久它就可以真正做到對(duì)老司機(jī)的一比一復(fù)刻。端到端 + VLM 大模型實(shí)現(xiàn)降維打擊為什么說端到端的智能駕駛打出了代差?這就要從最近 AI 領(lǐng)域的大模型革命開始說起。自 2022 年底開始,生成式 AI 席卷了整個(gè)科技領(lǐng)域,越來越多的行業(yè)開始引入大模型。在自動(dòng)駕駛領(lǐng)域,人們開始探索視覺語言模型與世界模型等技術(shù),端到端(End-to-End)的智能駕駛成為了新興的研究方向。端到端的智能駕駛是指把車輛從攝像頭、雷達(dá)、激光雷達(dá)等傳感器獲得的數(shù)據(jù)作為輸入,利用單個(gè) AI 模型直接生成控制汽車指令的方法。2023 年 6 月,全球 AI 頂級(jí)學(xué)術(shù)會(huì)議 CVPR 2023 的最佳論文頒給了 UniAD 框架,它是業(yè)界首個(gè)感知決策一體化的自動(dòng)駕駛通用大模型,打開了以全局任務(wù)為目標(biāo)的自動(dòng)駕駛架構(gòu)方向。在端到端的智駕系統(tǒng)中,大模型通過學(xué)習(xí)人類司機(jī)操作的視頻片段,根據(jù)人類決策理解畫面信息和決策之間的關(guān)系,再不斷進(jìn)行實(shí)踐和調(diào)整,比起以往的模塊化輔助駕駛,更像人類的學(xué)習(xí)過程。和 ChatGPT 一樣,智能駕駛模型可以在面對(duì)前所未見的場(chǎng)景時(shí)實(shí)現(xiàn)「舉一反三」,很大程度上擺脫了對(duì)人類編寫規(guī)則的依賴。最近一年多時(shí)間以來,國(guó)內(nèi)外一眾新勢(shì)力都在頻繁提及端到端的概念,認(rèn)為這將是智能駕駛的技術(shù)終局。正如機(jī)器人公司正在熱捧的「具身智能」,端到端的智能駕駛是給高智商 AI 賦予汽車的軀體,讓它在物理世界中行動(dòng)自如的方法,一旦實(shí)用化,顯然會(huì)是降維打擊。2024 年 1 月 ,特斯拉率先在 FSD v12 版本上實(shí)現(xiàn)了端到端智能駕駛的落地,新系統(tǒng)據(jù)稱只用了幾個(gè)月的訓(xùn)練時(shí)間就擊敗了之前數(shù)年時(shí)間積累的 v11 版。理想成為了緊隨其后的第二家,2024 年 7 月,向外界公布了理想 AD 的全新技術(shù)方案,并已于 10 月底全量上線。據(jù)介紹,理想的雙系統(tǒng)基于 E2E+VLM 大模型,是從諾貝爾獎(jiǎng)得主丹尼爾?卡尼曼《思考,快與慢》中得到的啟示。基于系統(tǒng) 1 和系統(tǒng) 2 的理論,理想提出了一個(gè)全新的自動(dòng)駕駛架構(gòu):使用端到端模型實(shí)現(xiàn)類似本能的快思考,保證大多數(shù)場(chǎng)景的高效;利用速度偏慢但思考能力上限更高的 AI 模型(DriveVLM)實(shí)現(xiàn)少數(shù)復(fù)雜場(chǎng)景下的處理能力。這樣就可以讓智能駕駛系統(tǒng)「更像人」。簡(jiǎn)而言之,其中的系統(tǒng) 1 是真正意義上的端到端模型,輸入是傳感器收集到的數(shù)據(jù),輸出是車的行駛軌跡,全部由一個(gè)模型來實(shí)現(xiàn),中間沒有任何手工的規(guī)則。端到端大幅度提升了安全、舒適和效率,具備更擬人化的駕駛方式。
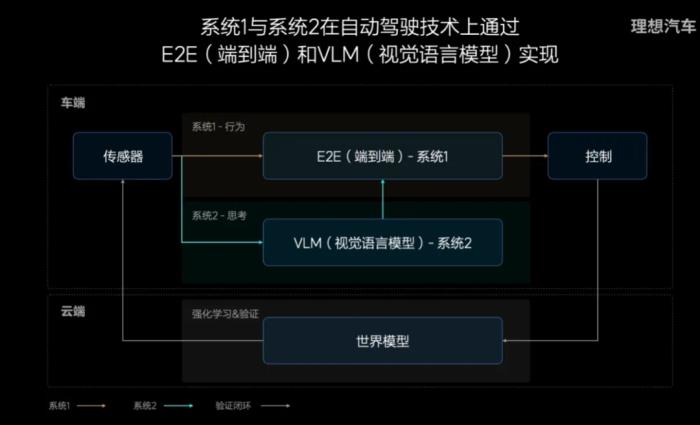
它具有一系列優(yōu)勢(shì):首先是高效的信息傳遞,此前的智能駕駛架構(gòu)經(jīng)常包含很多規(guī)則,限制了整體的上限。在一體化的模型中,所有信息都在模型內(nèi)部傳遞,具有更高的上限,給人們的感受就是更加擬人了。第二是高效計(jì)算,單一模型在 GPU 內(nèi)加載可以一次性完成推理,降低了系統(tǒng)的延遲,體感就是「手和眼」更加協(xié)調(diào)一致了。第三是技術(shù)的迭代速度也變得更快了。由于是一體化的 AI 模型,可以實(shí)現(xiàn)完全的數(shù)據(jù)驅(qū)動(dòng),可以很輕松地做到周級(jí)的迭代。我們可以在實(shí)踐中觀察到,端到端的智能駕駛系統(tǒng)具有不錯(cuò)的未知物體理解能力,可以識(shí)別出倒在地上的樁桶、樹枝等訓(xùn)練數(shù)據(jù)中沒有的物體并進(jìn)行規(guī)避。它也具備超越視距的導(dǎo)航與道路結(jié)構(gòu)理解,可以在沒有任何先驗(yàn)的情況下應(yīng)對(duì)西直門這樣的復(fù)雜立交橋。在一些復(fù)雜的路況,例如有車輛違停在右側(cè)道路上,又有電動(dòng)車行駛在行車道上的情況下,端到端模型也可以展示擬人的規(guī)劃能力,尋找到一條較為高效的路線。就像 OpenAI 的 o3 大模型一樣,這種智能不是人工設(shè)計(jì)出來,而是 AI 自己學(xué)會(huì)的。
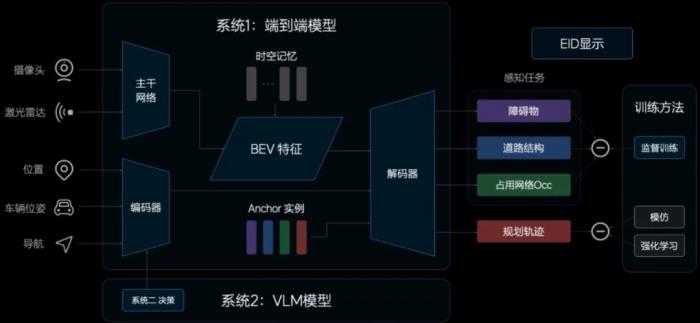
端到端大模型可以解決智能駕駛過程中 95% 的場(chǎng)景,剩下 5% 的情況就要交由「系統(tǒng) 2」來進(jìn)行理解和判斷。在理想的智能駕駛系統(tǒng)中,系統(tǒng) 2 是由 VLM(視覺語言模型)來實(shí)現(xiàn)的。它可以把對(duì)于環(huán)境的理解、駕駛決策的建議甚至參考軌跡遞交給系統(tǒng) 1 來幫助輔助駕駛策略。
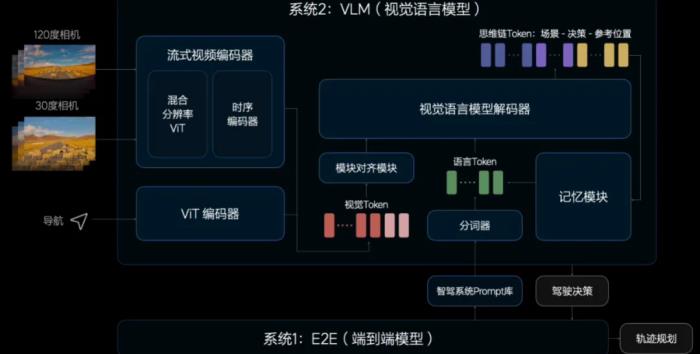
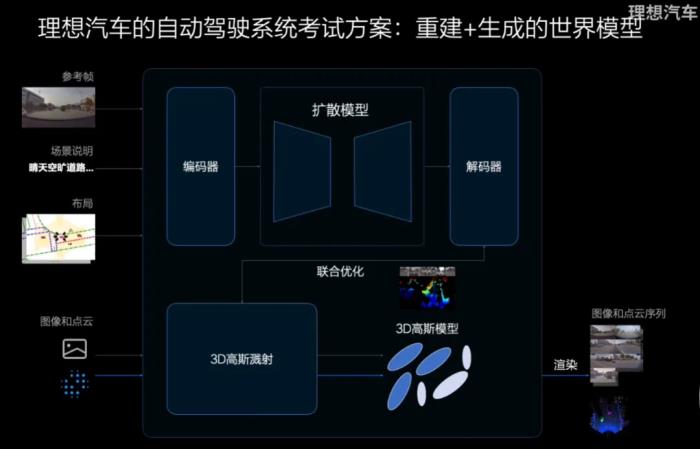
比如在遇到坑洼的路面,VLM 會(huì)指揮車輛降低速度;如果發(fā)現(xiàn)實(shí)際路線和規(guī)劃導(dǎo)航不一致,它可以自己重新規(guī)劃路線;此外,它還能準(zhǔn)確地識(shí)別限時(shí)公交車道、潮汐車道是否可以通行。這就好像是在副駕駛的位置上有一個(gè)教練在實(shí)時(shí)監(jiān)督駕駛行為,主動(dòng)提供建議。有了成套的方法,接下來還需要驗(yàn)證整個(gè)系統(tǒng)的可行性。理想采用了 3D 環(huán)境重建加世界模型的方式,結(jié)合了多種方法的優(yōu)點(diǎn),生成的環(huán)境在多個(gè)視角上可用,又可以生成更多符合真實(shí)世界規(guī)律的未見場(chǎng)景,提升了智能駕駛的泛化性。
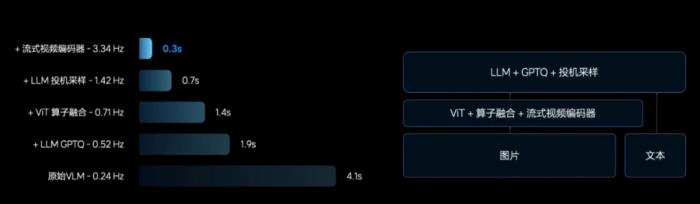
跑通流程以后,理想繼續(xù)改進(jìn)了 AI 的訓(xùn)練方法。端到端的學(xué)習(xí)目標(biāo)是行駛軌跡,并不像感知任務(wù)只需要給出是或否的判斷。在日常生活中,即使是同一個(gè)司機(jī)也可能作出不同的行駛策略,這可能會(huì)導(dǎo)致 AI 學(xué)習(xí)出一些詭異的駕駛行為。因此,理想在訓(xùn)練過程中加入了強(qiáng)化學(xué)習(xí),通過獎(jiǎng)勵(lì)函數(shù)的設(shè)置學(xué)習(xí)出策略正確的模型。再往下是部署和優(yōu)化。VLM 在端側(cè)部署時(shí),工程師們面臨著推理時(shí)延的挑戰(zhàn)。通過從量化到張量算子融合等大量?jī)?yōu)化技術(shù),理想把 VLM 推理時(shí)延從 4.1 秒縮減到了 0.3 秒,業(yè)界首次在 Orin-X 硬件上部署了大模型,真正實(shí)現(xiàn)了視覺模型在智能駕駛上的實(shí)用化。
正是這樣一套系統(tǒng),做到了全場(chǎng)景的端到端與可視化,也成為了國(guó)內(nèi)首個(gè)車端部署大模型的自動(dòng)駕駛系統(tǒng)。理想表示,基于北美實(shí)際對(duì)比體驗(yàn),理想端到端的 NOA 駕駛體驗(yàn),已比肩特斯拉北美 FSD 最新版本 V13.2 水平。現(xiàn)在的理想是一家人工智能企業(yè)端到端智能駕駛的突破,是一個(gè)從量變到質(zhì)變的過程。作為銷量靠前的新能源玩家,理想在國(guó)內(nèi)擁有超百萬規(guī)模的自動(dòng)駕駛車隊(duì),在過去幾年積累了超過數(shù)百億公里的行駛里程。理想從所有車主數(shù)據(jù)中篩選出優(yōu)質(zhì)數(shù)據(jù),建立了一套「老司機(jī)」的評(píng)價(jià)標(biāo)準(zhǔn)。老司機(jī)既要具備好的駕駛技能,也要有好的駕駛習(xí)慣。只有不到 3% 的車主通過了考核。理想在 2024 年年初擁有了 5EFLOPS 的算力 ,再加上智能駕駛團(tuán)隊(duì)此前在端到端模型上的預(yù)研成果,做到了天時(shí)地利人和。2024 年 1 月 1 日 - 12 月 31 日,理想智能駕駛累計(jì)用戶已超百萬人,智能駕駛總里程達(dá) 17.2 億公里。截至去年年底,算力也已提升至 8.1EFLOPS。再往高一層看,智能駕駛水平進(jìn)入世界第一梯隊(duì)的理想,正被全新的使命驅(qū)動(dòng)著。此前,理想創(chuàng)始人、CEO 兼董事長(zhǎng)李想暢談了公司的未來發(fā)展方向。他認(rèn)為電動(dòng)化是上半場(chǎng),智能化是下半場(chǎng),理想汽車未來一定會(huì)持續(xù)發(fā)力 AI,最終通過理想汽車的載體來實(shí)現(xiàn) AGI(通用人工智能)。理想把自己定義為一個(gè)人工智能企業(yè),目標(biāo)是把人工智能進(jìn)行汽車化,并推動(dòng) AI 普惠到每一個(gè)家庭。最近一年理想的 100 億研發(fā)投入,近一半投在了 AI 上,它自研了基座模型、端到端加 VLM 的自動(dòng)駕駛系統(tǒng),從最開始的論文、技術(shù)研發(fā)到產(chǎn)品的交付,不斷引領(lǐng)著業(yè)界風(fēng)向。

可以說,端到端的智能駕駛,是理想長(zhǎng)期堅(jiān)持核心技術(shù)自研的必然體現(xiàn)。值得一提的是,李想給 AI 的未來定義了三個(gè)階段:第一階段——成為人類能力的延伸和增強(qiáng),提升工作效率(L3 階段),有望在 2025 年實(shí)現(xiàn)。在此階段我們還需要在行駛過程中對(duì) AI 進(jìn)行監(jiān)督。第二階段——成為人類的助手(L4 階段),能夠 100% 自動(dòng)駕駛并承擔(dān)相應(yīng)責(zé)任,有望在三年內(nèi)實(shí)現(xiàn)。這會(huì)推動(dòng)新技術(shù)的大規(guī)模應(yīng)用。第三階段——硅基家人,AI 智能體可以自主地工作,幫助人們管理好家庭中的各種事物,人類的記憶也可以在 AI 上得到延續(xù)。為此,理想希望從兩個(gè)方向入手,一面是端到端智能駕駛,另一面是理想同學(xué) App。后者已于 2024 年底全量上線。在李想看來,理想同學(xué)和自動(dòng)駕駛,將來有一天還會(huì)融合在一起:「我們認(rèn)為,基座模型到一定時(shí)刻一定會(huì)變成 VLA(Vision Language Action Model),因?yàn)檎Z言模型也要通過語言和認(rèn)知去理解三維世界。而自動(dòng)駕駛在走向 L4 時(shí)必須要有極強(qiáng)的認(rèn)知能力。當(dāng)技術(shù)形態(tài)發(fā)生變化,它才能夠有效地理解這個(gè)世界。」通往 AGI 的路,理想已經(jīng)開了個(gè)好頭。


 新火種
2025-01-17
新火種
2025-01-17