

 新火種
2024-11-17
新火種
2024-11-17 


天下苦英偉達(dá)久矣!PyTorch官方免CUDA加速推理,Triton時代要來?
近日,PyTorch 官方分享了如何實現(xiàn)無 CUDA 計算,對各個內(nèi)核進(jìn)行了微基準(zhǔn)測試比較,并討論了未來如何進(jìn)一步改進(jìn) Triton 內(nèi)核以縮小與 CUDA 的差距。
在做大語言模型(LLM)的訓(xùn)練、微調(diào)和推理時,使用英偉達(dá)的 GPU 和 CUDA 是常見的做法。在更大的機(jī)器學(xué)習(xí)編程與計算范疇,同樣嚴(yán)重依賴 CUDA,使用它加速的機(jī)器學(xué)習(xí)模型可以實現(xiàn)更大的性能提升。
雖然 CUDA 在加速計算領(lǐng)域占據(jù)主導(dǎo)地位,并成為英偉達(dá)重要的護(hù)城河之一。但其他一些工作的出現(xiàn)正在向 CUDA 發(fā)起挑戰(zhàn),比如 OpenAI 推出的 Triton,它在可用性、內(nèi)存開銷、AI 編譯器堆棧構(gòu)建等方面具有一定的優(yōu)勢,并持續(xù)得到發(fā)展。
近日,PyTorch 官宣要做「無英偉達(dá) CUDA 參與的大模型推理」。在談到為什么要 100% 使用 Triton 進(jìn)行探索時,PyTorch 表示:「Triton 提供了一條途徑,使大模型 能夠在不同類型的 GPU 上運行,包括英偉達(dá)、AMD、英特爾和其他基于 GPU 的加速器。
此外 Triton 還在 Python 中為 GPU 編程提供了更高的抽象層,使得使用 PyTorch 能夠比使用供應(yīng)商特定的 API 更快地編寫高性能內(nèi)核。」

在 PyTorch 博客中討論了使用流行的 LLM 模型(例如 Meta 的 Llama3-8B 和 IBM 的 Granite-8B Code)實現(xiàn) FP16 推理的方法,其中計算是 100% 使用 OpenAI 的 Triton 語言執(zhí)行的。
對于使用基于 Triton 內(nèi)核的模型生成單個 token 的時間,PyTorch 能夠?qū)崿F(xiàn)在英偉達(dá) H100 GPU 上 Llama 和 Granite 的 CUDA 內(nèi)核主導(dǎo)工作流程的 0.76-0.78 倍性能,以及在英偉達(dá) A100 GPU 上的 0.62-0.82 倍。
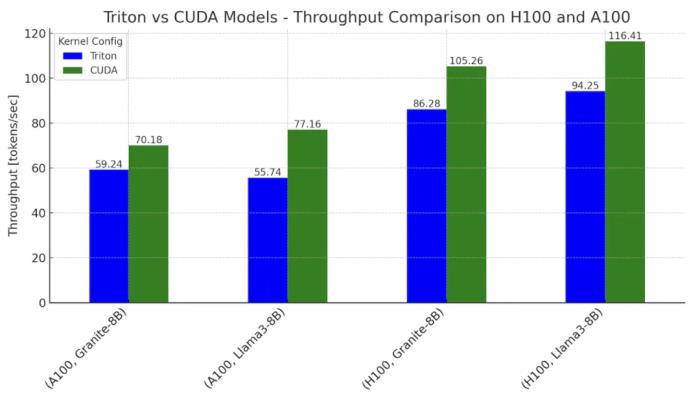
圖 1. 在英偉達(dá) H100 和 A100 上,Llama3-8B 和 Granite-8B 的 Triton 和 CUDA 變體的推理吞吐量比較。設(shè)置:批大小 = 2,輸入序列長度 = 512,輸出序列長度 = 256
也許告別英偉達(dá)的時候真要來了。

Transformer 塊的組成
PyTorch 團(tuán)隊首先對基于 Transformer 的模型中發(fā)生的計算進(jìn)行細(xì)分。下圖顯示了典型 Transformer 塊的「內(nèi)核(kernel)」。
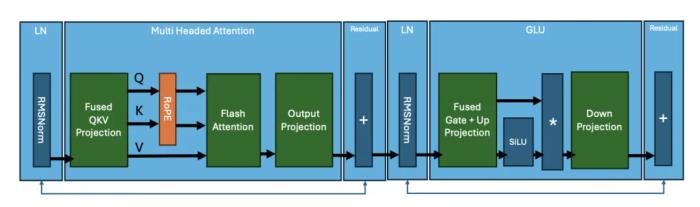
圖 2
Llama3 架構(gòu)的核心操作總結(jié)如下:
均方根歸一化(RMSNorm)
矩陣乘法:Fused QKV
RoPE
注意力
矩陣乘法:輸出投影
RMSNorm
矩陣乘法:Fused Gate + Up Projection
激活函數(shù):SiLU
點乘(Element Wise Multiplication)
矩陣乘法:Down Projection
這些操作中的每一個都是通過在 GPU 上執(zhí)行一個(或多個)內(nèi)核來計算的。雖然每個內(nèi)核的細(xì)節(jié)在不同的 Transformer 模型中可能有所不同,但核心操作保持不變。例如,IBM 的 Granite 8B Code 模型在 MLP 層中使用偏置,與 Llama3 不同。此類更改確實需要對內(nèi)核進(jìn)行修改。典型的模型是這些 Transformer 塊的堆疊,這些 Transformer 塊通過嵌入層連接在一起。
模型推理
典型的模型架構(gòu)代碼與 PyTorch 啟動的 python model.py 文件共享。在默認(rèn)的 PyTorch Eager Execution 模式下,這些內(nèi)核都是使用 CUDA 執(zhí)行的。為了實現(xiàn) 100% Triton 進(jìn)行端到端 Llama3-8B 和 Granite-8B 推理,需要編寫和集成手寫 Triton 內(nèi)核以及利用 torch.compile(生成 Triton 操作)。首先,PyTorch 用編譯器生成的 Triton 內(nèi)核替換較小的操作,其次,PyTorch 用手寫的 Triton 內(nèi)核替換更昂貴和復(fù)雜的計算(例如矩陣乘法和閃存注意力)。
Torch.compile 自動為 RMSNorm、RoPE、SiLU 和點乘生成 Triton 內(nèi)核。使用 Nsight Systems 等工具,可以觀察到這些生成的內(nèi)核,它們在矩陣乘法和注意力之間表現(xiàn)為微小的深綠色內(nèi)核。

圖 3. 使用 torch.compile 跟蹤 Llama3-8B,顯示用于矩陣乘法和閃存注意力的 CUDA 內(nèi)核。
對于上面的跟蹤,PyTorch 團(tuán)隊注意到,在 Llama3-8B 樣式模型中,占 E2E 延遲 80% 的兩個主要操作是矩陣乘法和注意力內(nèi)核,并且兩者仍然是 CUDA 內(nèi)核。因此,為了彌補剩余的差距,PyTorch 團(tuán)隊用手寫的 Triton 內(nèi)核替換了 matmul 和注意力內(nèi)核。
Triton SplitK GEMM 內(nèi)核
對于線性層中的矩陣乘法,PyTorch 團(tuán)隊編寫了一個自定義 FP16 Triton GEMM(通用矩陣 - 矩陣乘法)內(nèi)核,該內(nèi)核利用了 SplitK 工作分解。
GEMM 內(nèi)核調(diào)優(yōu)
為了實現(xiàn)最佳性能,PyTorch 團(tuán)隊使用窮舉搜索方法來調(diào)整 SplitK GEMM 內(nèi)核。Granite-8B 和 Llama3-8B 具有如下形狀的線性層:

圖 4. Granite-8B 和 Llama3-8B 線性層權(quán)重矩陣形狀。
每個線性層都有不同的權(quán)重矩陣形狀。因此,為了獲得最佳性能,必須針對每個形狀輪廓調(diào)整 Triton 內(nèi)核。在對每個線性層進(jìn)行調(diào)整后,PyTorch 能夠在 Llama3-8B 和 Granite-8B 上實現(xiàn)相對于未調(diào)整的 Triton 內(nèi)核 1.20 倍的 E2E 加速。
Flash Attention 內(nèi)核
PyTorch 團(tuán)隊使用不同的配置,對現(xiàn)有 Triton flash attention 內(nèi)核進(jìn)行了評估,包括
AMD Flash
OpenAI Flash
Dao AI Lab Flash
XFormers Flash
PyTorch FlexAttention
PyTorch 團(tuán)隊分別在 eager 模式和編譯模式下評估了每個內(nèi)核的文本生成質(zhì)量。下圖 5 為不同 Flash Attention 內(nèi)核的比較。
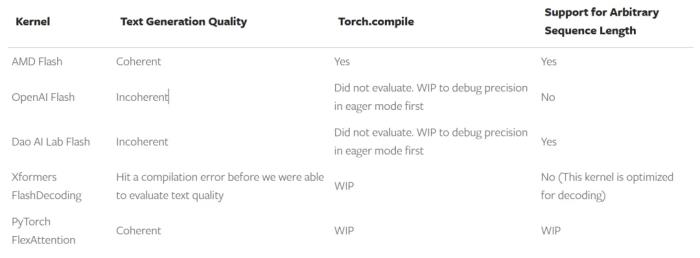
上圖總結(jié)了 PyTorch 觀察到的開箱即用情況,并預(yù)計內(nèi)核 2 到 5 可以在修改后滿足上述標(biāo)準(zhǔn)。不過這也表明,擁有一個可用于基準(zhǔn)測試的內(nèi)核通常只是將它用作端到端生產(chǎn)內(nèi)核的開始。
PyTorch 團(tuán)隊選擇在后續(xù)測試中使用 AMD flash attention 內(nèi)核,它通過 torch.compile 進(jìn)行編譯,并在 eager 和編譯模式下產(chǎn)生清晰的輸出。
為了滿足 torch.compile 與 AMD flash attention 內(nèi)核的兼容性,PyTorch 團(tuán)隊必須將它定義為 torch 自定義算子。并且封裝更復(fù)雜的 flash attention 內(nèi)核遵循以下兩個步驟:
一是將函數(shù)封裝為一個 PyTorch 自定義算子。

二是向該算子添加一個 FakeTensor 內(nèi)核,并在給定 flash 輸入張量的形狀(q、k 和 v)時,計算 flash 內(nèi)核的輸出形狀。
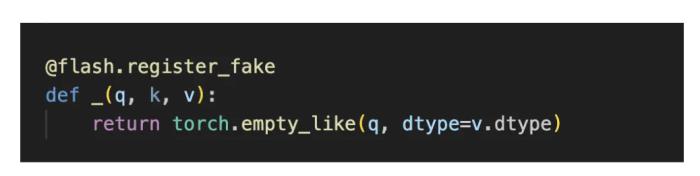
在將 Triton flash 內(nèi)核定義為一個自定義 op 后,PyTorch 團(tuán)隊可以成功地對它進(jìn)行編譯以實現(xiàn)端到端運行。

圖 6:在交換 Triton matmul 和 Triton flash attention 內(nèi)核后,使用 torch.compile 的 Llama3-8B 軌跡。
從圖中可以看到,在集成 SplitK 矩陣乘法內(nèi)核后,torch op 封裝 flash attention 內(nèi)核,然后運行 torch.compile,即可實現(xiàn)使用 100% Triton 計算內(nèi)核的前向傳遞。
端到端基準(zhǔn)測試
PyTorch 團(tuán)隊分別對運行 Granite-8B 和 Llama3-8B 模型的英偉達(dá) H100 和 A100(單 GPU)進(jìn)行了端到端測試,使用了兩種不同的配置來執(zhí)行基準(zhǔn)測試。
其中 Triton 內(nèi)核配置使用了:
Triton SplitK GEMM
AMD Triton Flash Attention
CUDA 內(nèi)核配置使用了
cuBLAS GEMM
cuDNN Flash Attention - Scaled Dot-Product Attention (SDPA)
在典型推理設(shè)置下,兩種 eager 和 torch 編譯模式的吞吐量和 inter-token 延遲如下圖所示。
圖 7:H100 和 A100 上 Granite-8B 和 Llama3-8B 單 token 生成延遲(批大小 = 2,輸入序列長度 = 512,輸出序列長度 = 256)。
總的來說,在 H100 上,Triton 模型最高可以達(dá)到 CUDA 模型性能的 78%;在 A100 上可以達(dá)到 82%。這些性能差距是由 matmul 和 flash attention 的內(nèi)核延遲造成的。
微基準(zhǔn)測試
下圖 8 為 Triton 和 CUDA 內(nèi)核延遲比較(英偉達(dá) H100 上運行 Llama3-8B)。輸入為一個任意 prompt(批大小 = 1,prompt 序列長度 = 44),以解碼延遲時間。
最后結(jié)果顯示,Triton matmul 內(nèi)核比 CUDA 慢了 1.2 至 1.4 倍,而 AMD Triton Flash Attention 比 CUDA SDPA 慢了 1.6 倍。
以上結(jié)果凸顯了需要進(jìn)一步提升 GEMM 和 Flash Attention 等核心原語內(nèi)核的性能。最近的一些工作(如 FlashAttention-3、FlexAttention) 已經(jīng)提出了更好地利用底層硬件和 Triton 的方法,PyTorch 希望在它們的基礎(chǔ)上實現(xiàn)更大加速。為了闡明這一點,PyTorch 團(tuán)隊將 FlexAttention 與 SDPA、AMD’s Triton Flash 內(nèi)核進(jìn)行了比較。
PyTorch 團(tuán)隊 正努力驗證 FlexAttention 的端到端性能。目前,F(xiàn)lexAttention 的初始微基準(zhǔn)測試結(jié)果表明,在查詢向量較小的情況下,有望實現(xiàn)更長的上下文以及解碼問題形狀。
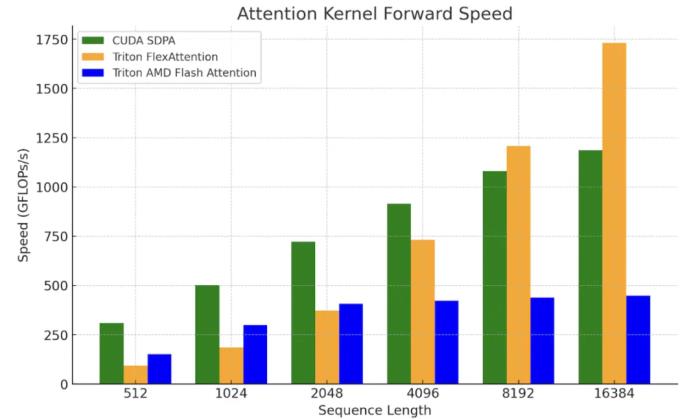
圖 9:英偉達(dá) H100 SXM5 80GB 上 FlexAttention 內(nèi)核基準(zhǔn)測試(批大小 = 1,最大頭數(shù) = 32,頭維數(shù) = 128)。
未來工作
未來,PyTorch 團(tuán)隊計劃探索進(jìn)一步優(yōu)化 matmuls 的方法,以便更好地利用硬件,并為基于 Triton 的方法實現(xiàn)更大的加速。
對于 flash attention,PyTorch 團(tuán)隊計劃探索 FlexAttention 和 FlashAttention-3 等內(nèi)核中使用到的技術(shù),以幫助進(jìn)一步縮小 Triton 與 CUDA 之間的差距。同時還將探索端到端 FP8 LLM 推理。
原文鏈接:https://pytorch.org/blog/cuda-free-inference-for-llms/
相關(guān)推薦


- 免責(zé)聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認(rèn)可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
