

 新火種
2024-11-16
新火種
2024-11-16 


乏善可陳的第二屆OpenAI開發者大會,果然沒有掀起太大波瀾
OpenAI宮斗后的 DevDay 開發者大會,沒有什么驚喜。
OpenAI 的宮斗大戲剛落下帷幕,今日凌晨就在舊金山召開了第二屆 DevDay 開發者大會。
不過,與去年盛大的活動相比,今年略顯低調,他們沒有推出重大產品,而是選擇對其現有的 AI 工具和 API 進行增量改進。
在這次活動中,OpenAI 發布了四大API新功能:視覺微調(Vision Fine-Tuning)、實時 API(Realtime API)、模型蒸餾(Model Distillation)和提示緩存(Prompt Caching)。
這些新工具突出了 OpenAI 的戰略轉變,即轉向賦予其開發者生態系統更多能力,而不是直接在最終用戶應用領域競爭。
Sam Altman 也在 X 上表示,從 GPT-4 到 4o mini,每個 token 的成本降低 98%,同時處理 token 的數量暴漲 50 倍。
最后,Altman 還不忘「鼓舞士氣」:通往 AGI 的道路從未如此清晰。
實時 API:構建快速的語音到語音體驗
OpenAI 在開發者大會上正式推出實時 API 的公測版,允許所有付費開發者在他們的應用程序中構建低延遲、多模態的體驗。
與 ChatGPT 的高級語音模式類似,實時 API 支持使用 API 中已經支持的 6 種預設語音進行自然的語音到語音對話。這意味著開發者可以開始將 ChatGPT 的語音控制添加到應用程序中。
他們還推出了聊天完成 API(Chat Completions API)中的音頻輸入和輸出功能,以支持那些不需要實時 API 低延遲優勢的使用場景。
以前,要創建類似的語音助手體驗,開發者需要使用像 Whisper 這樣的自動語音識別模型來轉錄音頻,然后將文本傳遞給文本模型進行推理,最后使用文本到語音模型播放模型的輸出。這種方法常常導致情感和口音的丟失,以及明顯的延遲。
現在有了聊天完成 API,開發者可以用一個 API 調用來處理整個流程,盡管它仍然比人類對話慢。實時 API 通過直接流式傳輸音頻輸入和輸出來改進這一點,使得會話體驗更加自然。它還可以自動處理中斷,就像 ChatGPT 中的高級語音模式一樣。
實時 API 本質上簡化了構建語音助手和其他會話 AI 工具的過程,消除了將多個模型組合用于轉錄、推理和文本到語音轉換的需要。
例如,一個名為 Speak 的語言學習平臺,使用實時 API 來驅動其角色扮演功能,鼓勵用戶練習用新語言進行對話。
實時 API 使用文本和音頻 token 價格也已出爐。
文本輸入 token 的價格是每 100 萬個 5 美元,輸出 token 每 100 萬個 20 美元。
音頻輸入的價格是每 100 萬個 100 美元,輸出是每 100 萬個 200 美元。這相當于每分鐘音頻輸入約 0.06 美元,每分鐘音頻輸出約 0.24 美元。
對于希望創建基于語音的應用程序的開發者來說,這個價格還是比較公道的。
視覺微調:使用圖像和文本微調 GPT-4o
自從 OpenAI 在 GPT-4o 上首次引入微調功能以來,已經有成千上萬的開發者使用僅限文本的數據集定制模型,以提高特定任務的性能。然而,在許多情況下,僅對文本進行模型微調并不能提供預期的性能提升。
因此,此次 OpenAI 宣布為 GPT-4o 引入視覺微調功能,允許開發者使用圖像和文本來自定義模型的視覺理解能力,從而實現增強的視覺搜索功能、改進自動駕駛汽車或智能城市的物體檢測,以及更準確的醫學圖像分析等應用。
例如,東南亞的一家食品配送和共享出行公司 Grab 已經利用這項技術來改進其地圖服務。僅使用 100 個示例的視覺微調,Grab 在車道計數準確率上提高了 20%,在限速標志定位上提升了 13%,超過了基礎 GPT-4o 模型。
這一現實世界的應用展示了視覺微調的可能性,即使用少量的視覺訓練數據,也能顯著增強各行各業的人工智能服務。
目前,所有付費用戶都可以使用視覺微調功能,直到 2024 年 10 月 31 日,OpenAI 每天為開發者提供免費的 100 萬個訓練 token,用于通過圖像微調 GPT-4o 模型。
2024 年 10 月 31 日之后,微調 GPT-4o 模型的費用將是每 100 萬個 token 25 美元,推理的費用是每 100 萬個輸入 token 3.75 美元,每 100 萬個輸出 token 15 美元。
提示緩存:成本可降低50%
許多開發者在構建 AI 應用程序時會在多個 API 調用中重復使用相同的上下文,比如在編輯代碼庫或與聊天機器人進行長時間、多輪次的對話時。
今天,OpenAI 引入了提示緩存(Prompt Caching),這是一個旨在降低開發者成本和延遲的功能。
該系統會自動對模型最近處理過的輸入 tokens 應用打 50% 的折扣,對于頻繁重復使用上下文的應用來說,這可能會帶來成本的大幅降低。
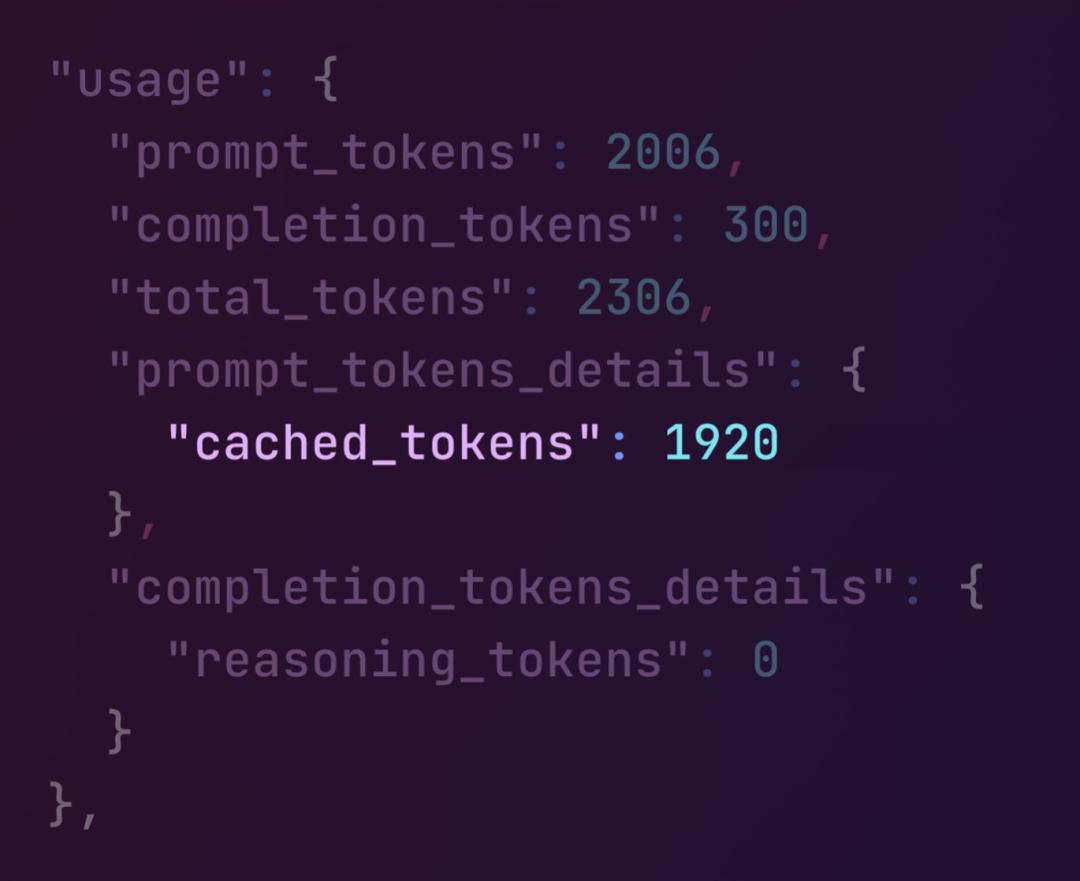
提示緩存將自動應用于最新版本的 GPT-4o、GPT-4o mini、o1-preview 和 o1-mini,以及這些模型的微調版本。
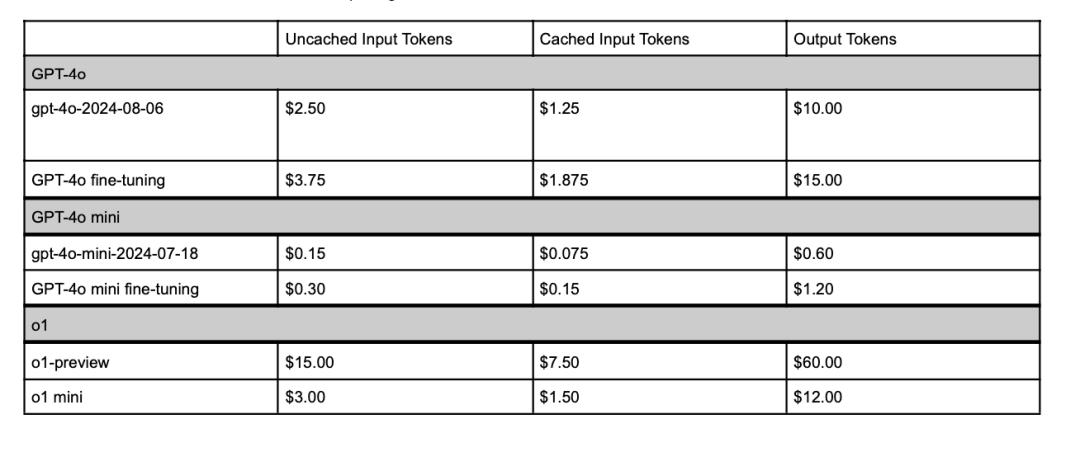
(來源:OpenAI)OpenAI 在 2024 DevDay 上公布的定價表顯示,AI 模型使用成本大幅降低,緩存輸入 tokens 相比未緩存 tokens 在各種 GPT 模型中最多可節省 50% 的費用。新的 o1 模型展示了其高級功能的溢價定價。
「我們一直很忙,」OpenAI 平臺產品負責人奧利維爾?戈德蒙特(Olivier Godement)在公司舊金山總部舉行的小型新聞發布會上說,「就在兩年前,GPT-3 還處于領先地位。現在,我們已經將成本降低了近 1000 倍。我試圖想出一個在兩年內將成本降低了近 1000 倍的技術示例 —— 但我想不到這樣的例子。」
這種顯著的降成本,為初創企業和企業探索新應用提供了重大機遇,這些應用此前由于成本高昂而無法觸及。
模型蒸餾:讓小模型擁有尖端模型功能
OpenAI 此次還引入了模型蒸餾(Model Distillation)。這種集成的工作流程允許開發者使用 o1-preview 和 GPT-4o 等高級模型的輸出,來提高像 GPT-4o mini 這樣更高效模型的性能。
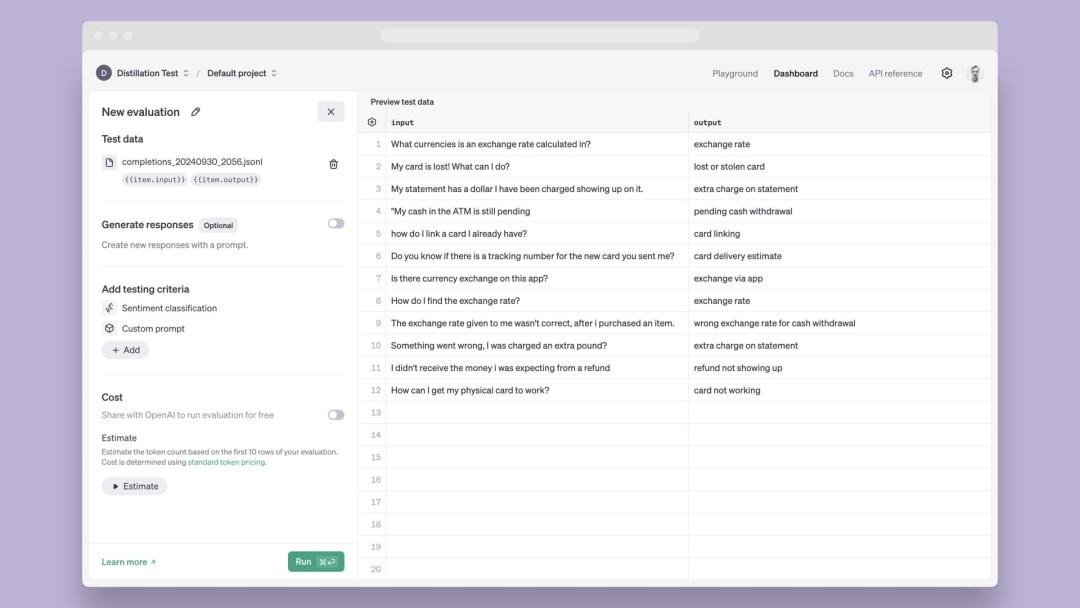
模型蒸餾涉及使用更強大的模型的輸出來微調更小、更經濟的模型,使它們能夠在特定任務上以更低的成本匹配高級模型的性能。
直到現在,蒸餾一直是一個多步驟、容易出錯的過程,需要開發者手動協調多個操作,從生成數據集到微調模型和測量性能提升。由于蒸餾本質上是迭代的,開發者需要重復運行每一步,增加了顯著的工作量和復雜性。
OpenAI 新模型蒸餾套件包括:
存儲完成:開發者現在可以通過自動捕獲和存儲我們的 API 生成的輸入輸出對,輕松地為蒸餾生成數據集,比如 GPT-4o 或 o1-preview。有了存儲完成,你可以輕松地使用生產數據構建數據集來評估和微調模型。開發者可以查看這個集成指南來學習如何選擇存儲完成。
評估(beta):開發者現在可以在我們平臺上創建和運行自定義評估,以測量模型在特定任務上的性能。與手動創建評估腳本和整合不同的日志工具相比,評估提供了一種集成的方式來測量模型性能。你可以使用存儲完成的數據或上傳現有數據集來設置你的評估。評估也可以獨立于微調使用,以定量評估模型在用例中的性能。
微調:存儲完成和評估完全集成到我們現有的微調服務中。這意味著開發者可以在他們的微調作業中使用存儲完成創建的數據集,并使用評估在微調模型上運行評估,所有這些都在我們的平臺上完成。
這種方法可以使小型公司利用與高級模型相似的能力,而不必承擔相同的計算成本。它解決了 AI 行業中長期存在的一個分歧,即尖端、資源密集型系統與更易訪問但能力較弱的對應系統之間的分歧。
比如一家小型醫療技術初創公司,該公司正在為農村診所開發一個 AI 驅動的診斷工具。使用模型蒸餾,該公司可以訓練一個緊湊的模型,該模型在標準筆記本電腦或平板電腦上運行時,能夠捕捉到更大模型的大部分診斷能力。這可能會將復雜的 AI 能力帶到資源受限的環境中,有可能改善服務不足地區的醫療保健結果。
總體來說,今年 OpenAI 的開發者大會稍顯低調,甚至可以說是乏善可陳。
要知道,2023 年 DevDay 開發者大會上,OpenAI 推出了 GPT Store 和自定義 GPT 創建工具,不少網友將其稱為「iPhone 時刻」。
這似乎也意味著,OpenAI 正進行戰略轉變,優先考慮生態系統的發展,而不是僅發布吸引人眼球的重磅產品。
參考鏈接:
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
