

首頁(yè) >
AI資訊 >
行業(yè)動(dòng)態(tài) >
Anthropic挖走DeepMind強(qiáng)化學(xué)習(xí)大牛、AlphaGo核心作者JulianSchrittwieser
Anthropic挖走DeepMind強(qiáng)化學(xué)習(xí)大牛、AlphaGo核心作者JulianSchrittwieser
 新火種
2024-11-15
新火種
2024-11-15 

從 AlphaGo、AlphaZero 、MuZero 到 AlphaCode、AlphaTensor,再到最近的 Gemini 和 AlphaProof,Julian Schrittwieser 的工作成果似乎比他的名字更廣為人知。
今天的 AI 社區(qū),再次被一則大佬轉(zhuǎn)會(huì)消息吸引了目光。
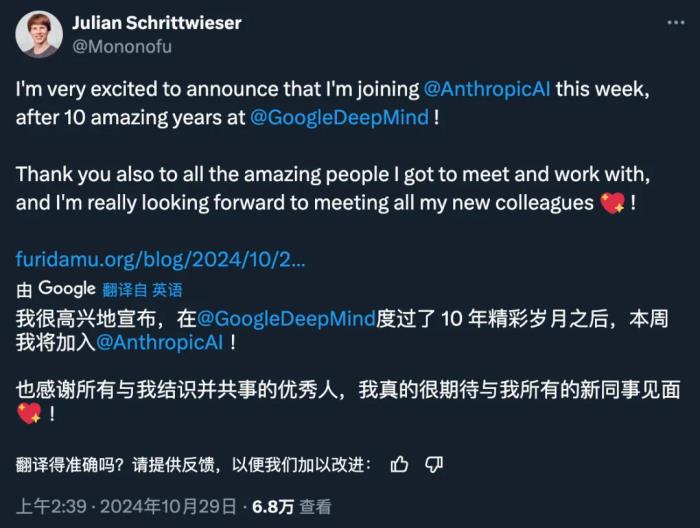
在谷歌工作十年后,大名鼎鼎的谷歌 DeepMind Alpha 系列核心作者 Julian Schrittwieser,宣布加入 Anthropic。
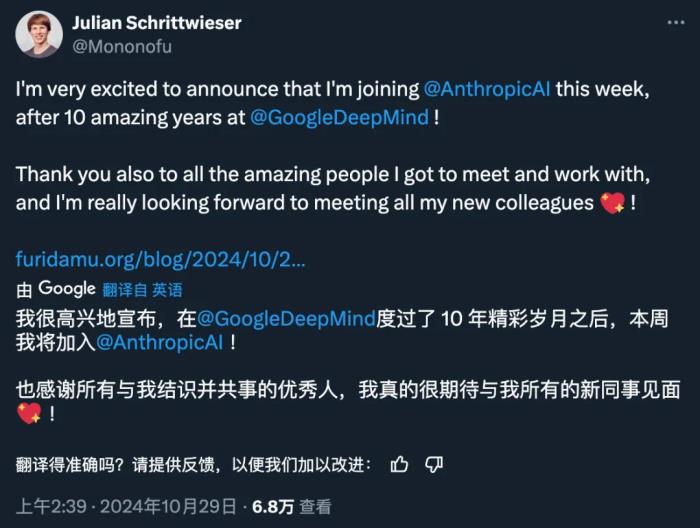
我很高興地宣布,將從本周起加入 Anthropic!Claude 是我發(fā)現(xiàn)自己一直在使用的第一個(gè) LLM。最近,我被《Artifacts》和《Computer Use》以及 Claude 不斷提高的技能深深震撼了。
我非常幸運(yùn)地參與了谷歌 DeepMind 過(guò)去 10 年的奇妙旅程,在那里我參與了很多令人興奮的項(xiàng)目,這是我做夢(mèng)都想不到的:從 AlphaGo 到 AlphaZero 和 MuZero 的傳奇;還有很多的應(yīng)用研究,如 AlphaCode 和 AlphaTensor,以及最近的 Gemini 和 AlphaProof。我相信,那里的團(tuán)隊(duì)也將繼續(xù)創(chuàng)造驚人的成就,我迫不及待地想一探究竟!
Julian Schrittwieser 的跳槽,可以說(shuō)是近期領(lǐng)域內(nèi)最為驚人的一則消息,因?yàn)?Julian Schrittwieser 在 DeepMind 內(nèi)部的地位非同尋常。更令人好奇的是,Anthropic 是如何招攬到這樣一位頂尖人才:
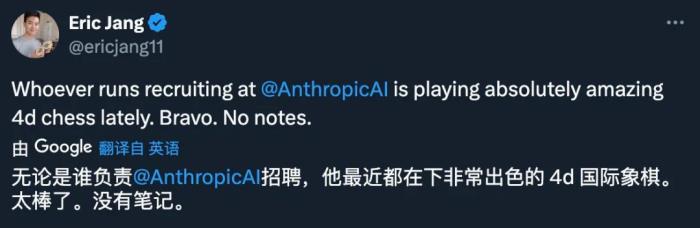
不管過(guò)程如何,這一定是 Anthropic 最「超值」的一次招聘:

在 DeepMind 誕生以來(lái)的數(shù)年中,「Alpha 系列成果」一直是該團(tuán)隊(duì)最閃耀的前沿成果。而 Julian Schrittwieser 是這些偉大成就中不可忽視的貢獻(xiàn)者。
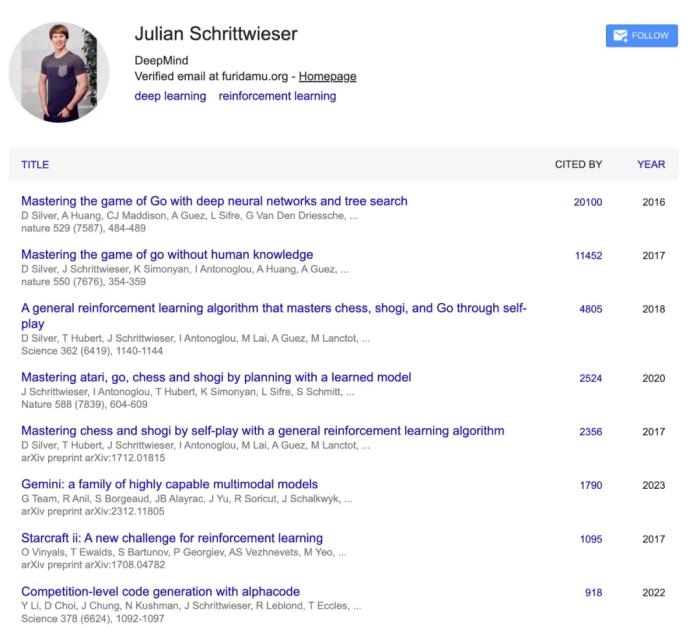
2016 年,DeepMind 開發(fā)的 AlphaGo 以 4:1 擊敗世界頂級(jí)圍棋棋手李世石(Lee Se-dol),成為轟動(dòng)全球的人工智能里程碑事件。Julian Schrittwieser 參與撰寫了第一篇關(guān)于 AlphaGo 的里程碑式論文。
《AlphaGo 4:1 戰(zhàn)勝李世石,我們需要更好的理解人工智能》2017 年,在 AlphaGo 與柯潔的比賽之后,DeepMind 宣布退役 AlphaGo,自學(xué)成才的 AlphaGo Zero 以 100:0 擊敗了早期的競(jìng)技版 AlphaGo,Julian Schrittwieser 是 AlphaGo Zero 論文的第二作者,也負(fù)責(zé)了從主搜索算法、訓(xùn)練框架到對(duì)新硬件的支持等工作。
《無(wú)需人類知識(shí),DeepMind 新一代圍棋程序 AlphaGo Zero 再次登上 Nature》《DeepMind AlphaGo Zero 引爆業(yè)內(nèi),創(chuàng)造者現(xiàn)身 Reddit 問答》而 AlphaGo Zero 隨后被拓展為一個(gè)名為 AlphaZero 的程序。2017 年底,DeepMind 正式發(fā)表了 AlphaZero,這是一種可以從零開始通過(guò) Self-Play 強(qiáng)化學(xué)習(xí)在多種任務(wù)上達(dá)到超越人類水平的算法。該算法經(jīng)過(guò)不到 24 小時(shí)的訓(xùn)練后,即可在國(guó)際象棋和日本將棋上擊敗此前業(yè)內(nèi)頂尖的計(jì)算機(jī)程序(這些程序早已超越人類世界冠軍水平),也輕松擊敗了訓(xùn)練 3 天時(shí)間的 AlphaGo Zero。
《不只是圍棋!AlphaGo Zero 之后 DeepMind 推出泛化強(qiáng)化學(xué)習(xí)算法 AlphaZero》2020 年,DeepMind 發(fā)表了 MuZero。在不具備任何底層動(dòng)態(tài)知識(shí)的情況下,該算法通過(guò)結(jié)合基于樹的搜索和學(xué)得模型,不僅在國(guó)際象棋、日本將棋和圍棋的精確規(guī)劃任務(wù)中匹敵 AlphaZero,還在 30 多款雅達(dá)利游戲中展示出了超越人類的表現(xiàn)。Julian Schrittwieser 是 MuZero 論文《Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model》的核心作者之一。
《通用 AlphaGo 誕生?DeepMind 的 MuZero 在多種棋類游戲中超越人類》2022 年 2 月,DeepMind 發(fā)布了基于 Transformer 模型的 AlphaCode,可以編寫與人類相媲美的計(jì)算機(jī)程序。包括 Julian Schrittwieser 在內(nèi)的多位作者后續(xù)又在《Science》上發(fā)表了論文。
《卷起來(lái)了!DeepMind 發(fā)布媲美普通程序員的 AlphaCode,同日 OpenAI 神經(jīng)數(shù)學(xué)證明器拿下奧數(shù)題》《DeepMind 攜 AlphaCode 登 Science 封面,寫代碼能力不輸程序員》2022 年 10 月,DeepMind 提出了 AlphaTensor,第一個(gè)可用于為矩陣乘法等基本任務(wù)發(fā)現(xiàn)新穎、高效且可證明正確的算法的人工智能系統(tǒng),并揭示了 50 年來(lái)在數(shù)學(xué)領(lǐng)域一個(gè)懸而未決的問題,即找到兩個(gè)矩陣相乘最快方法。AlphaTensor 建立在 AlphaZero 的基礎(chǔ)上,展示了 AlphaZero 從用于游戲到首次用于解決未解決的數(shù)學(xué)問題的一次轉(zhuǎn)變。
《強(qiáng)化學(xué)習(xí)發(fā)現(xiàn)矩陣乘法算法,DeepMind 再登 Nature 封面推出 AlphaTensor》2023 年 6 月,谷歌 DeepMind 發(fā)布了 AlphaDev,這種全新的強(qiáng)化學(xué)習(xí)系統(tǒng)發(fā)現(xiàn)了一種比以往更快的哈希算法。Julian Schrittwieser 也是 AlphaDev 項(xiàng)目的核心參與者之一。
《AI 重寫排序算法,速度快 70%:DeepMind AlphaDev 革新計(jì)算基礎(chǔ),每天調(diào)用萬(wàn)億次的庫(kù)更新了》2024 年 7 月,谷歌 DeepMind 團(tuán)隊(duì)研發(fā)的 AlphaProof 和 AlphaGeometry 2 在 IMO 競(jìng)賽上共同實(shí)現(xiàn)了里程碑式的突破。AlphaProof 是一種用于形式化數(shù)學(xué)推理的強(qiáng)化學(xué)習(xí)系統(tǒng),而 AlphaGeometry 2 是 DeepMind 幾何求解系統(tǒng) AlphaGeometry 的改進(jìn)版本。正式比賽中,AlphaProof+AlphaGeometry 2 組合成的 AI 系統(tǒng)在幾分鐘內(nèi)就解決了人類參賽選手需要幾個(gè)小時(shí)才能解決的問題。
《谷歌 AI 拿下 IMO 奧數(shù)銀牌,數(shù)學(xué)推理模型 AlphaProof 面世,強(qiáng)化學(xué)習(xí) is so back》8 年前,基于強(qiáng)化學(xué)習(xí)的 AlphaGo 聲名大噪;8 年后,強(qiáng)化學(xué)習(xí)在 AlphaProof 中再次大放異彩。2016 年 AlphaGo 論文的核心成員 Julian Schrittwieser、Aja Huang、Yannick Schroecker,如今也是 AlphaProof 的核心貢獻(xiàn)者。有人在朋友圈感嘆說(shuō):RL is so back!
業(yè)內(nèi)普遍認(rèn)為,OpenAI o1 運(yùn)用的技術(shù)關(guān)鍵也在于強(qiáng)化學(xué)習(xí)的搜索與學(xué)習(xí)機(jī)制,這標(biāo)志著 RL 下 Post-Training Scaling Law 的時(shí)代正式到來(lái)。正如《The Bitter Lesson》所說(shuō),只有搜索和學(xué)習(xí)這兩種學(xué)習(xí)范式能夠隨著計(jì)算能力的增長(zhǎng)無(wú)限擴(kuò)展。強(qiáng)化學(xué)習(xí)作為這兩種學(xué)習(xí)范式的載體,如何能夠在實(shí)現(xiàn)可擴(kuò)展的 RL 學(xué)習(xí)(Scalable RL Learning)和強(qiáng)化學(xué)習(xí)擴(kuò)展法則(RL Scaling Law),將成為進(jìn)一步突破大模型性能上限的關(guān)鍵途徑。
這或許就是 Calude 團(tuán)隊(duì)招攬 Julian Schrittwieser 的出發(fā)點(diǎn)。o1 研發(fā)團(tuán)隊(duì)在采訪中也談到過(guò),OpenAI 很早就受到 AlphaGo 的啟發(fā),意識(shí)到了深度強(qiáng)化學(xué)習(xí)的巨大潛力,并在相關(guān)方向投入了大量研究力量。
作為 RL 領(lǐng)域的深耕者,Julian Schrittwieser 又會(huì)帶領(lǐng) Claude 團(tuán)隊(duì)做出怎樣的成果呢?讓我們拭目以待。
參考鏈接:https://www.furidamu.org/blog/2024/10/28/joining-anthropic/
Tags:
相關(guān)推薦


- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
