

 新火種
2024-09-18
新火種
2024-09-18 


o1突發(fā)內(nèi)幕曝光?谷歌更早揭示原理,大模型光有軟件不存在護(hù)城河
發(fā)布不到1周,OpenAI最強(qiáng)模型o1的護(hù)城河已經(jīng)沒有了。
有人發(fā)現(xiàn),谷歌DeepMind一篇發(fā)表在8月的論文,揭示原理和o1的工作方式幾乎一致。

這項(xiàng)研究表明,增加測(cè)試時(shí)(test-time)計(jì)算比擴(kuò)展模型參數(shù)更有效。
基于論文提出的計(jì)算最優(yōu)(compute-optimal)測(cè)試時(shí)計(jì)算擴(kuò)展策略,規(guī)模較小的基礎(chǔ)模型在一些任務(wù)上可以超越一個(gè)14倍大的模型。
網(wǎng)友表示:
有人由此感慨:
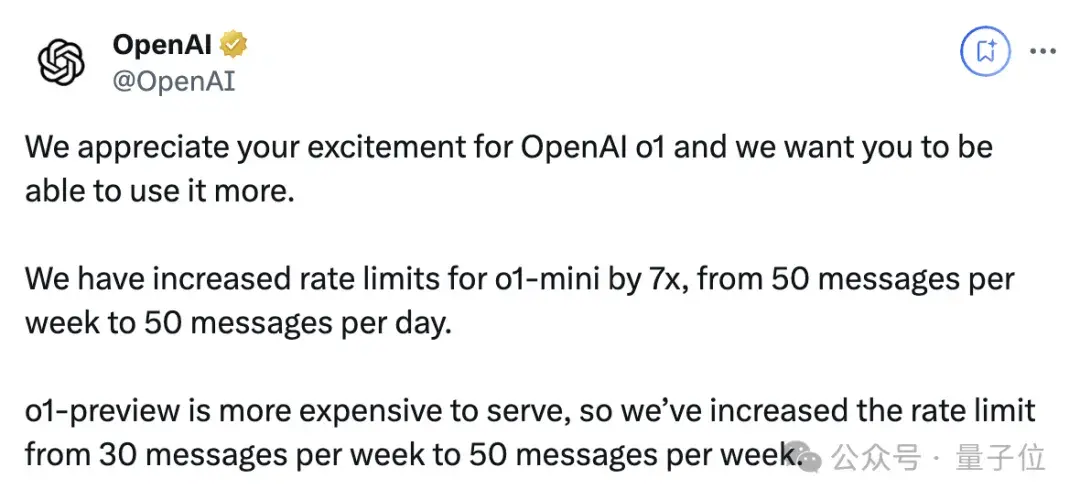
就在剛剛,OpenAI將o1-mini的速度提高7倍,每天都能使用50條;o1-preview則提到每周50條。
 計(jì)算量節(jié)省4倍
計(jì)算量節(jié)省4倍谷歌DeepMind這篇論文的題目是:優(yōu)化LLM測(cè)試時(shí)計(jì)算比擴(kuò)大模型參數(shù)規(guī)模更高效。
研究團(tuán)隊(duì)從人類的思考模式延伸,既然人面對(duì)復(fù)雜問題時(shí)會(huì)用更長(zhǎng)時(shí)間思考改善決策,那么LLM是不是也能如此?
換言之,面對(duì)一個(gè)復(fù)雜任務(wù)時(shí),是否能讓LLM更有效利用測(cè)試時(shí)的額外計(jì)算以提高準(zhǔn)確性。
此前一些研究已經(jīng)論證,這個(gè)方向確實(shí)可行,不過效果比較有限。
因此該研究想要探明,在使用比較少的額外推理計(jì)算時(shí),就能能讓模型性能提升多少?
他們?cè)O(shè)計(jì)了一組實(shí)驗(yàn),使用PaLM2-S*在MATH數(shù)據(jù)集上測(cè)試。
主要分析了兩種方法:
(1)迭代自我修訂:讓模型多次嘗試回答一個(gè)問題,在每次嘗試后進(jìn)行修訂以得到更好的回答。(2)搜索:在這種方法中,模型生成多個(gè)候選答案,

可以看到,使用自我修訂方法時(shí),隨著測(cè)試時(shí)計(jì)算量增加,標(biāo)準(zhǔn)最佳N策略(Best-of-N)與計(jì)算最優(yōu)擴(kuò)展策略之間的差距逐漸擴(kuò)大。
使用搜索方法,計(jì)算最優(yōu)擴(kuò)展策略在初期表現(xiàn)出比較明顯優(yōu)勢(shì)。并在一定情況下,達(dá)到與最佳N策略相同效果,計(jì)算量?jī)H為其1/4。
在與預(yù)訓(xùn)練計(jì)算相當(dāng)?shù)腇LOPs匹配評(píng)估中,對(duì)比PaLM 2-S*(使用計(jì)算最優(yōu)策略)一個(gè)14倍大的預(yù)訓(xùn)練模型(不進(jìn)行額外推理)。
結(jié)果發(fā)現(xiàn),使用自我修訂方法時(shí),當(dāng)推理tokns遠(yuǎn)小于預(yù)訓(xùn)練tokens時(shí),使用測(cè)試時(shí)計(jì)算策略的效果比預(yù)訓(xùn)練效果更好。但是當(dāng)比率增加,或者在更難的問題上,還是預(yù)訓(xùn)練的效果更好。
也就是說,在兩種情況下,根據(jù)不同測(cè)試時(shí)計(jì)算擴(kuò)展方法是否有效,關(guān)鍵在于提示的難度。
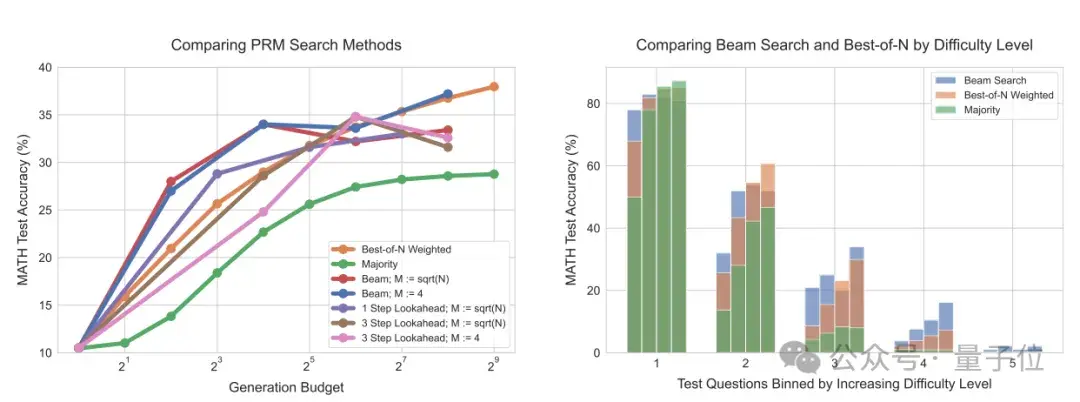
研究還進(jìn)一步比較不同的PRM搜索方法,結(jié)果顯示前向搜索(最右)需要更多的計(jì)算量。
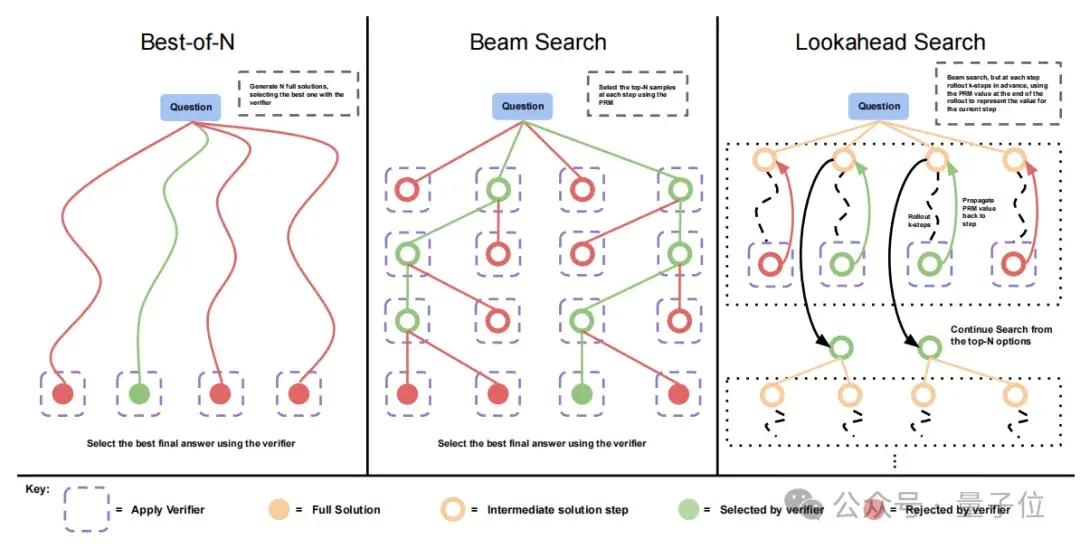
在計(jì)算量較少的情況下,使用計(jì)算最優(yōu)策略最多可節(jié)省4倍資源。
對(duì)比OpenAI的o1模型,這篇研究幾乎是給出了相同的結(jié)論。
o1模型學(xué)會(huì)完善自己的思維過程,嘗試不同的策略,并認(rèn)識(shí)到自己的錯(cuò)誤。并且隨著更多的強(qiáng)化學(xué)習(xí)(訓(xùn)練時(shí)計(jì)算)和更多的思考時(shí)間(測(cè)試時(shí)計(jì)算),o1 的性能持續(xù)提高。
不過OpenAI更快一步發(fā)布了模型,而谷歌這邊使用了PaLM2,在Gemini2上還沒有更新的發(fā)布。
網(wǎng)友:護(hù)城河只剩下硬件了?這樣的新發(fā)現(xiàn)不免讓人想到去年谷歌內(nèi)部文件里提出的觀點(diǎn):
如今來看,各家研究速度都很快,誰(shuí)也不能確保自己始終領(lǐng)先。
唯一的護(hù)城河,或許是硬件。

(所以馬斯克哐哐建算力中心?)
有人表示,現(xiàn)在英偉達(dá)直接掌控誰(shuí)能擁有更多算力。那么如果谷歌/微軟開發(fā)出了效果更好的定制芯片,情況又會(huì)如何呢?
值得一提的是,前段時(shí)間OpenAI首顆芯片曝光,將采用臺(tái)積電最先進(jìn)的A16埃米級(jí)工藝,專為Sora視頻應(yīng)用打造。
顯然,大模型戰(zhàn)場(chǎng),只是卷模型本身已經(jīng)不夠了。
參考鏈接:https://www.reddit.com/r/singularity/comments/1fhx8ny/deepmind_understands_strawberry_there_is_no_moat/
相關(guān)推薦



- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
