

 新火種
2024-03-05
新火種
2024-03-05 


微軟6頁論文爆火:三進制LLM,真香!
金磊 發自 凹非寺新火種 | 公眾號 QbitAI
這就是由微軟和中國科學院大學在最新一項研究中所提出的結論——
所有的LLM,都將是1.58 bit的。

具體而言,這項研究提出的方法叫做BitNet b1.58,可以說是從大語言模型“根兒”上的參數下手。
將傳統以16位浮點數(如FP16或BF16)形式的存儲,統統變成了三進制,也就是 {-1, 0, 1}。
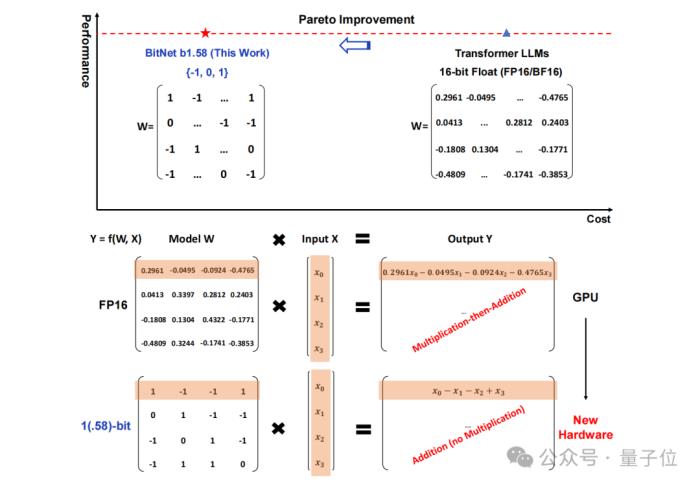
值得注意的是,這里的“1.58 bit”并不是指每個參數占用1.58字節的存儲空間,而是指每個參數可以用1.58位的信息來表示。
在如此轉換之后,矩陣中的計算就只會涉及到整數的加法,因此會讓大模型在保持一定精度的同時,顯著減少所需的存儲空間和計算資源。
例如BitNet b1.58在3B模型大小時與Llama做比較,速度提高了2.71倍的同時,GPU內存使用幾乎僅是原先的四分之一。
而且當模型的規模越大時(例如70B),速度上的提升和內存上的節省就會更加顯著!
這種顛覆傳統的思路著實是讓網友們眼前一亮,論文在X上也是受到了高度的關注:
網友們驚嘆“改變游戲規則”的同時,還玩起了谷歌attention論文的老梗:
那么BitNet b1.58具體又是如何實現的?我們繼續往下看。
把參數變成三進制
這項研究實則是原班人馬在此前發表的一篇論文基礎之上做的優化,即在原始BitNet的基礎上增加了一個額外的0值。

整體來看,BitNet b1.58依舊是基于BitNet架構(一種Transformer),用BitLinear替換了nn.Linear。
至于細節上的優化,首先就是我們剛才提到的“加個0”,即權重量化(weight quantization)。
BitNet b1.58模型的權重被量化為三元值{-1, 0, 1},這相當于在二進制系統中使用了1.58 bit來表示每個權重。這種量化方法減少了模型的內存占用,并簡化了計算過程。

其次,在量化函數設計方面,為了將權重限制在-1、0或+1之間,研究者們采用了一種稱為absmean的量化函數。
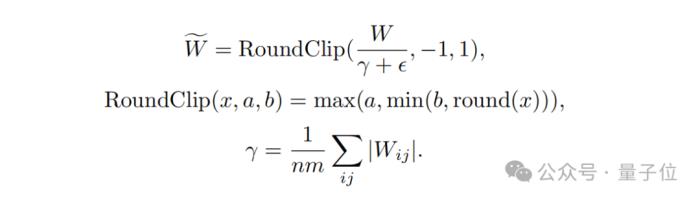
這個函數先會根據權重矩陣的平均絕對值進行縮放,然后將每個值四舍五入到最接近的整數(-1, 0, +1)。
接下來就到了激活量化(activation quantization)這一步。
激活值的量化與BitNet中的實現相同,但在非線性函數之前不將激活值縮放到[0, Qb]的范圍內。相反,激活值被縮放到[?Qb, Qb]的范圍,以此來消除零點量化。
值得一提的是,研究團隊為了BitNet b1.58與開源社區兼容,采用了LLaMA模型的組件,如RMSNorm、SwiGLU等,使得它可以輕松集成到主流開源軟件中。
最后,在實驗的性能比較上,團隊將BitNet b1.58與FP16 LLaMA LLM在不同大小的模型上進行了比較。
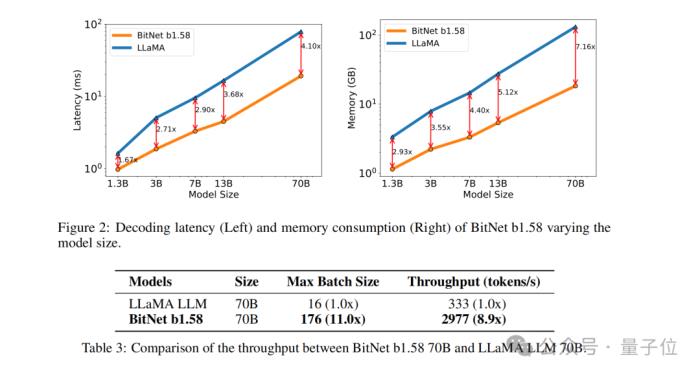
結果顯示,BitNet b1.58在3B模型大小時開始與全精度LLaMA LLM在困惑度上匹配,同時在延遲、內存使用和吞吐量方面有顯著提升。
而且當模型規模越大時,這種性能上提升就會越發顯著。
網友:能在消費級GPU跑120B大模型了
正如上文所言,這篇研究獨特的方法在網上引發了不小的熱議。
DeepLearning.scala作者楊博表示:
與此同時,他也提出了關于BitNet的缺點:

△圖源:知乎,經授權引用
不過也有網友分析認為:
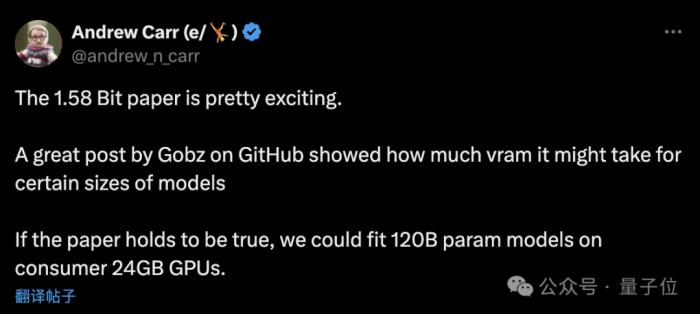
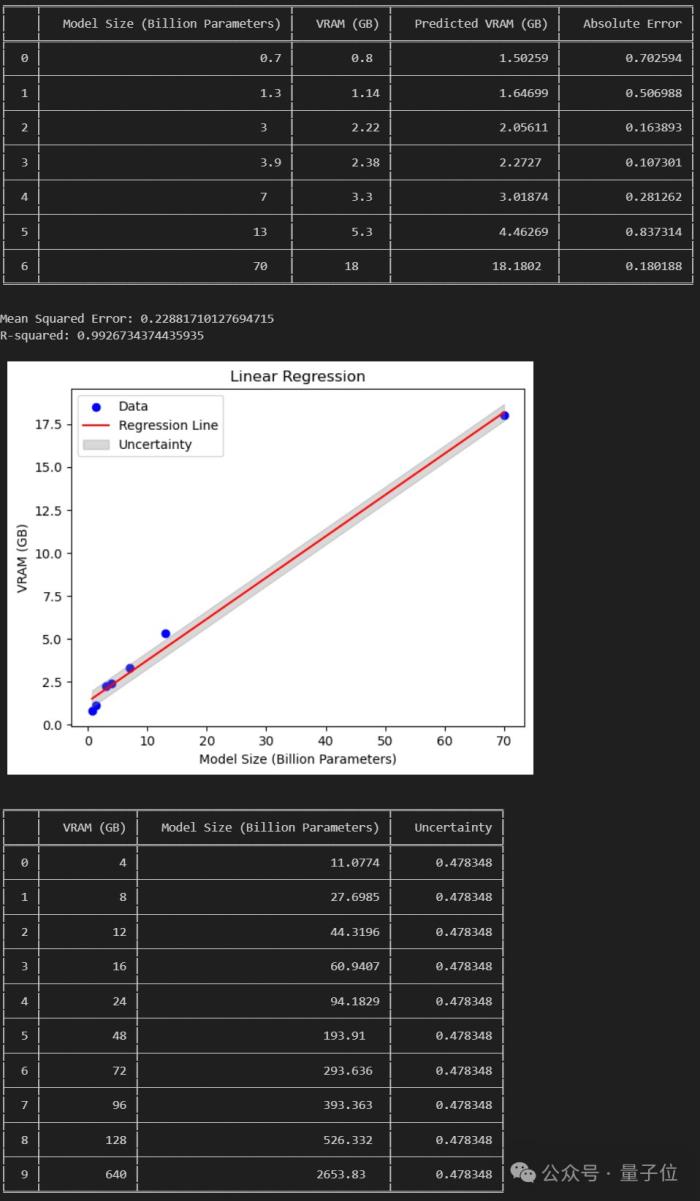
那么你覺得這種新方法如何呢?
Tags:
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
