

 新火種
2024-02-21
新火種
2024-02-21 


GPT-4推理能力暴漲32%,谷歌新型思維鏈效果超CoT,成本降至1/40
GPT-4推理能力還能暴漲32%?
谷歌&南加大推出最新研究“自我發現”(Self-Discover),重新定義了大模型推理范式。
與已成行業標準的思維鏈(CoT)相比,新方法不僅讓模型在面對復雜任務時表現更佳,還把同等效果下的推理成本壓縮至1/40。
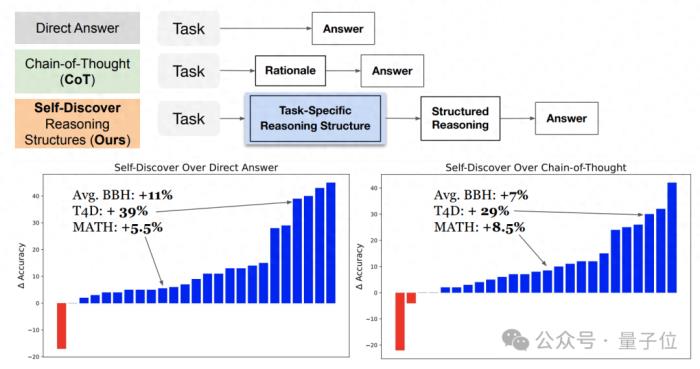
核心策略其實很簡單:千人千面。
讓大模型針對不同問題,提出特定的推理結構。完全不同于以往CoT等方法“千篇一律”的方式。

這種靈活應變的方式,更加貼近于人類的思考模式,也向著期待中的大模型思維方式更進一步。

大模型“千人千面”
一直以來大模型在處理復雜問題時都容易遇到困難,所以一些模擬人類思維能力的提示方法被提出。
最出名的就是思維鏈(CoT),它通過引導大模型“一步一步來”,讓大模型能像人類一樣逐步思考解決問題,最終帶來顯著性能提升。
還有分解法(decomposition-based prompting),它是讓大模型將復雜問題拆解成一個個更小的子問題。
這類方法本身都能充當一個原子推理模塊,對給定任務的處理過程做了先驗假設,也就是讓不同問題都套到同一個流程里解決。
但是不同方法其實都有更擅長和不擅長的領域。比如在解決涉及符號操作等問題時,分解法要優于CoT。
所以研究人員提出,對于每個任務,都應該有獨特的內在推理過程,同時還不提高模型的推理成本。

自發現步驟架構由此而來。
它主要分為兩個階段。
第一階段指導大語言模型從原子推理模塊中進行挑選、調整、整合,搭建出一個可以解決特定任務的推理結構。
比如“創造思維”可能在創作故事任務上有幫助、“反思思考”可能對搜索科學問題有幫助等。大模型需要根據任務進行挑選,然后進一步調整并完成整合。
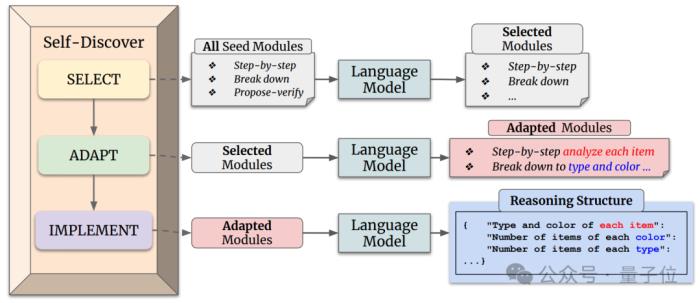
第二階段輸入實例,讓大模型使用第一階段發現的推理結構來生成答案。
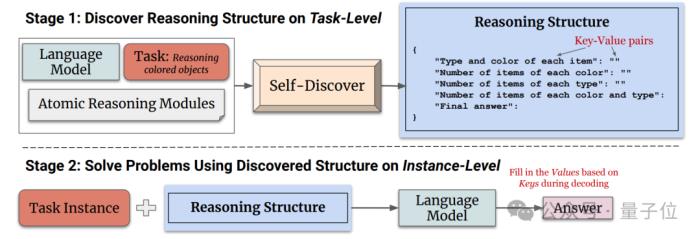
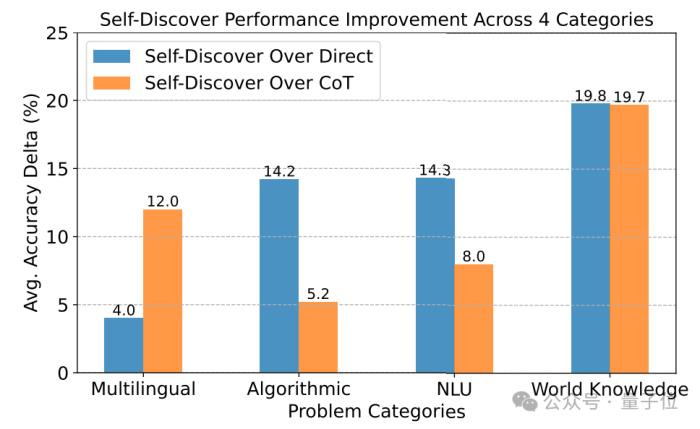
通過在GPT-4和PaLM 2上進行實驗,在BBH、T4D、MATH幾個基準中,使用自發現步驟架構后,模型的性能都有明顯提升。
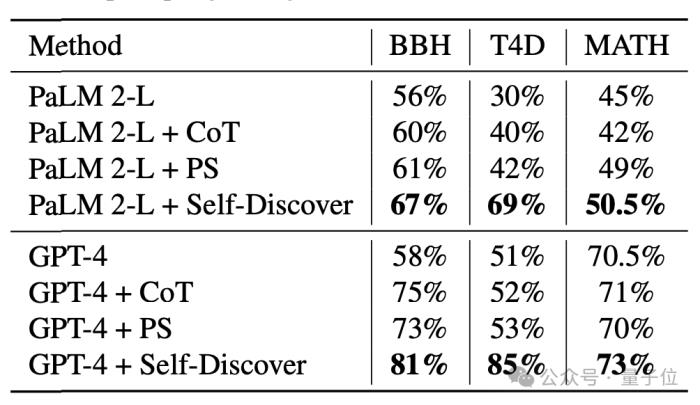
在更細分的測試中,自發現步驟在需要世界知識的任務中表現最好,在算法、自然語言理解上超過CoT。
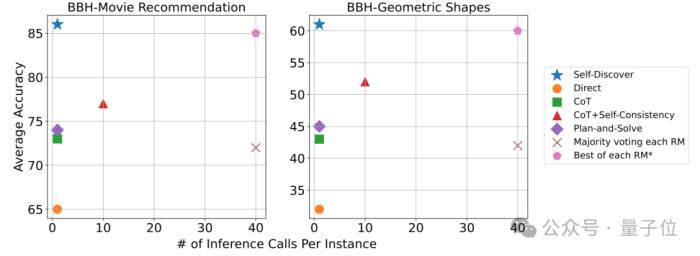
在處理問題的推理調用方面,自發現步驟需要的調用次數明顯少于CoT+Self Consistency,而且準確性更高。
如果想要達到和自發現步驟同樣的準確率,需要的推理計算量則是其40倍。
研究團隊
本項研究由南加州大學和谷歌DeepMind聯合推出。
第一作者是Pei Zhou,他現在正在南加州大學的NLP小組攻讀博士。
兩位通訊作者分別是Huaixiu Zheng和Swaroop Mishra。
Huaixiu Zheng此前參與過谷歌LaMDA工作,這是谷歌一個專攻對話的大模型。
Swaroop Mishra是谷歌DeepMind的研究科學家,它參與的Self-Instruct框架在GitHub上星標3.5k、被引用次數超過600,并被ACL 2023接收。
此外Quoc Le、Denny Zhou等大模型提示微調、推理方向的老面孔也參與其中。
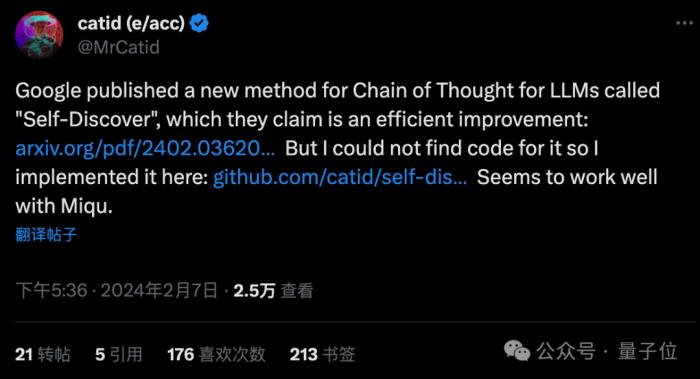
雖然官方暫未開源,但已經有迫不及待的開發者根據論文自行復現了代碼。
發現不僅適用于GPT-4和谷歌PaLM,連Mistral家泄露版模型Miqu上都能很好發揮作用。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
