

 新火種
2024-01-10
新火種
2024-01-10 


OpenAI開撕紐約時報:故意引導ChatGPT得出抄襲結論
OpenAI的反擊來了。
針對被紐約時報提起史上最受關注的侵權訴訟一案,OpenAI公開發表長文表明立場。
文章直接表示:整個訴訟毫無根據,并指出紐約時報:
存在故意引導ChatGPT之嫌疑隱瞞信息,沒有講出完整的事情經過以及OpenAI的總體觀點是:
(1)使用版權數據訓練合理。沒有它們,哪來的當今世界上最先進的模型?(2)如果你不想被訓練?可以退出。單一數據源(包括紐約時報在內)的缺失也不會對模型的表現造成重要影響。
消息一出,吃瓜群眾再次火速聚集,吵成一團。
支持OpenAI的直接“蝦仁豬心”:
有人則問了當事模型GPT-4的看法,結果AI也把紐約時報無情嘲諷了一番:
吳恩達也洋洋灑灑寫了一大堆,總結來說就是:
同情OpenAI多于紐約時報,后者所說的全文抄襲更可能是RAG機制所致,并且實測OpenAI已經堵住漏洞,質疑紐約時報究竟受到了多少實際損失。
不過,反方網友也毫不留情,直接指著鼻子罵:
OpenAI具體回應先來看看OpenAI回應的具體立場,一共包含四個點:
1、非常樂意與新聞機構合作OpenAI表示,自己在技術設計過程中努力行動支持新聞機構,會見了數十家相關媒體,聆聽他們提出的擔憂,并提供解決方案。
其本意也是支持健康的新聞生態系統,并實現互利互惠,具體包括:
(1)通過部署他們的產品,來協助新聞從業者完成一些耗時的任務,比如分析大量公共記錄和翻譯故事,最終讓編輯和記者從中受益。
(2)通過對歷史、非公開內容進行訓練,向他們的AI模型傳授世界知識。
(3)在ChatGPT回答中顯示帶有歸屬信息的實時內容,為新聞發布者與讀者建立聯系。
2、訓練屬于合理使用,提供退出機制OpenAI此前就在提交給英國上議院的一份意見書中警告稱:
如果沒有受版權內容的訓練,我們的模型就將無法運行。
在此,OpenAI再次表示,使用公開的互聯網材料訓練AI模型是合理的,既對創作者公平、對創新者必要,也對國家的競爭力至關重要。
并指出這一觀點已經在美國得到很多團體、學者的支持,在其他國家和地區例如歐盟、日本、新加坡等甚至有法律支持對受版權保護的內容進行訓練。
不過,話鋒一轉,本著“合法權利對我們來說不如成為好公民重要”,OpenAI表示自己提供了一個簡單的退出流程,可以防止他們的AI模型再次訪問這些網站數據。
據介紹,紐約時報已經于2023年8月采用這一機制,退出OpenAI的訓練。
3、“反流”是罕見錯誤,希望用戶也不要故意引導所謂“反流”(Regurgitation),其實就是指模型輸出和訓練數據一模一樣的內容。
紐約時報在訴訟中就列出ChatGPT和該家新聞驚人雷同的情況:
對于這一文縐縐的表達,有網友是不滿的:不就是抄襲(plagarism)嗎?
但不管怎么說,OpenAI的解釋是:
當特定內容在訓練數據中多次出現時就會出現這種罕見的錯誤,不過我們已經采取了措施來防止情況出現。
以及,OpenAI也特別勸誡用戶:
采取負責任的行為,不要故意操縱模型進行反流,這既是對我們技術的不當使用,也違反了我們的使用條款。
然而,馬庫斯和一位數字插畫家幾天前曾聯合撰文,列出包括 DALL-E 3在內的AI模型如何在沒有明確提示的情況下的不少“反芻數據”,也就是給出一些明顯和已有作品場景基本相似的圖片等內容。
而這,就使得OpenAI的說法有些矛盾。
最后,在本段末尾,OpenAI還來了一句:
4、完整故事被隱藏,收到起訴后驚訝又失望OpenAI透露,在去年12月19日時,其實已經和紐約時報取得了建設性談判進展,包括在回答中實時顯示來源和跳轉等,并和紐約時報解釋:
然而OpenAI表示沒想到,12月27號就被直接起訴了,并且還是通過紐約時報的消息才知道——心情整個就是一個既驚訝又失望。
在此,OpenAI指出,對于紐約時報指出的”反流”情況(也就是回答逐字抄寫紐約時報新聞),他們很努力解決這個問題,拿出了誠意,并曾要求后者分享示例,但一再遭到拒絕。
更有趣的是,OpenAI發現,所謂的“反流”內容,其實是多年前多個第三方網站上大量傳播的文章(即并非來自紐約時報)。
以及紐約時報可能涉嫌故意操縱提示詞——放進去大段原文讓模型“上當”。
OpenAI表示,按照他們這么操作,模型其實也并沒有像紐約時報展示的那樣夸張。
這說明:他們要么故意引導模型,要么進行過精挑細選。
綜合以上,OpenAI認為:
不過緩和的場面話也是有的:
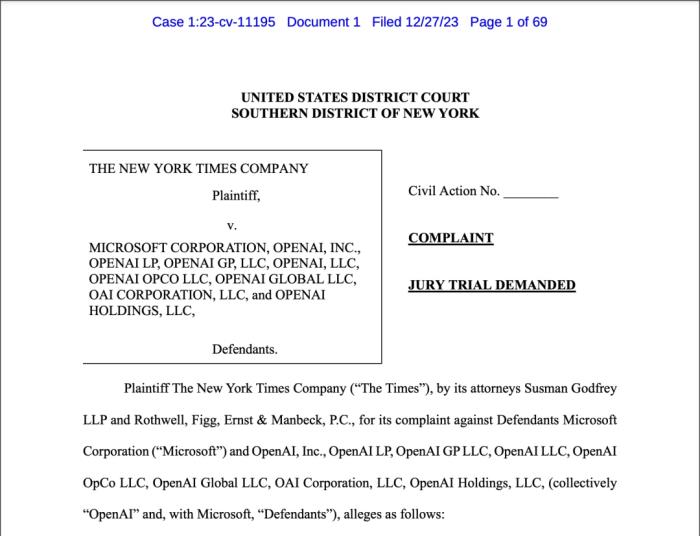
前情回顧去年12月27日,紐約時報突然一紙狀書、220000頁附件,遞交到地方法院狀告OpenAI侵權,當然還包括微軟。
訴狀中指出,紐約時報的文章構成了Common Crawl中用于訓練GPT的最大單個專有數據集。
基于此,他們找到了多達100個鐵證,證明ChatGPT輸出內容與紐約時報新聞內容幾乎一模一樣。
并且有時由于幻覺問題,模型還會以紐約時報的名義“造謠”,生成一些假新聞,例如橙汁會導致淋巴癌,這也對他們的名聲造成了困擾。
對此,紐約時報的訴求是:
要求OpenAI和微軟銷毀包含侵權材料的模型和訓練數據,并對非法復制和使用《紐約時報》獨有價值的作品相關的“數十億美元的法定和實際損失”負責。
由于證據充足、律師團隊強大,網友直呼這是一起“見證AI侵權里程碑式的案件”、“恐怕不能再像之前擺平其他出版商那樣三瓜兩棗就打發了”。
據了解,去年4月份時,紐約時報就與OpenAI談判,但沒談妥,OpenAI拒絕達成協議。
原因可能是金額巨大,特別是考慮到OpenAI利潤的增長以及類似案例的增多。
有一個大膽猜測是,OpenAI可能想用七至八位數金額(百萬美元/千萬美元)解決此事,但紐約時報所追求的是更高的賠償和持續的版稅收入。
Ps. OpenAI年收入在16億美元左右,每年用于買授權文章和材料進行訓練的金額在100萬美元至500萬美元之間。
這次,網友站哪邊?有網友指出,這起案子的關鍵是“訓練是否為合理使用”,而他認為:
但有人諷刺道:
也有人提出:
并有人附和:
此外,對于OpenAI提出的退出機制,有一位作家網友不滿的聲音也得到了很多支持:
結局究竟會如何?
一項調查顯示,有59%的受訪者認為,不應允許人工智能公司使用出版商內容來訓練模型。
而70%的人表示,如果公司想在模型訓練中使用受版權保護的材料,則應向出版商進行補償。
看起來,輿論似乎是站在紐約時報這一邊的。
你覺得這個案子應該怎么判?
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
