

 新火種
2025-05-20
新火種
2025-05-20 


騰訊云論文入選全球頂會SIGCOMM,解決云計算大模型網絡技術痛點
5月19日消息,全球計算機網絡領域頂級會議SIGCOMM近期公布了2025年度首批入選論文名單,騰訊云網絡團隊提交的兩篇論文雙雙入選。兩項技術分別攻克了超大規模云計算網絡性能瓶頸及萬億參數大模型訓練效率難題,標志著騰訊云在云網絡和AI基礎設施領域達到國際領先水平。
SIGCOMM以高影響力和嚴苛的錄取率著稱。自1970年創辦以來,SIGCOMM推動了TCP/IP、SDN、P4可編程網絡等里程碑網絡技術的誕生。SIGCOMM論文被引用率極高,常成為教科書案例。
創新架構設計,支撐超大規模云網絡加速論文《FORNAX:基于智能網卡的大規模VPC會話加速方案》展現了騰訊云基于自研銀杉智能網卡實現超大規模公有云網絡加速的創新解決方案。

騰訊云自研銀杉智能網卡
智能網卡是云網絡加速的重要組件,其加速機制依賴于流表——包含匹配條件和執行策略的規則庫,來指導數據包的轉發、安全控制及網絡優化。因此流表的管理效率,直接關系著網絡的吞吐能力。
傳統方法是依靠軟件來管理硬件中的流表。但在流量激增時,軟件需頻繁更新千萬級流表,易因處理延遲引發丟包或硬件加速策略失效;軟件還需要周期性遍歷流表檢查狀態,效率低且大量占用CPU資源,影響性能。另外,硬件中保存流表的單元容易遇到物理失效,也會影響數據轉發。
騰訊云提出的FORNAX方案是一種硬件原生流表管理架構。與傳統軟件管理方式不同,FORNAX將單向的流表管理升級為雙向的會話管理,聚合會話中的連接狀態、策略版本、校驗碼等元數據,使硬件具備自主感知流量生命周期和策略變化的能力。軟件也不再保存所有流表的細節,而是只保留必要信息,需要時再快速恢復,大大節省資源開銷。
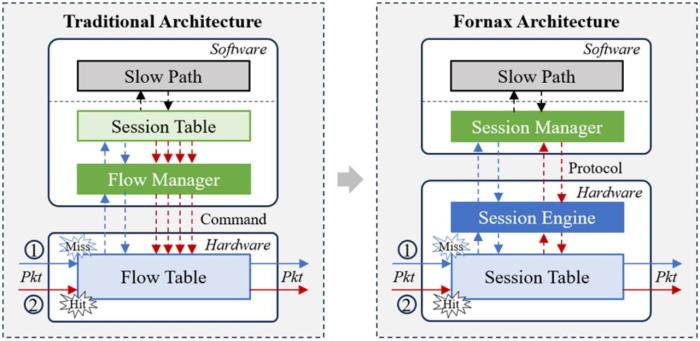
騰訊云硬件原生流表管理架構
為了提高整個系統的容錯性,FORNAX還增加了糾錯碼校驗和硬件轉發掛死檢測機制,一旦識別異常事件,硬件會自動通知軟件系統進行處理,替代軟件方式下的全表掃描,做到精準響應。同時,軟件系統也會定期巡檢硬件會話,支持會話、端口、VPC等多維度和高精度的故障主動發現并切換CPU軟件轉發的能力,能夠在業務無感的情況下處理掉錯誤。
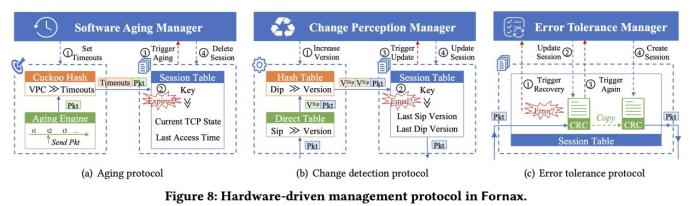
騰訊云軟硬協同會話表容錯管理協議
目前,FORNAX已經在數百萬臺云服務器上運行了兩年多,服務于數十億用戶的網絡流量,并保持因為硬件流表失效引發宕機的0記錄,證明了其有效性和可靠性。
聚焦大模型場景,打造高性能網絡基礎設施另一篇入選論文《星脈:大語言模型訓練的數據中心基礎設施》則介紹了騰訊云專為大模型訓練和推理構建的高性能網絡基礎設施技術方案。
當前,大模型參數從百億進化到萬億級,底層訓練需要超大規模 GPU 集群。但國內GPU資源緊張和性能掣肘,傳統數據中心在網絡架構和高密度部署上存在短板,以及大規模集群中軟硬件故障多和定位難等問題,都對超大規模高性能算力集群建設和維護帶來了不小挑戰。
騰訊云星脈網絡基礎設施方案在網絡架構、硬件、以及集群監控等層面都做了針對性優化。
在網絡架構層,星脈提出了同軌互聯架構,讓同機柜的 GPU 優先在同Pod內直連通信,減少跨 Pod 通信中的性能損耗;同時,星脈支持單Pod 6.4萬塊 GPU互聯,全集群51.2萬塊 GPU組網。在網絡設計上,星脈采用帶寬無瓶頸思路,每一層網絡帶寬都100%匹配GPU需求。
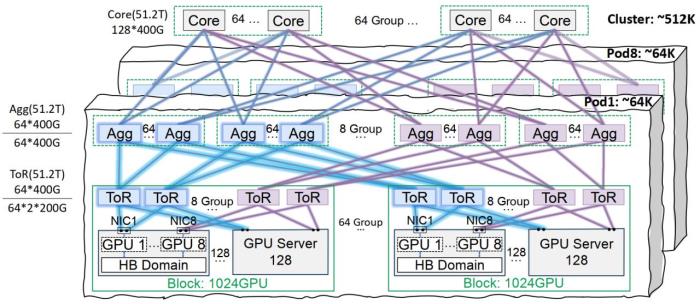
星脈組網架構
星脈還提出全新電源管理與冷卻方案,解決了高密度GPU部署帶來巨大功耗和散熱壓力,提升部署密度,并降低數據中心PUE。針對AI算力集群故障問題,星脈打造智能監控系統給數據中心安裝“全身CT”,實現從硬件到軟件全監控,能將集群故障定位從幾天縮短到幾分鐘。
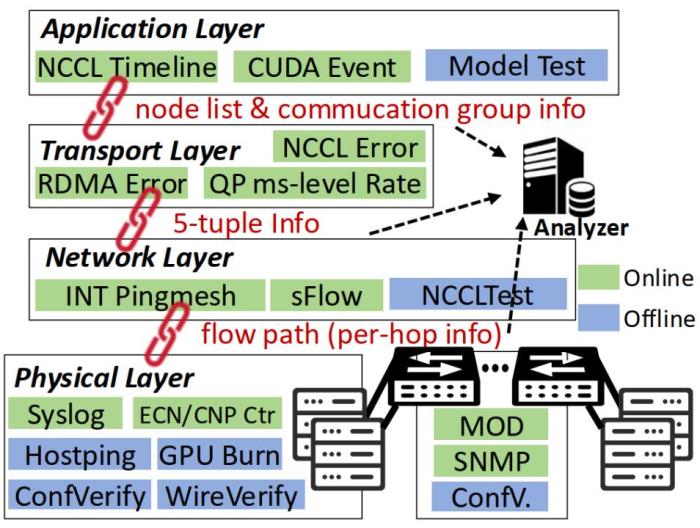
星脈監控系統
同時,星脈打造的性能預測框架,能夠秒級生成每個算子的執行時間,結合實際監控數據校準,能夠保持極小的性能預測誤差,幫助工程師提前發現瓶頸。
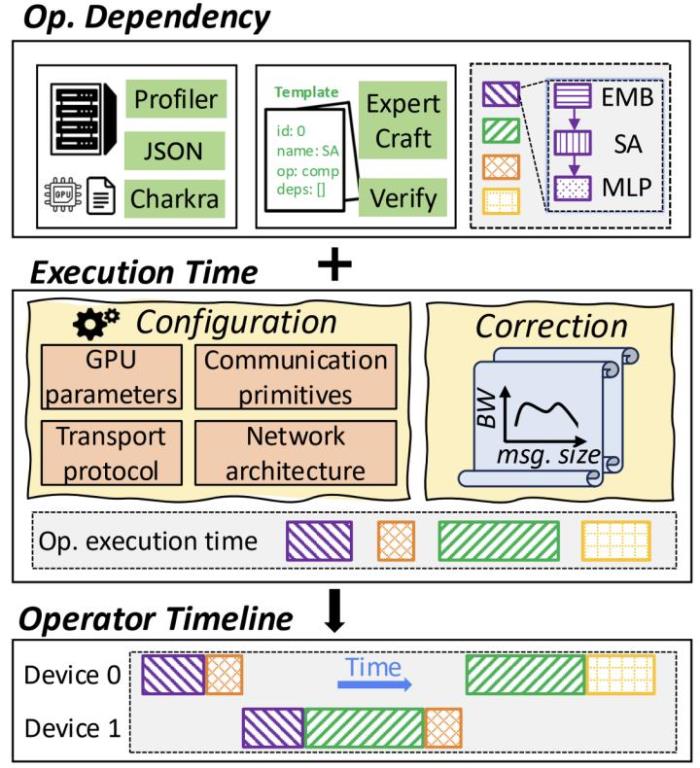
星脈性能預測框架
經過實際部署檢驗,騰訊云星脈在提升訓練效率、降低故障定位時間和提高能源效率方面都表現出色。目前,騰訊云星脈也已經支持了騰訊混元、騰訊元寶、騰訊ima等騰訊自研業務,也服務了大量的產業客戶。
不久前,騰訊云星脈團隊針對DeepSeek開源的DeepEP通信框架進行深度優化,使其在多種網絡環境下均實現顯著性能提升。相關技術方案也獲得了DeepSeek公開致謝,稱這是一次“huge speedup”代碼貢獻。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
