

 新火種
2025-04-03
新火種
2025-04-03 


語音界Deepseek!百度最新跨模態端到端語音交互,成本最高降90%
沒想到,文小言接入推理模型的大更新背后,百度還藏了一手“質變”級技術大招???

士別三日,文小言不僅能講重慶話了,還是成了哄娃的一把好手,被花式打斷照樣應對如流。
實測下來,Demo不虛。這個全新語音對話功能,確實更有人味兒了,還是能緊貼當下實事的那種——
只是讓Ta推薦周末放松去處,Ta自己就能主動結合當前4、5月份的現實時間,給出更加合理的建議。
劃重點,這是免費的。現在你也一樣可以打開手機里的文小言,直接體驗這一全新升級的實時語音對話功能。
但!是!
如果單說語音體驗,那還真不是這個“大招”的重點。關鍵是,這回百度還透露了更多技術細節。
我們仔細一看,還真是有意思了。

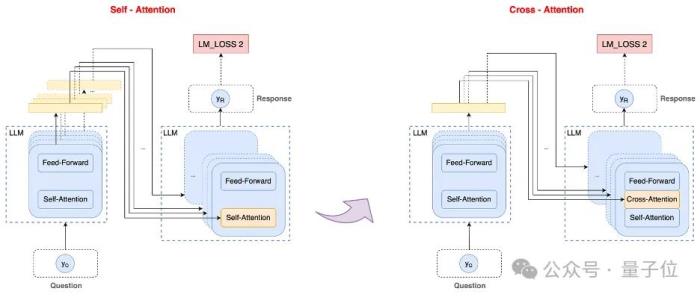
首先,上來就是一個行業首創:以上實時語音對話效果,由百度全新推出的端到端語音語言大模型實現,這是行業首個基于Cross-Attention的跨模態語音語言大模型。
有何不同?站在用戶體驗的角度來說,就是語音合成延遲更低,對話更真實有情感。
而更重要的一點是,這么個新模上線,文小言在語音問答場景中的調用成本,最高能降低90%!直接打掉了工業級落地的門檻。
(再也不怕模型廠流量大到掛我服務.jpg)
我們注意到,百度語音首席架構師賈磊,其實用到了“質變”這個詞:
就是說,這一次語音技術的更新,不僅僅是工程上的技巧,百度正在通過技術創新,打通大模型落地語音場景的工業級應用新范式。
行業首個基于Cross-Attention的端到端語音語言模型話說到這了,咱們就來一起仔細扒一扒背后技術方案,看看究竟是怎么一回事。
先給大家劃個重點:
熟悉大模型的小伙伴都知道,KV cache能夠加速自回歸推理,但其在存儲和訪問上的開銷,也會隨著序列長度和模型規模增大而爆炸式增長。
因此在保證模型性能的前提下,降低KV cache,對于大模型應用來說,是提升推理效率、降低成本的一大關鍵。
百度此次推出的基于Cross-Attention的端到端語音語言模型,重點就在于此。
具體來說,百度做了以下創新:
業內首創的基于Cross-Attention的跨模態語音語言大模型Encoder和語音識別過程融合,降低KV計算Decoder和語音合成模型融合創新提出基于Cross-Attention的高效全查詢注意力技術(EALLQA),降低KV cache我們一項一項展開來看。
基于Cross-Attention的跨模態語音語言大模型
整體上,這個端到端語音語言大模型是基于Self-Attention的文心預訓練大模型,采用自蒸餾的方式進行后訓練得到。訓練數據為文本和語音合成數據的混合。整個模型采用MoE結構。
關鍵點在于,在端到端語音識別中,聲學模型也是語言模型,因此在整合語音識別和大語言模型的過程中,能夠通過將大語言模型中的Encoder和語音識別的過程融合共享,達到降低語音交互硬延遲的目的。
而在語音領域,Cross-Attention天然具有跨模態優勢:Decoder會顯式地將Encoder輸出納入注意力計算,使得Decoder在每一個解碼步驟都能動態訪問最相關的輸入向量,從而充分地對齊和利用跨模態信息。
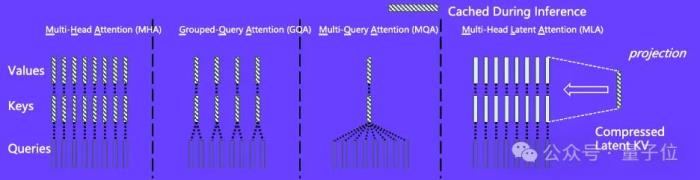
基于Cross-Attention的高效全查詢注意力技術(EALLQA)
不過,Cross-Attention的引入帶來了另一個問題:MLA的位置編碼技術,在Cross-Attention中容易出現不穩定的現象。
為此,百度語音團隊提出了高效全查詢注意力技術(EALLQA):
采用創新的隱式RNN兩級位置編碼,訓練時是在128空間上的MHA,推理時是在模型各層共享的512空間上的MQA(AllQA)。既充分利用了有限的訓練資源,也極大地降低了推理成本。
從具體效果上來說,EALLQA技術能使KV cache降至原來的幾十分之一,并將Cross-Attention的最近上一個問題的KV計算降至原來的十分之一,極大降低了語音交互時用戶的等待時間和模型推理成本。
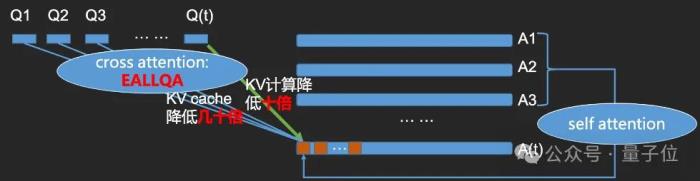
降低成本的另一個關鍵,則是Encoder和語音識別系統的融合:對Query理解的模型較小,能極大減少KV計算。
流式逐字的LLM驅動的多情感語音合成
訓練、推理成本的降低之外,端到端語音語言大模型還通過語音模型和語言模型的融合,實現了文體恰當、情感契合、自然流暢的合成音頻的生成。
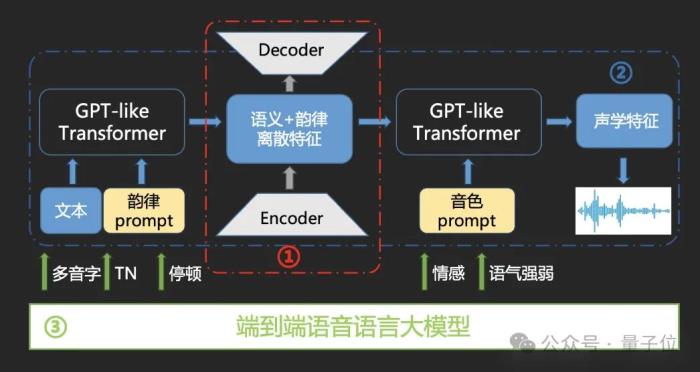
一方面,研發團隊通過大規模文本-語音數據自監督預訓練,構建語義+韻律的離散化特征空間,通過雙層GPT-like Transformer,實現了韻律、音色雙Prompt控制機制。
另一方面,在此基礎之上,研發團隊推出了語音語言大模型與合成一體化流式逐字合成。
有別于傳統語音合成的整句輸出,流式逐字相當于一個字一個字地合成。在這個過程中,語言大模型能夠指導語音模型去生成情感、停頓,識別多音字等等,實現更為擬人、自然的語音合成效果。
需要注意的是,人耳接收信息實際上是一個字一個字地接收,但對于AI而言,如果1個token接1個token的輸出,就需要解決并發的問題,以使MoE架構最大程度發揮作用。
流式逐字合成要解決的核心問題,就是在適配人聽力的基礎上,實現高并發。
通過引入流式逐字合成,百度端到端語音語言大模型有效提升了語音交互的響應速度,同時降低了語音交互領域使用大模型成本。與大模型融合的TTS文體風格情緒控制,還可以根據文本輸出自適配的情況,情感覆蓋達到17種。

簡單總結一下,百度的端到端語音語言大模型,一方面是重點解決了大模型應用于語音交互場景成本高、速度慢的問題。
另一方面,大語言模型帶來的語義理解等能力,也解決了傳統語音交互中,同音字識別、打斷、真實情感等痛點。
賈磊透露,目前,整個端到端語音語言大模型在L20卡上即可部署,在滿足語音交互硬延遲要求的情況下,雙L20卡并發可以做到數百以上。
極低成本是關鍵說了這么多,最主要的關鍵詞其實就是:低成本。
在與賈磊的進一步交流中,他向我們強調了降低成本的重要性:
在不考慮計算資源的情況下,實時語音交互有其他路徑可以實現,但“我們今天是第一個做到跨模態端到端極低成本解決語音問題的”。

賈磊還表示,希望語音領域的這一突破創新能被行業更多地關注到。
事實上,不僅是百度,在包含語音的大模型能力對外輸出上,國內外廠商都將價格視作突破口。
OpenAI就專門從性價比出發,推出了GPT-4o mini audio,希望以更低廉的價格打入語音應用市場。
2025年,基礎模型方面,模型廠商在推理模型上爭相競逐,而其帶來的最直接的影響之一,是人們對于大模型應用加速爆發預期的持續升溫。在這個過程中,我們可以看到,站在模型廠商的角度,更多的模型在被開源,更多的服務在免費開放,用戶認知、關注的爭奪之中,成本本身正在變得更加敏感。
更不用提成本即是大規模應用的關鍵:不僅是在模型廠商們的APP上,還要進一步走進手機、汽車……
正如DeepSeek在基礎模型領域攪動池水,現在,百度也在語音領域邁出關鍵一步。
成本,正在成為當前階段模型廠商獲得主動權的重要突破口。
One More Thing從文小言的語音交互架構圖中還可以看到,它像是個語音版百度搜索。
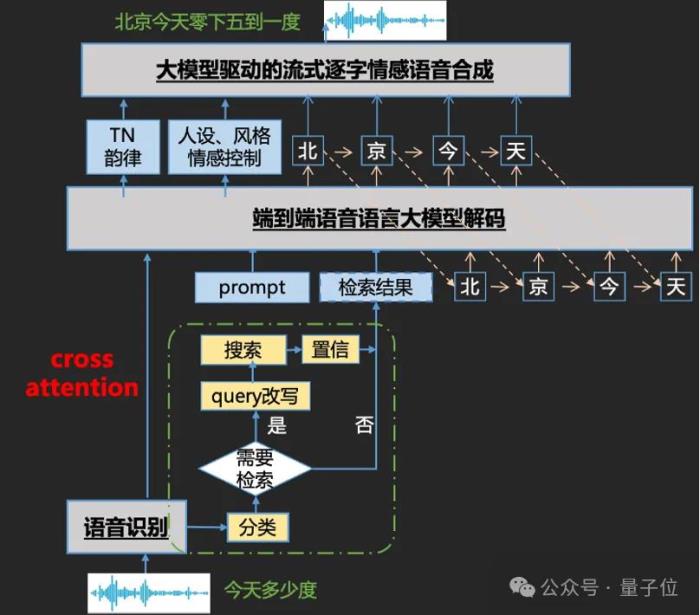
正如文章開篇我們體驗到的,文小言能結合當前的季節對用戶問題給出更合理的回答。實際上,在語音功能中,文小言已經支持多垂類助手能力,包括天氣、日歷查詢、單位換算、股價股票等信息查詢內容,共計38個垂類。
還支持DeepQA RAG問答,包含百度查詢等時效性問答內容,能結合檢索結果,做到更精準的指令跟隨;支持DeepQA非RAG問答,包含常識問答等非時效性問答內容。
“有問題,問小言”的這個“問”字,確實是越來越接近人類原本的交互習慣了。
這實際也是產業趨勢的一種映射——
之前都是大模型技術探索,需要不斷適配才能落地產品、形成應用,最后被用戶感知。
現在這是大模型技術和產品應用,幾乎在同時對齊,技術推進的時候就瞄準了應用場景,應用場景也能催生更適合的技術,不是錘子找釘子,而是錘子釘子同時對齊。
大模型依然是AI世界的核心,但天下卻正在變成應用為王的天下。
百度,或者說中國AI玩家,開始找到自己的節奏了。
— 完 —
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
