

 新火種
2024-12-18
新火種
2024-12-18 

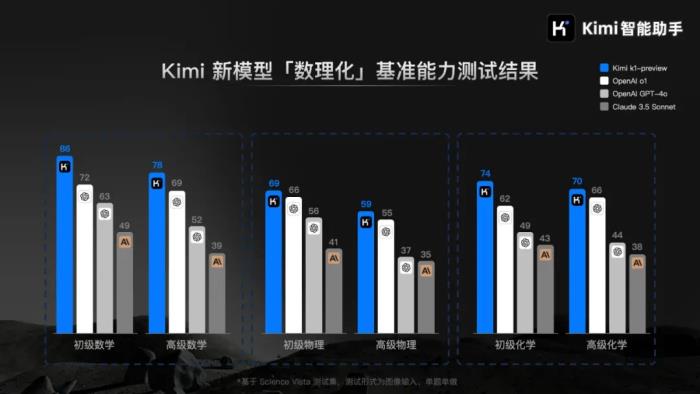
3B模型長思考后擊敗70B!HuggingFace逆向出o1背后技術細節并開源
如果給小模型更長的思考時間,它們性能可以超越更大規模的模型。
最近一段時間,業內對小模型的研究熱情空前地高漲,通過一些「實用技巧」讓它們在性能上超越更大規模的模型。
可以說,將目光放到提升較小模型的性能上來有其必然性。對于大語言模型而言,訓練時計算(train-time compute)的擴展主導了它們的發展。盡管這種模式已被證明非常有效,但越來越大模型的預訓練所需的資源卻變得異常昂貴,數十億美元的集群已經出現。
因此,這一趨勢引發了人們對另外一種互補方法的極大興趣,即測試時計算擴展(test-time compute scaling)。測試時方法不依賴于越來越大的預訓練預算,而是使用動態推理策略,讓模型在更難的問題上「思考更長時間」。一個突出的例子是 OpenAI 的 o1 模型,隨著測試時計算量的增加,它在困難數學問題上表現出持續的進步。

雖然我們不清楚 o1 是如何訓練的,但 DeepMind 最近的研究表明,可以通過迭代自我改進或使用獎勵模型在解決方案空間上進行搜索等策略來實現測試時計算的最佳擴展。通過自適應地按 prompt 分配測試時計算,較小的模型可以與較大、資源密集型模型相媲美,有時甚至超越它們。當內存受限且可用硬件不足以運行較大模型時,擴展時間時計算尤其有利。然而這種有前途的方法是用閉源模型演示的,沒有發布任何實現細節或代碼。
DeepMind 論文:https://arxiv.org/pdf/2408.03314
在過去幾個月里,HuggingFace 一直在深入研究,試圖對這些結果進行逆向工程并復現。他們在這篇博文將介紹:
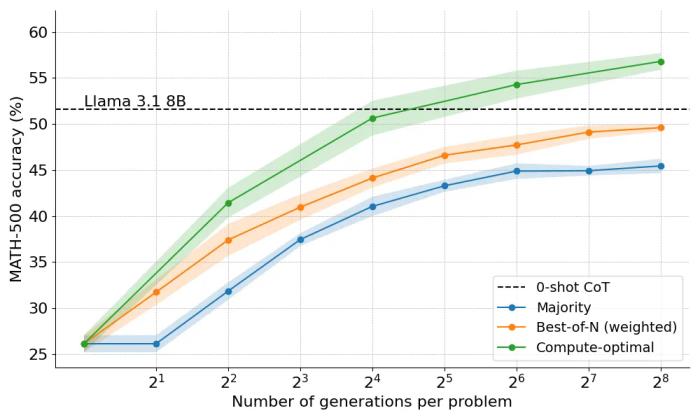
計算最優擴展(compute-optimal scaling):通過實現 DeepMind 的技巧來提升測試時開放模型的數學能力。多樣性驗證器樹搜索 (DVTS):它是為驗證器引導樹搜索技術開發的擴展。這種簡單高效的方法提高了多樣性并提供了更好的性能,特別是在測試時計算預算較大的情況下。搜索和學習:一個輕量級工具包,用于使用 LLM 實現搜索策略,并使用 vLLM 實現速度提升。那么,計算最優擴展在實踐中效果如何呢?在下圖中,如果你給它們足夠的「思考時間」,規模很小的 1B 和 3B Llama Instruct 模型在具有挑戰性的 MATH-500 基準上,超越了比它們大得多的 8B、70B 模型。
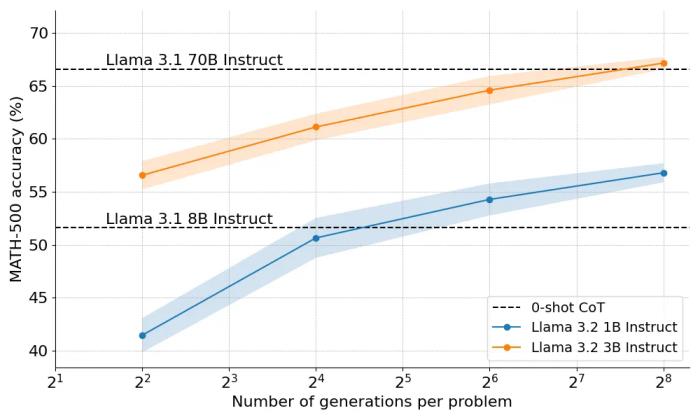
HuggingFace 聯合創始人兼 CEO Clem Delangue 表示,在 OpenAI o1 公開亮相僅 10 天后,我們很高興地揭曉了其成功背后的突破性技術的開源版本:擴展測試時計算。通過給模型更長的「思考時間」,1B 模型可以擊敗 8B、3B 模型可以擊敗 70B。當然,完整的技術配方是開源的。
各路網友看到這些結果也不淡定了,直呼不可思議,并認為這是小模型的勝利。
接下來,HuggingFace 深入探討了產生上述結果背后的原因,并幫助讀者了解實現測試時計算擴展的實用策略。
擴展測試時計算策略
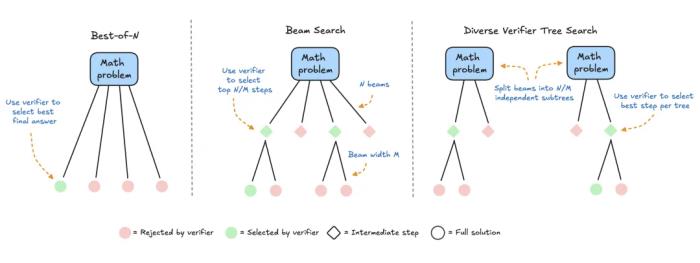
擴展測試時計算主要有以下兩種主要策略:
自我改進:模型通過在后續迭代中識別和糾錯來迭代改進自己的輸出或「想法」。雖然這種策略在某些任務上有效,但通常要求模型具有內置的自我改進機制,這可能會限制其適用性。針對驗證器進行搜索:這種方法側重于生成多個候選答案并使用驗證器選擇最佳答案。驗證器可以是基于硬編碼的啟發式方法,也可以是學得的獎勵模型。本文將重點介紹學得的驗證器,它包括了 Best-of-N 采樣和樹搜索等技術。這種搜索策略更靈活,可以適應問題的難度,不過它們的性能受到驗證器質量的限制。HuggingFace 專注于基于搜索的方法,它們是測試時計算優化的實用且可擴展的解決方案。下面是三種策略:
實驗設置
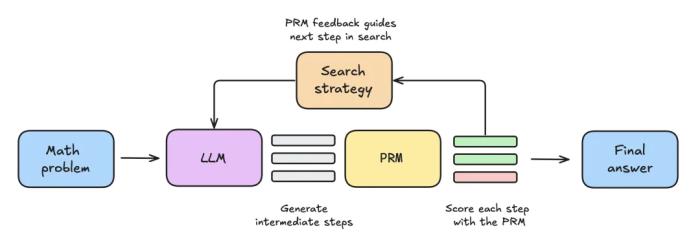
實驗設置包括以下步驟:
首先給 LLM 提供一個數學問題,讓其生成 N 個部分解,例如,推導過程中的中間步驟。每個 step 都由 PRM 評分,PRM 估計每個步驟最終達到正確答案的概率。一旦搜索策略結束,最終候選解決方案將由 PRM 排序以產生最終答案。為了比較各種搜索策略,本文使用了以下開源模型和數據集:
模型:使用 meta-llama/Llama-3.2-1B-Instruct 為主要模型,用于擴展測試時計算;過程獎勵模型 PRM:為了指導搜索策略,本文使用了 RLHFlow/Llama3.1-8B-PRM-Deepseek-Data,這是一個經過過程監督訓練的 80 億獎勵模型。過程監督是一種訓練方法,模型在推理過程的每一步都會收到反饋,而不僅僅是最終結果;數據集:本文在 MATH-500 子集上進行了評估,這是 OpenAI 作為過程監督研究的一部分發布的 MATH 基準數據集。這些數學問題涵蓋了七個科目,對人類和大多數大語言模型來說都具有挑戰性。本文將從一個簡單的基線開始,然后逐步結合其他技術來提高性能。
多數投票
多數投票是聚合 LLM 輸出的最直接方法。對于給定的數學問題,會生成 N 個候選解,然后選擇出現頻率最高的答案。在所有的實驗中,本文采樣了多達 N=256 個候選解,溫度參數 T=0.8,并為每個問題生成了最多 2048 個 token。
以下是多數投票應用于 Llama 3.2 1B Instruct 時的表現:
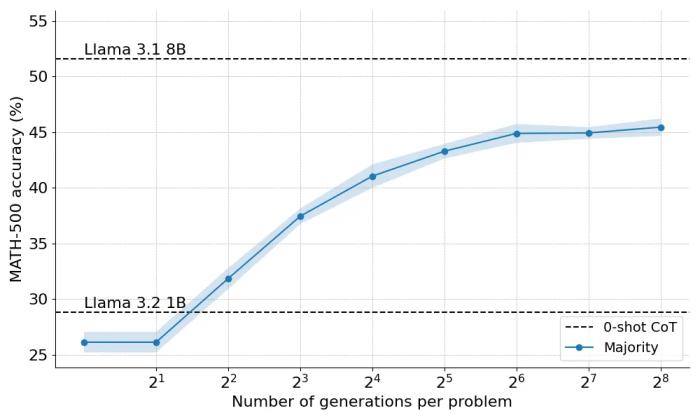
結果表明,多數投票比貪婪解碼基線有顯著的改進,但其收益在大約 N=64 generation 后開始趨于平穩。這種限制的出現是因為多數投票難以解決需要細致推理的問題。
基于多數投票的局限性,讓我們看看如何結合獎勵模型來提高性能。
超越多數:Best-of-N
Best-of-N 是多數投票算法的簡單且有效的擴展,它使用獎勵模型來確定最合理的答案。該方法有兩種主要變體:
普通的 Best-of-N:生成 N 個獨立響應,選擇 RM 獎勵最高的一個作為最終回答。這確保了選擇置信度最高的響應,但它并沒有考慮到回答之間的一致性。
加權 Best-of-N:匯總所有相同響應的得分,并選擇總獎勵最高的回答。這種方法通過重復出現來提高分數,從而優先考慮高質量的回答。從數學上講,回答的權重 a_i:
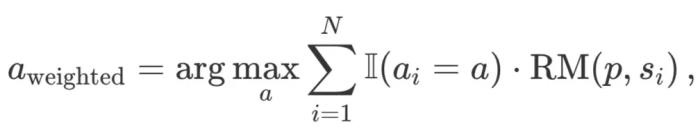
其中,RM (p,s_i) 是對于問題 p 的第 i 個解決方案 s_i 的獎勵模型分數。
通常,人們使用結果獎勵模型 (ORM) 來獲得單個解決方案級別的分數。但為了與其他搜索策略進行公平比較,使用相同的 PRM 對 Best-of-N 的解決方案進行評分。如下圖所示,PRM 為每個解決方案生成一個累積的步驟級分數序列,因此需要對步驟進行規約(reduction)以獲得單個解決方案級分數:
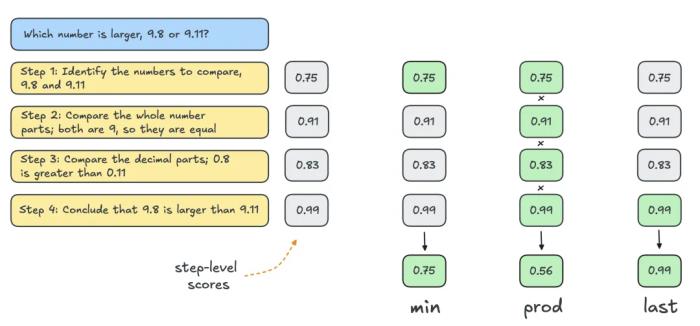
最常見的規約如下:
Min:使用所有步驟中的最低分數。
Prod:使用階梯分數的乘積。
Last:使用步驟中的最終分數。該分數包含所有先前步驟的累積信息,因此將 PRM 有效地視為能夠對部分解決方案進行評分的 ORM。
以下是應用 Best-of-N 的兩種變體得到的結果:
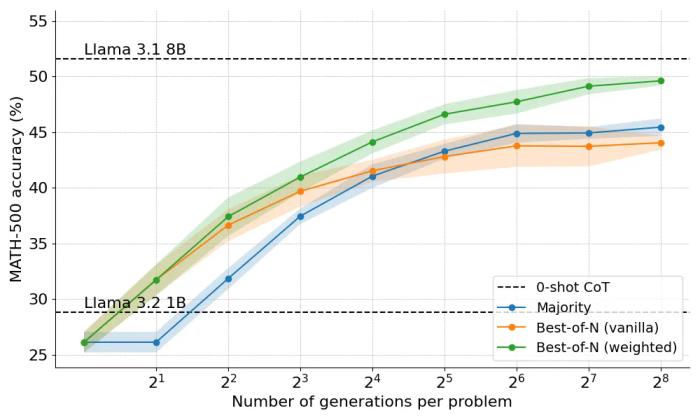
結果揭示了一個明顯的優勢:加權的 Best-of-N 始終優于普通的 Best-of-N,特別是在發電預算較大的情況下。它能夠匯總相同答案的分數,確保即使頻率較低但質量較高的答案也能得到有效的優先處理。
然而,盡管有這些改進,仍然達不到 Llama 8B 模型所達到的性能,并且在 N=256 時 Best-of-N 方法開始趨于穩定。
可以通過逐步監督搜索過程來進一步突破界限嗎?
使用 PRM 的集束搜索
作為一種結構化搜索方法,集束搜索可以系統地探索解決方案空間,使其成為在測試時改進模型輸出的強大工具。與 PRM 結合使用時,集束搜索可以優化問題解決中中間步驟的生成和評估。集束搜索的工作方式如下:
通過保持固定數量的「集束」或活動路徑 N ,迭代生成多個候選解決方案。在第一次迭代中,從溫度為 T 的 LLM 中抽取 N 個獨立步驟,以引入響應的多樣性。這些步驟通常由停止標準定義,例如終止于新行 \n 或雙新行 \n\n。使用 PRM 對每個步驟進行評分,并選擇前 N/M 個步驟作為下一輪生成的候選。這里 M 表示給定活動路徑的「集束寬度」。與 Best-of-N 一樣,使用「最后」的規約來對每次迭代的部分解決方案進行評分。通過在解決方案中采樣 M 個后續步驟來擴展在步驟 (3) 中選擇的步驟。重復步驟 (3) 和 (4),直到達到 EOS token 或超過最大搜索深度。通過允許 PRM 評估中間步驟的正確性,集束搜索可以在流程早期識別并優先考慮有希望的路徑。這種逐步評估策略對于數學等復雜的推理任務特別有用,這是因為驗證部分解決方案可以顯著改善最終結果。
實現細節
在實驗中,HuggingFace 遵循 DeepMind 的超參數選擇,并按照以下方式運行集束搜索:
計算擴展為 4、16、64、256 時的 N 個集束固定集束寬度 M=4在溫度 T=0.8 時采樣最多 40 次迭代,即最大深度為 40 步的樹如下圖所示,結果令人震驚:在 N=4 的測試時預算下,集束搜索實現了與 N=16 時 Best-of-N 相同的準確率,即計算效率提高了 4 倍!此外,集束搜索的性能與 Llama 3.1 8B 相當,每個問題僅需 N=32 解決方案。計算機科學博士生在數學方面的平均表現約為 40%,因此對于 1B 模型來說,接近 55% 已經很不錯了!
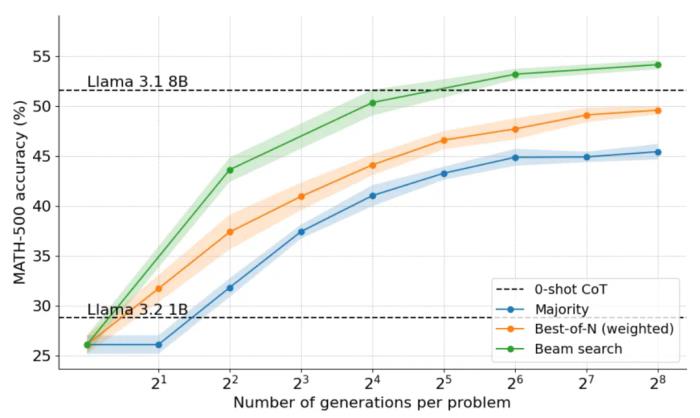
哪些問題集束搜索解決得最好
雖然總體上很明顯,集束搜索是一種比 Best-of-N 或多數投票更好的搜索策略,但 DeepMind 的論文表明,每種策略都有權衡,這取決于問題的難度和測試時計算預算。
為了了解哪些問題最適合哪種策略,DeepMind 計算了估計問題難度的分布,并將結果分成五等分。換句話說,每個問題被分配到 5 個級別之一,其中級別 1 表示較容易的問題,級別 5 表示最難的問題。為了估計問題難度,DeepMind 為每個問題生成了 2048 個候選解決方案,并進行了標準采樣,然后提出了以下啟發式方法:
Oracle:使用基本事實標簽估計每個問題的 pass@1 分數,對 pass@1 分數的分布進行分類以確定五分位數。模型:使用每個問題的平均 PRM 分數分布來確定五分位數。這里的直覺是:更難的問題分數會更低。下圖是根據 pass@1 分數和四個測試時計算預算 N=[4,16,64,256] 對各種方法的細分:
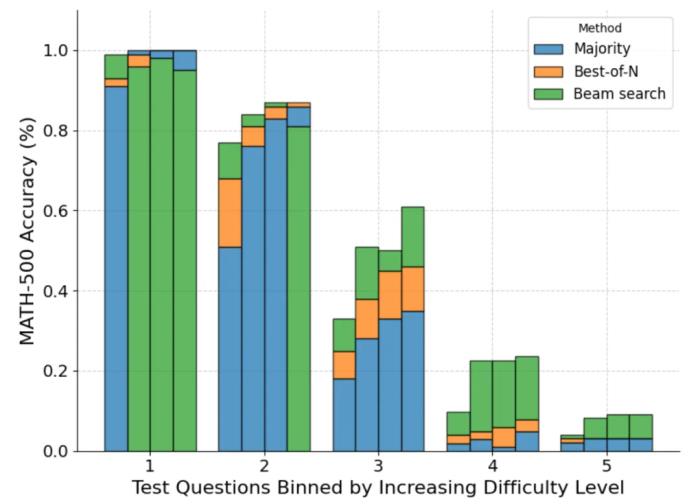
可以看到,每個條形表示測試時計算預算,并且在每個條形內顯示每種方法的相對準確度。例如在難度等級 2 的四個條形中:
多數投票是所有計算預算中表現最差的方法,除了 N=256(集束搜索表現最差)。
集束搜索最適合 N=[4,16,64],但 Best-of-N 最適合 N=256。
應該說,集束搜索在中等難度和困難難度問題(3-5 級)中取得了持續的進展,但在較簡單問題上,尤其是在計算預算較大的情況下,它的表現往往比 Best-of-N(甚至多數投票)更差。
通過觀察集束搜索生成的結果樹,HuggingFace 意識到,如果單個步驟被分配了高獎勵,那么整棵樹就在該軌跡上崩潰,從而影響多樣性。這促使他們探索一種最大化多樣性的集束搜索擴展。
DVTS:通過多樣性提升性能
正如上面所看到的,集束搜索比 Best-of-N 具有更好的性能,但在處理簡單問題和測試時計算預算較大時往往表現不佳。
為了解決這個問題,HuggingFace 開發了一個擴展,稱之為「多樣性驗證器樹搜索」(DVTS),旨在最大限度地提高 N 較大時的多樣性。
DVTS 的工作方式與集束搜索類似,但有以下修改:
對于給定的 N 和 M,將初始集束擴展為 N/M 個獨立子樹。對于每個子樹,選擇具有最高 PRM 分數的步驟。從步驟 (2) 中選擇的節點生成 M 個新步驟,并選擇具有最高 PRM 分數的步驟。重復步驟 (3),直到達到 EOS token 或最大樹深度。下圖是將 DVTS 應用于 Llama 1B 的結果:
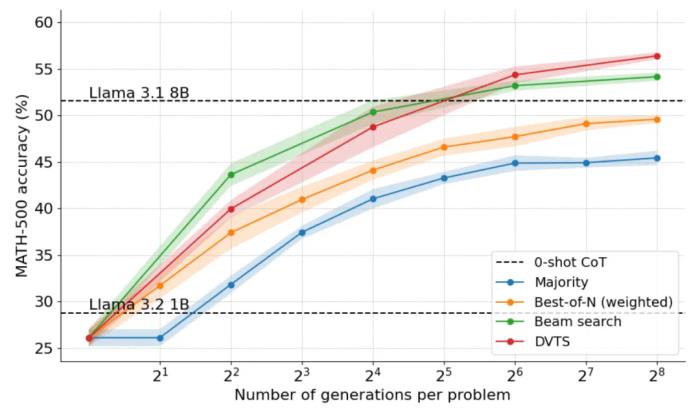
可以看到,DVTS 為集束搜索提供了一種補充策略:在 N 較小時,集束搜索更有效地找到正確的解決方案;但在 N 較大時,DVTS 候選的多樣性開始發揮作用,可以獲得更好的性能。
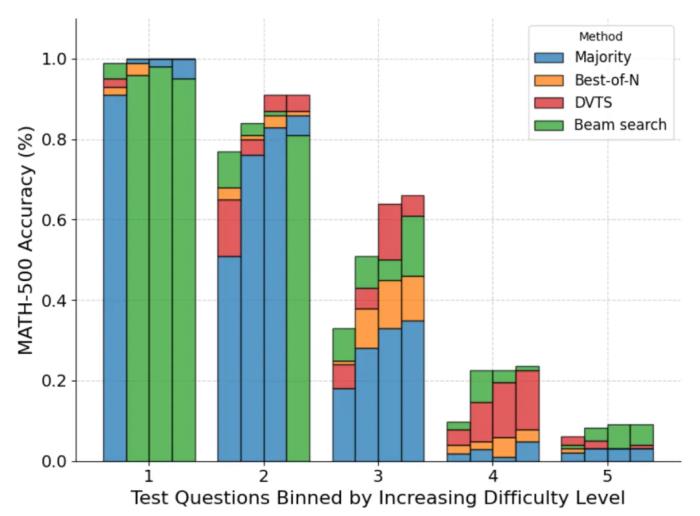
此外在問題難度細分中,DVTS 在 N 較大時提高了簡單 / 中等問題的性能,而集束搜索在 N 較小時表現最佳。
計算 - 最優擴展(compute-optimal scaling)
有了各種各樣的搜索策略,一個自然的問題是哪一個是最好的?在 DeepMind 的論文中(可參考《Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters 》),他們提出了一種計算 - 最優擴展策略,該策略可以選擇搜索方法和超參數 θ,以便在給定的計算預算 N 下達到最佳性能:
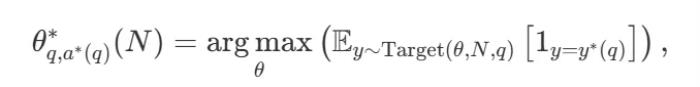
其中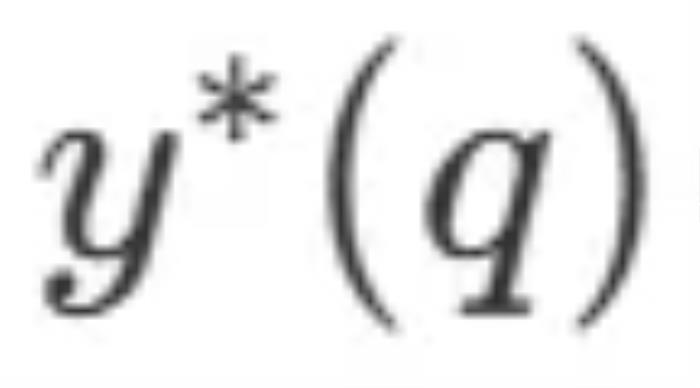 是問題 q 的正確答案。
是問題 q 的正確答案。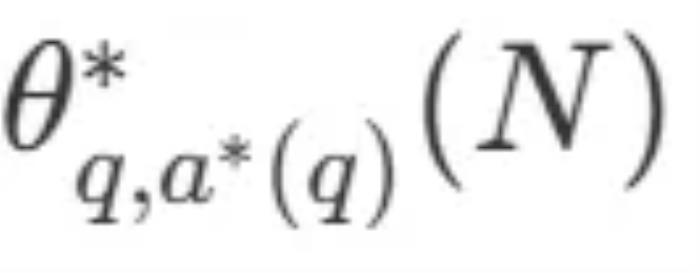 表示計算 - 最優的擴展策略。由于直接計算
表示計算 - 最優的擴展策略。由于直接計算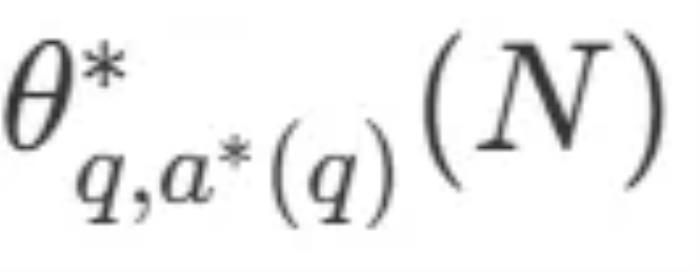 有些棘手,DeepMind 提出了一種基于問題難度的近似方法,即根據哪種搜索策略在給定難度級別上達到最佳性能來分配測試時的計算資源。
有些棘手,DeepMind 提出了一種基于問題難度的近似方法,即根據哪種搜索策略在給定難度級別上達到最佳性能來分配測試時的計算資源。
例如,對于較簡單的問題和較低的計算預算,最好使用 Best-of-N 等策略,而對于較難的問題,集 shu 搜索是更好的選擇。下圖為計算 - 最優曲線!
擴展到更大的模型
本文還探索了將計算 - 最優(compute-optimal)的方法擴展到 Llama 3.2 3B Instruct 模型,以觀察 PRM 在與策略自身容量相比時在哪個點開始減弱。結果顯示,計算 - 最優的擴展效果非常好,3B 模型的性能超過了 Llama 3.1 70B Instruct(后者是前者大小的 22 倍!)。
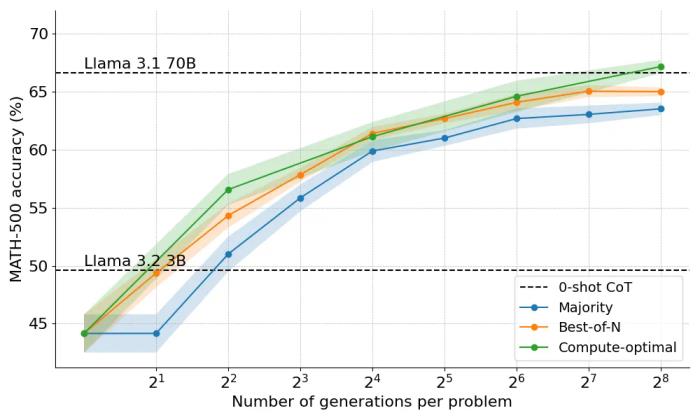
接下來該怎么辦?
對測試時計算擴展的探索揭示了利用基于搜索的方法的潛力和挑戰。展望未來,本文提出了幾個令人興奮的方向:
強驗證器:強驗證器在提高性能方面發揮著關鍵作用,提高驗證器的穩健性和通用性對于推進這些方法至關重要;自我驗證:最終目標是實現自我驗證,即模型可以自主驗證自己的輸出。這種方法似乎是 o1 等模型正在做的事情,但在實踐中仍然難以實現。與標準監督微調 (SFT) 不同,自我驗證需要更細致的策略;將思維融入過程:在生成過程中融入明確的中間步驟或思維可以進一步增強推理和決策能力。通過將結構化推理融入搜索過程,可以在復雜任務上實現更好的表現;搜索作為數據生成工具:該方法還可以充當強大的數據生成過程,創建高質量的訓練數據集。例如,根據搜索產生的正確軌跡對 Llama 1B 等模型進行微調可以帶來顯著的收益。這種基于策略的方法類似于 ReST 或 V-StaR 等技術,但具有搜索的額外優勢,為迭代改進提供了一個有希望的方向;調用更多的 PRM:PRM 相對較少,限制了其更廣泛的應用。為不同領域開發和共享更多 PRM 是社區可以做出重大貢獻的關鍵領域。原文鏈接:https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
