

 新火種
2024-12-17
新火種
2024-12-17 


國產全AI游戲來了一段文字、一張圖就能生成模擬開放世界游戲視頻
距離普通人憑想法就能做出游戲的時代,又近了一步。
AI 游戲生成天花板今年以來不斷突破,就在昨天,國產游戲 AI 團隊也加入卷出了新高度。
巨人網絡發布了 " 千影 QianYing" 有聲游戲生成大模型,其中包括游戲視頻生成大模型 YingGame、視頻配音大模型 YingSound。
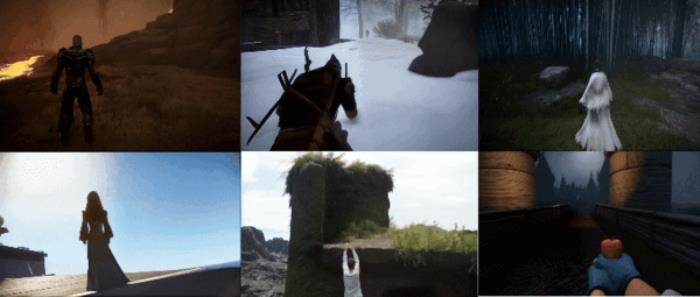
先來感受一段 1 分 26 秒的生成樣片:
用一段文字、一張圖,就能生成模擬開放世界游戲的視頻,并且有聲、可交互,可操控角色的多種動作。
面向開放世界游戲,無需游戲引擎
概括來說,YingGame 是一個面向開放世界游戲的視頻生成大模型,研究團隊來自巨人網絡 AI Lab、清華大學 SATLab,首次實現角色多樣動作的交互控制、自定義游戲角色,同時具備更好的游戲物理仿真特性。
精確的物理規律仿真
從生成的視頻中看,無論是汽車碰撞、火焰燃燒這類大場面,還是水中慢走、障礙物自動繞行這種人物行進,都表現出了出色的遵循物理規律能力。

多樣動作控制
交互對游戲至關重要,YingGame 能夠理解用戶的輸入交互,包括文本、圖像或鼠標、鍵盤按鍵等操作信號,從而讓用戶能夠操控游戲角色的多樣動作。
視頻中展示了角色在開槍、變身、施法、使用道具、攀爬、匍匐、跑跳等肢體動作的交互,相比同類模型更加豐富、絲滑。
角色個性化與精細主體控制
YingGame 還支持輸入一張角色圖片,實現角色自定義生成,同時對角色主體實現精細化控制,從過去的 AI 捏臉跨越到現在的 AI 捏人。

第一人稱視角
此外,還看到模型生成的第一人稱視角的游戲畫面,不得不說,這個視角有很足的游戲沉浸感。

怎么實現的?
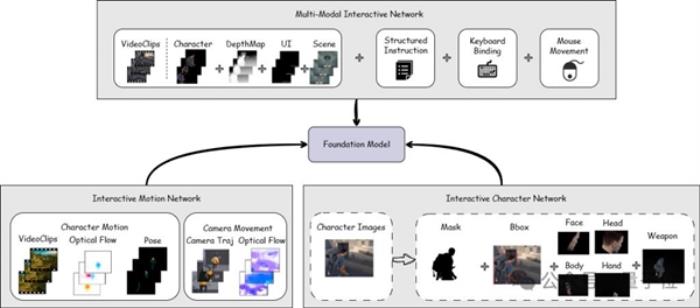
從技術上看,YingGame 通過融合跨模態特征、細粒度角色表征、運動增強與多階段訓練策略,以及所構建的高效、高質量游戲視頻訓練數據生產管線,使得生成內容具備可交互能力的多樣動作控制、角色自定義與精細主體控制、復雜運動與動作連續性等特性。
在交互性實現上,YingGame 結合了多個 Interactive Network 模塊:理解用戶輸入的多模態交互方式,實現多樣動作控制的多模態交互網絡 — MMIN ( Multi-Modal Interactive Network ) ;實現復雜與連續角色動作生成的動作網絡 — IMN ( Interactive Motion Network ) ;自定義角色生成與提高角色生成質量的角色網絡 — ICN ( Interactive Character Network ) 。
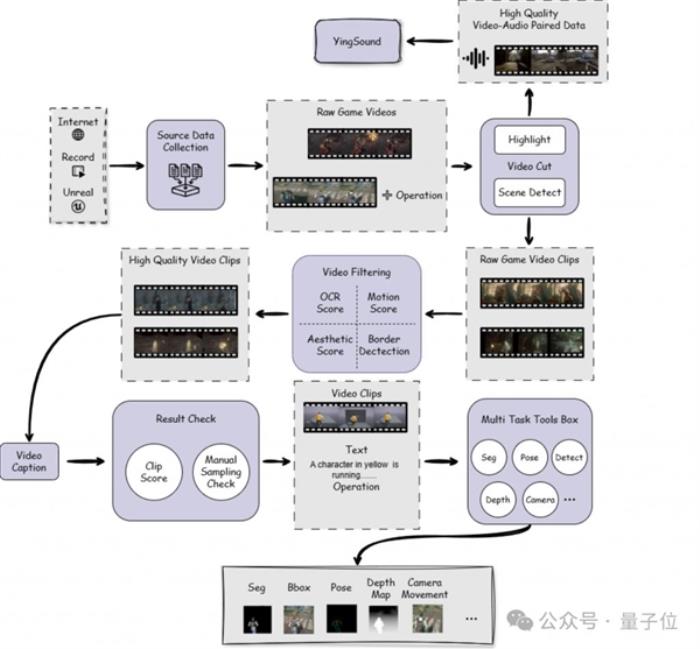
此外,為實現高質量訓練數據構建,巨人 AI 團隊設計了一條高效的游戲視頻數據處理管線:
基于場景與高光產出高質量視頻片段,其中對高光視頻片段進行音頻信息提取,作為 V2A 訓練集;
基于運動得分、美學評分等進行視頻過濾;
vLLM-based video caption 流程,并對結果進行 clip score 文本視頻對齊評分過濾;
多任務數據處理,如分割、主體檢測、姿勢估計、深度估計、相機運動估計等。
讓 AI 游戲進入有聲時代
除了 YingGame 之外,巨人還發布了針對視頻配音場景的多模態音效生成大模型 YingSound。
這是在此之前 AI 游戲生成領域沒有實現的,而 " 聲音 " 是游戲的基本要素。
YingSound 由巨人網絡 AI Lab、西工大 ASLP Lab 和浙江大學等聯合研發,它最重要的技能是:給無聲視頻配音效,實現音畫同步。
直接聽聽 YingSound 生成的效果:
YingSound 有超強的時間對齊和視頻語義理解能力,支持多種類型的高精細度音效生成,并且具備多樣化應用場景泛化能力,包括游戲視頻、動漫視頻、真實世界視頻、AI 生成視頻等。
理解各種視頻畫面能力一絕
來一段游戲的配音示例,通過演示視頻可以清晰看到,這個模型能夠精確地生成與場景高度匹配的音效,包括開鏡、炮轟、射擊等聲音,完美還原坦克進攻與士兵防守射擊的聲音,創造了沉浸式的游戲體驗。
△視頻源自 《戰地游戲》錄屏
在動漫場景中,模型展示了對復雜劇情的理解能力。例如,在一段鳥兒互相扔蛋的動畫中,模型生成了從驚訝到扔蛋、蛋飛行軌跡、接住蛋等一系列卡點且高度符合視頻內容的音效。
△視頻源自 動畫《Boom》片段
再來看看以下小球快速移動的畫面,模型生成的聲音能夠精準匹配畫面的動態變化,并針對小球不同狀態生成相應的場景音效,充分展現了其對動畫內容的深度理解。
△視頻源自 3D 動畫短片《The Marble》片段
在真實世界場景中,通過一段激烈的乒乓球對戰視頻,模型能夠精準地生成每次擊球所產生的音效,甚至還生成了球員跑動時鞋底與地面摩擦的聲音,這充分展現 YingSound 對視頻整體語義的深刻理解和出色的音效生成能力。
△視頻源自 乒乓球比賽測評結果領先
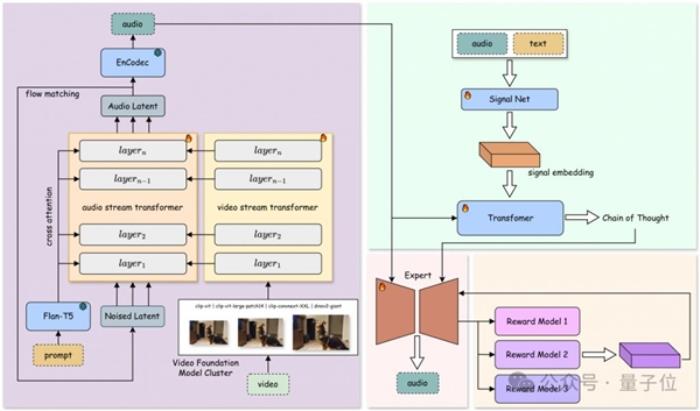
研究團隊公開了 YingSound 的兩個核心模塊:基于 DiT 的 Flow-Matching 構建的音效生成模塊,以及多模態思維鏈(Multi-modal CoT)控制模塊,為音效生成提供精準支持。
在音效生成模塊中,團隊基于 DiT 的 Flow-Matching 框架,提出了創新的音頻 - 視覺融合結構(Audio-Vision Aggregator, AVA)。該模塊通過動態融合高分辨率視覺與音頻特征,確保跨模態對齊效果。通過多階段訓練策略,逐步從 T2A 過渡到 V2A,并采用不同數據配比訓練,使模型具備從文本、視頻或二者結合生成高質量音效的能力。
同時,團隊設計了多模態視頻 - 音頻鏈式思維結構(Multi-modal CoT),結合強化學習實現對少樣本情況下音效生成的精細控制,可廣泛適用于短視頻、動漫及游戲等配音場景。
團隊精心構建了符合行業標準的 V2A(video-to-audio)數據集,覆蓋了電影、游戲、廣告等多場景、多時長的音視頻內容。為確保數據質量,研究團隊還設計了一套完善的數據處理流程,涵蓋數據收集、標注、過濾和剪輯。針對不同視頻類型的復雜性與差異性,團隊基于多模態大語言模型(MLLMs)及人工標注,完成時間戳和聲音事件的高質量標注。同時,通過嚴格篩選,過濾掉背景音樂干擾及音視頻不同步的內容,最終生成符合行業標準要求的訓練數據,為后續研究與開發提供了堅實基礎。
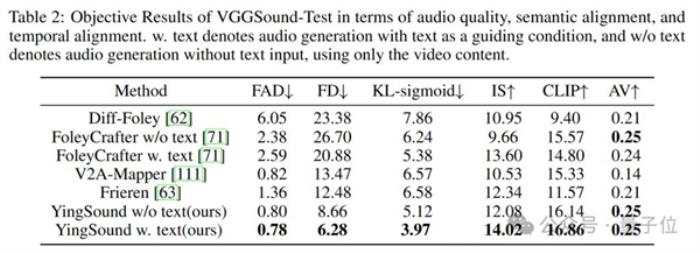
通過客觀指標測評可以看出,YingSound 大模型在整體效果、時間對齊和視頻語義理解等客觀測評上均達到業界領先水平。
長期來看,視頻生成技術因其展現出的取代游戲引擎的潛力,勢必會對游戲行業帶來顛覆式創新。
通過文字描述就能創作一個游戲,不再是異想天開。這個領域的發展速度之快超乎想象,AI 將帶來游戲創作平權,未來游戲創作的唯一限制可能只是創作者們的想象力。
今年年初,史玉柱談到巨人網絡在探索打造一個 AI 游戲孵化平臺,降低做游戲的門檻,讓普通人也能做游戲。這不,年底就交了第一份 " 作業 ",期待他們在 AI 游戲賽道的下一步規劃。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
